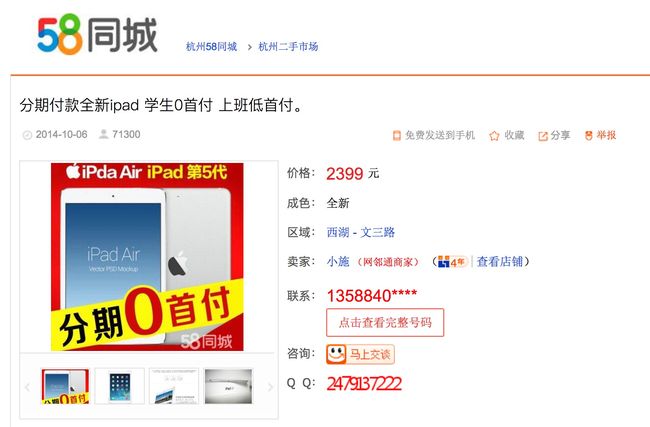
上图是我们要爬取的页面,首先把标题、发布时间、价格、区域这几个比较容易爬取的信息爬下来,代码如下。
from bs4 import BeautifulSoup
import requests
url = 'http://hz.58.com/pingbandiannao/19523317368970x.shtml'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
title = soup.title.text
price = soup.select('span.price')
date = soup.select('li.time')
area = soup.select('span.c_25d')
data = {
'title':title,
'price':price[0].text,
'date':date[0].text,
'area':list(area[0].stripped_strings)
}
print(data)
这里说几个和之前爬虫不太一样的地方
(1)title直接用soup.title.text是因为这个页面中商品的标题其实就是html中的title标签中的内容,如图。

(2)筛选所需信息时不必使用复杂的zip()函数。首先,要知道select()筛选出来的结果是一个列表,之前使用zip()函数加for循环是因为我们当时列表中含有多个元素,但是这里筛选出来的是单一元素,所以直接使用list[0]筛选即可得到结果,不需要用到循环。
然后将这些代码封装进一个函数当中,代码如下。
from bs4 import BeautifulSoup
import requests
url = 'http://hz.58.com/pingbandiannao/19523317368970x.shtml'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
def get_item_info(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
data = {
'title':soup.title.text,
'price':soup.select('span.price')[0].text,
'date':soup.select('li.time')[0].text,
'area':list(soup.select('span.c_25d')[0].stripped_strings)
}
print(data)
get_item_info(url)
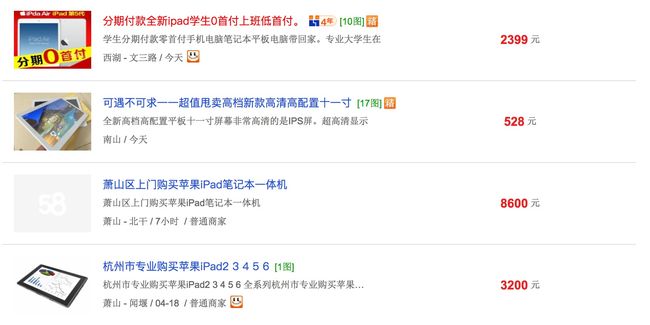
接下来要做的是创建一个函数,用来获取上图一个列表页中所有进入详情页的url。
def get_urls_from(who_sells=1):
urls = []
list_view = 'http://hz.58.com/pbdn/{}/'.format(str(who_sells))
wb_data = requests.get(list_view)
soup = BeautifulSoup(wb_data.text,'lxml')
for link in soup.select('td.t a.t'):
urls.append(link.get('href').split('?')[0])
print(urls)
get_urls_from()
首先,这里存在着两个分类,分别是个人和商家,下面观察两个分类的url有什么不同。
个人:http://hz.58.com/pbdn/0/
商家:http://hz.58.com/pbdn/1/
很明显,在url的末尾用0和1分别来表示个人和商家,所以在写函数时把who_sells=1作为了函数的默认参数,如果要显示个人的url,在调用函数时传入0即可get_urls_from(0)。
现在要处理一个比较麻烦的数据,那就是浏览量,因为浏览量是由js控制的,所以不能直接获取它的id然后释放信息,这样做返回是0,并不是我们想要的数据。所以我们需要通过浏览器工具来获得它请求的URL,如图。
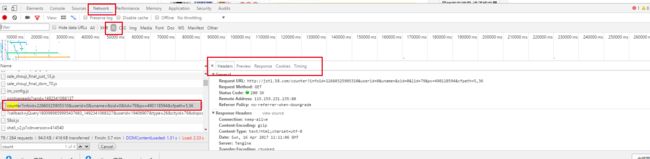

可以看到在Preview中最后一个total=154279就是我们浏览量,OK,获得了它的Request URL之后我们就可以用一个具体的函数来实现浏览量的爬取,代码如下。
def get_views_from(url):
id = url.split('/')[-1].strip('x.shtml')
api = 'http://jst1.58.com/counter?infoid={}'.format(id)
headers = {"Referer": url}
js = requests.get(api,headers=headers)
views = js.text.split('=')[-1]
print(views)
每个商品的url中都含有唯一的id,通过split()方法分割获取id,然后用format()方法将获取的id插入到Request URL中。
这里还有一点需要注意,添加头部字段
headers = {"Referer": url}
Referer可返回当前文档的 URL,否则向指定的 url 请求,无法获得浏览量数据。
浏览量成功爬取之后,我们要获取的目标信息就都完成了,最后我们将这些函数整合一下,一次性的获得我们想要的结果。
from bs4 import BeautifulSoup
import requests
import time
def get_urls_from(who_sells):
urls = []
list_view = 'http://hz.58.com/pbdn/{}/'.format(str(who_sells))
wb_data = requests.get(list_view)
time.sleep(1)
soup = BeautifulSoup(wb_data.text,'lxml')
for link in soup.select('td.t a.t'):
urls.append(link.get('href').split('?')[0])
return urls
def get_views_from(url):
id = url.split('/')[-1].strip('x.shtml')
api = 'http://jst1.58.com/counter?infoid={}'.format(id)
headers = {"Referer": url}
js = requests.get(api,headers=headers)
views = js.text.split('=')[-1]
return views
def get_item_info(who_sells=1):
urls = get_urls_from(who_sells)
for url in urls:
wb_data = requests.get(url)
time.sleep(1)
soup = BeautifulSoup(wb_data.text,'lxml')
area_data = soup.select('span.c_25d')
price = soup.select('span.price')
date = soup.select('li.time')
data = {
'title':soup.title.text,
'price':price[0].text if price else None,
'date':date[0].text if date else None,
'area':list(area_data[0].stripped_strings) if area_data else None,
'views':get_views_from(url),
'cate':'个人' if who_sells == 0 else '商家'
}
print(data)
get_item_info()