【论文阅读笔记】(2015 ICML)Unsupervised Learning of Video Representations using LSTMs
Unsupervised Learning of Video Representations using LSTMs
(2015 ICML)
Nitish Srivastava, Elman Mansimov, Ruslan Salakhutdinov
Notes
Contributions
- Our model uses an encoder LSTM to map an input sequence into a fixed length representation. This representation is decoded using single or multiple decoder LSTMs to perform different tasks, such as reconstructing the input sequence, or predicting the future sequence.
- We experiment with two kinds of input sequences – patches of image pixels and high-level representations (“percepts”) of video frames extracted using a pretrained convolutional net.
- We explore different design choices such as whether the decoder LSTMs should condition on the generated output.
- We analyze the outputs of the model qualitatively to see how well the model can extrapolate the learned video representation into the future and into the past. We further evaluate the representations by finetuning them for a supervised learning problem – human action recognition on the UCF-101 and HMDB-51 datasets. We show that the representations help improve classification accuracy, especially when there are only few training examples. Even models pretrained on unrelated datasets (300 hours of YouTube videos) can help action recognition performance.
Method
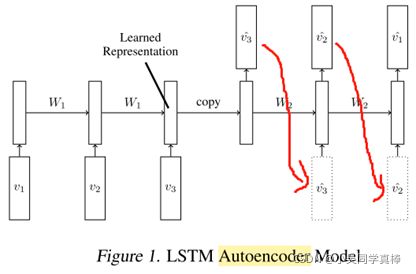
LSTM Autoencoder Model. This model consists of two Recurrent Neural Nets, the encoder LSTM and the decoder LSTM as shown in Fig. 1. The input to the model is a sequence of vectors (image patches or features). The encoder LSTM reads in this sequence. After the last input has been read, the cell state and output state of the encoder are copied over to the decoder LSTM. The decoder outputs a prediction for the target sequence. The target sequence is same as the input sequence, but in reverse order. The decoder can be conditional or unconditioned. A conditional decoder receives the last generated output frame as input, i.e., the dotted boxes in Fig. 1 are present. An unconditioned decoder does not receive that input.
LSTM Future Predictor Model. The design of the Future Predictor Model is same as that of the Autoencoder Model, except that the de- coder LSTM in this case predicts frames of the video that come just after the input sequence (Fig. 2). This model, on the other hand, predicts a long sequence into the future. Here again we consider two variants of the decoder – conditional and unconditioned.

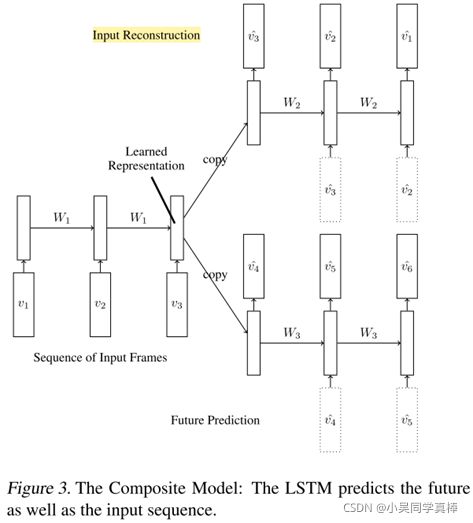
A Composite Model. The two tasks – reconstructing the input and predicting the future can be combined to create a composite model as shown in Fig. 3. Here the encoder LSTM is asked to come up with a state from which we can both predict the next few frames as well as reconstruct the input.
Results
First, they construct a Moving MNIST dataset:
- Each video was 20 frames long
- consisted of 2 digits moving inside
- 64 × 64 patch
- The digits were chosen randomly from the training set of MNIST
- placed initially at random locations inside the patch
- Each digit was assigned a velocity whose direction was chosen uniformly randomly on a unit circle and whose magnitude was also chosen uniformly at random over a fixed range.
- The digits bounced-off the edges of the 64 × 64 frame and overlapped if they were at the same location.
The reason for working with this dataset is that it is infinite in size and can be generated quickly on the fly.

Visualization and Qualitative Analysis: We can see that
- adding depth helps the model make better predictions.
- Next, we changed the future predictor by making it conditional. We can see that this model makes even better predictions.

