什么是架构
本章介绍搜索引擎的基本软件架构。架构本身没有公认的定义,但通常由软件组件、组件接口以及他们之间的关系组成。架构用于描述特定级别的系统。用于提供集成搜索和相关语言技术组件的标准的体系结构的示例是UIMA(非结构化信息管理体系结构).UIMA定义组件的接口,以简化将新技术添加到处理文本和其他非结构化数据的系统中的过程。
我们的搜索引擎架构用于提供系统重要组件及其之间关系的高级描述。 它不是代码级描述,尽管某些组件确实对应于Galago搜索引擎和其他系统中的软件模块。 我们在本章和整本书中使用这种架构来为特定技术的讨论提供背景。
架构旨在确保系统满足应用程序要求或目标。 搜索引擎的两个主要目标是:
- 有效性(质量):我们希望能够检索查询可能的最相关文档集。
- 效率(速度):我们希望尽快处理用户的查询。
我们也可能有更具体的目标,但通常这些目标属于有效性或效率(或两者)。 例如,我们想要搜索的文档集合可能正在发生变化; 确保搜索引擎立即对文档中的更改做出反应既是有效问题,也是效率问题。
搜索引擎的体系结构由这两个要求决定。 因为我们需要一个高效的系统,所以搜索引擎采用专为快速检索而优化的专用数据结构。 因为我们需要高质量的结果,所以搜索引擎会仔细处理文本并存储文本统计信息,以帮助提高结果的相关性。
我们在以下部分中讨论的许多组件已经使用了几十年,并且这种一般设计已被证明是有效和高效检索的竞争目标之间的有用折衷。 在后面的章节中,我们将更详细地讨论这些组件。
基本构建模块
搜索引擎组件支持两个主要功能,我们称之为索引过程(indexing process)和查询过程(query process)。索引过程构建了支持搜索的结构,查询过程使用这些结构和人员的查询来生成排序的文档列表。图2.1显示了索引过程的高级“构建块”。主要组件是文本获取(text acquisition),文本转换(text transformation)和索引创建(index creation)。

文本获取组件的任务是识别和提供将被搜索的文档。虽然在某些情况下这将涉及简单地使用现有集合,但文本获取将更需要通过爬网或扫描Web,企业内部网,桌面或其他信息源来构建集合。除了在索引过程中将文档传递给下一个组件外,文本获取组件还会创建一个文档数据存储,其中包含所有文档的文本和元数据(metadata)。元数据是关于不是文本内容的一部分的文档的信息,诸如文档类型(例如,电子邮件或网页),文档结构和诸如文档长度的其他特征。
电子文本转换组件将文档转换为索引术语(index term)或特征(feature)。顾名思义,索引术语是存储在索引中并用于搜索的文档部分。最简单的索引术语是一个单词,但不是每个单词都可以用于搜索。在机器学习领域中更多地使用“特征”来指代用于表示其内容的文本文档的一部分,其还描述了索引术语。其他类型的索引术语或特征的示例是网页中的短语,人名,日期和链接。索引术语有时简称为“术语”(term)。为文档集合索引的所有术语的集合称为索引词汇表(index vocabulary)。
索引创建组件获取文本转换组件的输出,并创建支持快速搜索的索引或数据结构。鉴于许多搜索应用程序中的文档数量很多,索引创建必须在时间和空间方面都很有效。获取新文档时,索引也必须能够有效更新。倒排索引(inverted indexes/inverted files)是迄今为止搜索引擎使用的最常见的索引形式。倒排索引非常简单,由每个术语对应了一个文档列表(包含该术语的文档)组成。它与文档文件相反,文档文件为每个文档列出了它们包含的索引术语。倒排索引的许多变体都是如此,所使用的索引的特定形式是搜索引擎最重要的方面之一。
图2.2显示了查询过程的构建块。主要组件是用户交互(user interaction),排名(ranking)和评估(evaluation)。

用户交互组件提供进行搜索的人和搜索引擎之间的接口。此组件的一项任务是接受用户的查询并将其转换为索引术语。另一项任务是从搜索引擎中获取排序的文档列表,并将其组织到显示给用户的结果中。例如,包括生成用于汇总文档的片段(snippets)。文档数据存储(document data store)是生成结果时使用的信息源之一。最后,该组件还提供了一系列用于查询查询的技术,以便更好地表示信息需求。
排名组件是搜索引擎的核心。它从用户交互组件获取变换后的查询,并使用基于检索模型的分数生成排序的文档列表。排名必须有效率,因为许多查询可能需要在短时间内处理并且有效,也必须质量高,因为排名的质量决定了搜索引擎是否实现了查找相关信息的目标。排名效率取决于索引,有效性取决于检索模型。
评估部分的任务是衡量和监测有效性和效率。其中一个重要部分是使用日志数据记录和分析用户行为。评估结果用于调整和改进排名组件。除了记录用户和系统数据之外,大多数评估组件不是在线搜索引擎的一部分。评估主要是离线活动,但它是任何搜索应用程序的关键部分。
详解组件
我们现在更详细地了解每个基本构建块的组件。 并非所有这些组件都将成为每个搜索引擎的一部分,但它们共同涵盖了我们认为对于广泛的搜索应用程序最重要的功能。
