01
Efficient Face Image Deblurring via Robust Face Salient Landmark Detection
1.Novelty: incorporate face landmark detection with image deblurring
2.three main components:
robust face landmark detector;
salient contour detection;
blind image deblurring.
3.Train Robust Face Landmark Detector:
using Ensemble Regression Forests Landmark Detection;
the goal is to achieve a series of regression function which makes the closest landmark prediction to the ground-truth.
the detector is training on blurred face images
4.salient contour detection:
- the main face contours can be obtained by applying the trained detector on the test image
5.blind image deblurring:
- recover the latent sharp image with the guide of the salient edges
02
A Comprehensive Performance Evaluation of Deformable Face Tracking "In-the-Wild"
1.Novelty: perform the first thorough evaluation of state-of-the-art deformable face tracking pipelines using the recently introduced 300VW benchmark.
2.organizations:
present a survey of the current literature on both rigid and deformable face tracking
-
describe the state-of-the-art methods in the following three domains:
face detection
model free tracking
facial landmark localisation
03
Facial Landmark Detection: a Literature Survey
1.the facial landmark detection algorithms are classfied into three major categories:
holistic methods
Constrained Local Model (CLM) methods
-
regression-based methods
- deep learning based methods
2.Holistic methods
These methods explicitly leverage the holistic facial appearance information and the global facial shape patterns.
(1) Classic holistic method: Active Appearance Model(AAM):
-
During model construction: AAM builds the global facial shape model and the holistic facial appearance model sequentially based on PCA
- construction process: first learn shape variations, then appearance variations, showed in fig. 1

fig. 1
During detection: AAM identifies the landmark locations by fitting the learned appearance and shape models to the testing images
-
The goal of AAM is to find the shape and appearance coefficients and as well as the affine transformation that best fit the testing image.
This can be formulated by minimizing the distance between the reconstructed images and the shape normalized testing image .
Denote the error image as , then
(2) Methods to solving equation 2:
-
analytic fitting method: more accurate, but more difficult
- formulate AAM fitting problem as a nonlinear optimization problem and solve it analytically (solved with gradient descent algorithm with explicit calculation of the Hessian and Jocobian matrices)
-
learning-based fitting method: generally fast but may not be accurate
learn to predict the shape and appearance coefficients from the image appearances (use constant linear or nonlinear regression functions to approximate the steepest descent direction)
-
can be classified into linear regression fitting methods, nonlinear regression fitting methods, and other learning-based fitting methods
-
linear regression fitting methods:
assume there is linear relationship between model coefficient updates and the error image or image features
-
-
nonlinear regression fitting methods:
use nonlinear models to learn the relationship among the image features and the model coefficient updates
-
other learning-based fitting methods:
method 1: improve the feature representations (AAM model has limited generalization ability and it has difficulty fitting the unseen face variations (illumination, partial occlusion, etc))
method 2: utilize ensemble AAM models (cons of a single AAM model: inherently assumes linearity in face shape and appearance variation)
3.Constrained Local Model methods (CLM)
These methods use global facial shape patterns and the independent local appearance information around each landmark.
Two major components in CLMs:
local appearance model
face shape models
(1) Local appearance model:
further categorized into classifier-based local appearance model and regression-based local appearance model
-
classifier-based local appearance method:
train binary classifier to distinguish the positive patches that are centered at the ground truth locations and the negative patches that are far away from the ground truth locations
-
regression-based local appearance model:
use regression model to calculate the variance between the pixel location and the corresponding landmark location
(2) Face shape model:
captures the spatial relationships among facial landmarks.
(3) Once we have the local appearance models and the face shape models, we could use CLMs to combine them for detction.
4.Regression-based methods
Directly learn the mapping from image apperance to the landmark locations. These methods don't explicitly build any global face shape model. Instead, the face shape constraints may be implicitly embedded.
categories:
direct regression methods
cascaded regression methods
deep-learning based regression models
(1) Direct regression methods :
Learn the direct mapping from the image appearance to the facial landmark locations without any initialization of landmark locations.
(2) Cascaded regression methods :
Start from an initial landmark locations (e.g. mean face), and gradually update the landmark locations across stages with different regression functions learned for different stages.
(3) Deep learning based methods :
The deep learning methods (mainly CNN) mostly follow the two frameworks: global direct regression framework and cascaded regression framework. They can be classified into two methods: pure-learning methods and hybrid methods.
-
Pure-learning methods :
Use powerful CNN models to directly predict the landmark locations from facial images.
-
paper [91]: predicts five facial key points in a cascaded manner : (showed in fig. 2)
(i) In the first level, apply a CNN model with four convolution layers to predict the landmark locations;
(ii) Then, several shallow networks refine each individual point locally.
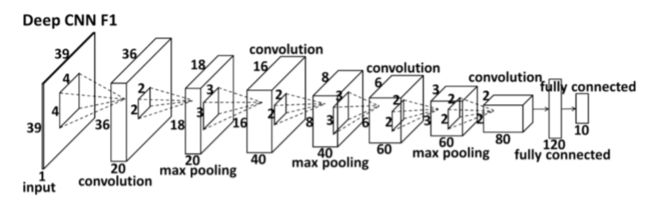 2.PNG
2.PNG -
-
Two directions in improving paper [91] :
use multi-task learning
improve the cascaded procedure :
e.g.1. replace the original cascade structure with cascaded CNN model. In this way, more key points can be predicted.
e.g.2. use deep auto-encoder model to perform the same cascaded landmark search.
e.g.3. use RNN to replace the cascade stage.
-
Hybrid deep methods :
Combine the CNN with 3D vision. By predicting 3D shape deformable model coefficients and the head poses to determine the 2D landmark locations through the computer vision projection model.
The models for facial landmark detection usually contain 4 convolutional layers and 1 fully connected layer.
It is still an open question whether adding more data would improve the performances of facial landmark detection (in deep learning methods).
5.Facial landmark detection "in-the-wild"
One way to handle large head poses: train pose dependent models.