Visualization and Qualitative Analysis: the reconstructions obtained from a two layer Composite model with 2048 units. We found that
- the future predictions quickly blur out but the input reconstructions look better.
- We then trained a bigger model with 4096 units. Even in this case, the future blurred out quickly. However, the reconstructions look sharper.
- We believe that models that look at bigger contexts and use more powerful stochastic decoders are required to get better future predictions.
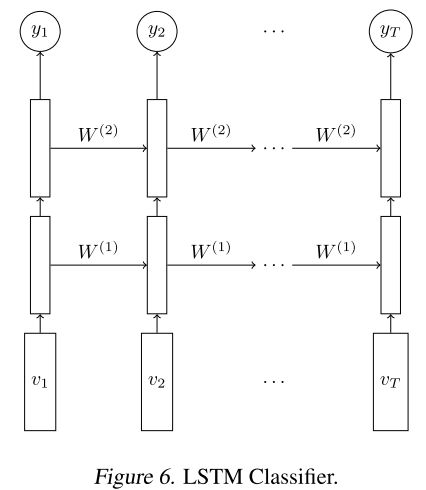
Action Recognition on UCF-101/HMDB-51. We used a two layer Composite Model with 2048 hid- den units with no conditioning on either decoders. Then, we initialize an LSTM classifier with the weights learned by the encoder LSTM from this model. The model is shown in Fig. 6. The output from each LSTM goes into a softmax classifier that makes a pre- diction about the action being performed at each time step. At test time, the predictions made at each time step are averaged. To get a prediction for the entire video, we average the predictions from all 16 frame blocks in the video with a stride of 8 frames. The baseline for comparing these models is an identical LSTM classifier but with randomly initialized weights. All classifiers used dropout regularization

Fig. 7 compares three models - single frame classifier, baseline LSTM classifier and the LSTM classifier initialized with weights from the Composite Model. We can see that
- for the case of very few training examples, unsupervised learning gives a substantial improvement.
- As the size of the labelled dataset grows, the improvement becomes smaller.

We further ran similar experiments on the optical flow percepts extracted from the UCF-101 dataset. A temporal stream convolutional net, similar to the one proposed by Simonyan & Zisserman (2014b), was trained on single frame optical flows as well as on stacks of 10 optical flows.

Comparison of Different Model Variants. Future prediction results are summarized in Table 2. For MNIST we compute the cross entropy of the predictions with respect to the ground truth. For natural image patches, we compute the squared loss. We see that
- the Composite Model always does a better job of predicting the future compared to the Future Predictor. This indicates that having the autoencoder along with the future predictor to force the model to remember more about the inputs actually helps predict the future better.
- Next, we compare each model with its conditional variant. Here, we find that the conditional models perform slightly better
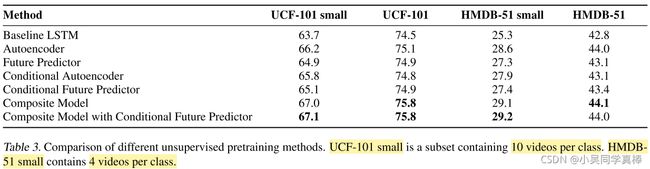
The performance on action recognition achieved by finetuning different unsupervised learning models is summarized in Table 3. We find that
- all unsupervised models improve over the baseline LSTM which is itself well-regularized using dropout.
- The Autoencoder model seems to perform consistently better than the Future Predictor.
- The Composite model, which combines the two, does better than either one alone.
- Conditioning on the generated inputs does not seem to give a clear advantage over not doing so. The Composite Model with a conditional future predictor works the best, although its performance is almost same as that of the Composite Model without conditioning.
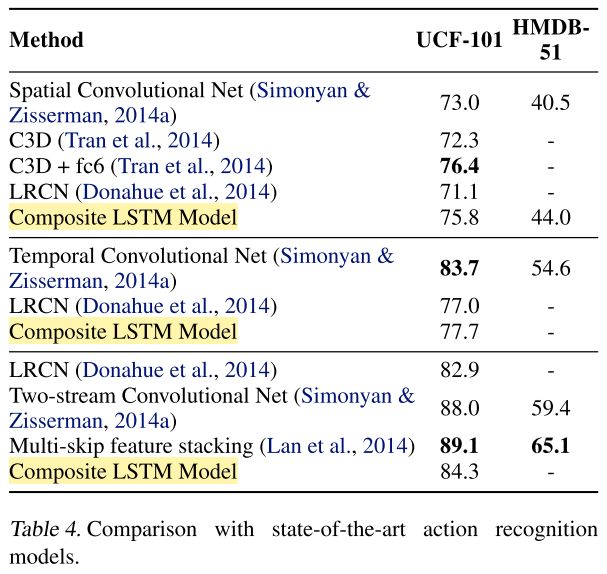
Comparison with Action Recognition Benchmarks. The table is divided into three sets. The first set compares models that use only RGB data (single or multiple frames). The second set compares models that use explicitly computed flow features only. Models in the third set use both.
- On RGB data, our model performs at par with the best deep models. When the C3D features are concatenated with fc6 percepts, they do slightly better than our model.
- The improvement for flow features over using a randomly initialized LSTM network is quite small. We believe this is partly due to the fact that the flow percepts already capture a lot of the motion information that the LSTM would otherwise discover. Another contributing factor is that the temporal stream convolutional net that is used to extract flow percepts overfits very readily (in the sense that it gets almost zero training error but much higher test error) in spite of strong regularization. Therefore the statistics of the percepts might be different between the training and test sets.
- We believe further improvements can be made by running the model over different patch locations and mirroring the patches.
- Also, our model can be applied deeper inside the conv net instead of just at the top-level.