文本获取(text acquistion)
爬虫(crawler)
在许多应用程序中,爬虫组件主要负责识别和获取搜索引擎的文档。有许多不同类型的爬虫,但最常见的是一般的网络爬虫。 网络爬网程序旨在跟踪网页上的链接以发现和下载新页面。虽然这看起来很简单,但是在处理网络上大量新页面的同时,保证上一次爬虫访问过的页面修改后仍然保持新鲜,这是个巨大的挑战。网络爬虫可以限制在单个站点(例如大学),作为站点搜索的基础。聚焦(focused)或主题(topical)网络爬虫使用分类技术将访问的页面限制为可能与特定主题相关的页面。垂直或主题搜索应用程序会用到这种爬虫类型,例如提供对网页上的医疗信息的访问的搜索引擎。
对于企业搜索,爬虫适用于发现和更新与公司运营相关的所有文档和网页。企业文档爬虫跟随链接以发现外部和内部(即,限于公司内部网)页面,但也必须扫描公司和个人目录以识别电子邮件,文字处理文档,演示文稿,数据库记录和其他公司信息。文档爬虫也用于桌面搜索,但在这种情况下,只需要扫描用户的个人目录。
信息流(feeds)
文档流(document feeds)是用于访问实时文档流的机制。 例如,新闻流是新闻故事和更新的源源不断。 与必须发现新文档的爬虫相比,搜索引擎只需通过监视即可从信息流中获取新文档。 RSS是用于新闻,博客或视频等内容的网络订阅源的通用标准。 RSS“阅读器”用于订阅使用XML格式化的RSS。阅读器监视这些源并在到达时提供新内容。 广播和电视流(radio and television feeds)也用于一些搜索应用中,其中“文档”包含自动分段的音频和视频流,以及来自隐藏字幕或语音识别的相关文本。
转换(conversion)
由爬虫找到的或由信息流提供的文档很少以纯文本形式提供。相反,它们有各种格式,例如HTML,XML,Adobe PDF,Microso WordTM,MicrosoPowerPoint等。大多数搜索引擎要求将这些文档转换为一致的文本和元数据格式。在该转换中,与特定格式相关联的控制序列和非内容数据被移除或记录为元数据。对于HTML和XML,此过程的大部分内容可以描述为文本转换组件的一部分。对于其他格式,转换过程是准备文档以进行进一步处理的基本步骤。例如,PDF文档必须转换为文本。可以使用各种实用程序来执行此转换,具有不同程度的准确性。同样,可以使用实用程序将各种MicrosoOffice格式转换为文本。
另一个常见的转换问题来自文本在文档中的编码方式。 ASCII5是用于文本的通用标准单字节字符编码方案。 ASCII使用7或8位(扩展ASCII)来表示128或256个可能的字符。但是,某些语言(例如中文)比英语有更多的字符,并使用许多其他编码方案。 Unicode是一种标准编码方案,它使用16位(通常)来表示世界上大多数语言。任何处理不同语言文档的应用程序都必须确保在进一步处理之前将它们转换为一致的编码方案。
文档数据存储(document data store)
文档数据存储是用于管理大量文档以及与之关联的结构化数据的数据库。 电子文档内容通常以压缩形式存储以提高效率。 结构化数据由文档元数据和从文档中提取的其他信息组成,例如链接和锚文本(anchor text)(与链接相关联的文本)。 关系数据库系统可用于存储文档和元数据。 但是,某些应用程序使用更简单,更高效的存储系统来为非常大的文档存储提供非常快速的检索。
尽管原始文档可在Web上获得,但在企业数据库中,文档数据存储对于提供对一系列搜索引擎组件的文档内容的快速访问是必要的。 如果搜索引擎必须访问原始文档并重新处理它们,那么检索将花费太长时间。
文本转换(text transformation)
解析器(parser)
解析组件负责处理文档中的文本标记(text token)序列,以识别诸如标题,图形,链接和新闻头条之类的结构元素。对文本进行标记是此过程中重要的第一步。在许多情况下,标记与单词相同。文档和查询文本必须以相同的方式转换为标记,以便可以轻松比较它们。有许多决定可能影响检索,这使得标记化变得非常重要。例如,标记的简单定义可以是由空格分隔的字母数字字符串。但是,这并没有告诉我们如何处理大写字母,连字符和撇号等特殊字符。我们应该像“apple”一样对待“Apple”吗? “on-line”是两个字还是一个字? “O'Connor”中的撇号是否应该与“owner's”中的撇号相同?在某些语言中,标记化变得更加有趣。例如,中文没有像英语的空格符那样明显的单词分隔符。
文档结构通常由标记语言(如HTML或XML)指定。 文档解析器使用标记语言的语法知识来识别结构。
停用词(stopping)
停用词组件的任务是移除标记流中的常用词。最常见的单词通常是帮助形成句子结构的功能词,但对于文本所涵盖的主题的描述本身几乎没有贡献。例如“the”,“of”,“to”和“for”。因为它们如此常见,删除它们会大大减少索引的大小。根据用作排名基础的检索模型,删除这些单词通常不会影响搜索引擎的有效性,甚至可能会有所改善。尽管有这些潜在的优势,但很难确定要在停用词列表中包含多少个单词。研究中使用的一些禁用词列表包含数百个单词。使用这样的列表的问题在于,使用诸如“to be or not to be”或“down under”之类的查询进行搜索变得不可能。为避免这种情况,搜索应用程序在处理文档文本时可能会使用非常小的禁用词列表(可能只包含“the”),但随后会使用较长的列表来处理查询文本的默认值。
词干组件(stemming)
词干是另一个词级转换。词干组件(或词干分析器)的任务是对来自共同词干的单词进行分组。分组“fish”,“fishes”和“fishing”就是一个例子。通过用一个指定的单词替换组中的每个成员(例如,最短的,在这种情况下是“fish”),我们增加了查询和文档中使用的单词匹配的可能性。事实上,词干化通常会在排名效率方面产生微小的改进。与停用词组件相似,可以积极地,保守地或根本不进行干预。积极的词干可能会导致搜索问题。例如,查询“fishing”时得到的结果是不同种类的“fish”是不合适的。一些搜索应用程序使用更保守的词干,例如使用字母“s”简单地识别复数形式,或者它们在处理文档文本时可能不会产生干扰并且专注于向查询添加适当的词语变体。
有些语言,例如阿拉伯语,其形态比英语更复杂,因此词干更重要。 阿拉伯语中有效的词干成分对搜索效率产生巨大影响。 相比之下,其他语言(例如中文)几乎没有词语变异,而且对于这些语言来说,词干效果并不高效。
链接提取和分析(link extraction and analysis)
在文档解析期间,可以容易地识别和提取网页中的链接(link)和相应的锚文本(anchor text)。 提取意味着该信息被记录在文档数据存储(document data store)中,并且可以与一般文本内容分开索引。 网络搜索引擎通过链接分析算法广泛使用这些信息,如PageRank(Brin&Page,1998)。 链接分析为搜索引擎提供了受欢迎程度的评级,并在某种程度上为页面的权威性(换句话说,它的重要程度)提供了评级。 锚文本是Web链接的可单击文本,可用于增强链接指向的页面的文本内容。 这两个因素可以显着提高某些类型查询的Web搜索的有效性。
信息提取(information extraction)
信息提取用于识别比单个单词更复杂的索引术语。 这可以像粗体中的单词或标题中的单词一样简单,但通常可能需要大量额外的计算。 例如,提取诸如名词短语之类的句法特征需要某种形式的句法分析(synactic analysis)或词性标注(part-of-speech tagging)。 该领域的研究主要集中在提取具有特定语义内容的特征的技术,例如命名实体识别器(named entity recognizer),其可以可靠地识别诸如人名,公司名称,日期和位置之类的信息。
分类器(classifier)
分类器组件识别文档或文档部分的与类相关的元数据。 这涵盖了一系列通常单独描述的功能。 分类技术(classification)为文档分配预定义的类标签。 这些标签通常代表主题类别,例如“体育”,“政治”或“商业”。 其他类型分类的两个重要示例是:文档识别为垃圾邮件;识别文档的非内容部分,例如广告。 聚类技术(clustering)用于对没有预定义类别的相关文档进行分组,这些分组可以在排名或用户交互期间使用。
索引创建(Index Creation)
文档统计(document statistics)
文档统计组件的任务仅仅是收集和记录有关单词,功能和文档的统计信息。 排名组件使用此信息来计算文档的分数。 通常需要的数据类型是单个文档中索引术语出现次数(单词和更复杂的特征),索引术语出现的文档中的位置,文档组的出现次数(例如所有 标有“体育”或整个文件集的文件),以及以标记数量表示的文件长度(the lengths of documents in terms of the number of tokens)。 所需的实际数据由检索模型和相关的排序算法确定。 文档统计信息存储在查找表(lookup table)中,查找表是为快速检索而设计的数据结构。
权重(weighting)
索引术语权重反映了文档中单词的相对重要性,并用于计算排名分数。 权重的具体形式由检索模型确定。 加权组件使用文档统计信息计算权重,并将它们存储在查找表中。 权重可以作为查询过程的一部分进行计算,某些类型的权重需要有关查询的信息,但通过在索引过程中尽可能多地进行计算,可以提高查询过程的效率。
以前的检索模型中使用的最常见类型之一称为tf.idf加权。 这些权重有很多变化,但它们都是基于文档中索引词出现的频率或计数(术语频率或tf)和整个文档集合中索引词出现频率的组合( 逆文档频率,或idf)。 idf权重称为逆文档频率,因为它对非常少的文档中出现的术语赋予高权重。 idf的典型公式是log N / n,其中N是搜索引擎索引的文档总数,n是包含特定术语的文档数。
倒排
倒排组件是索引过程的核心。 其任务是将来自文本转换组件的文档 - 术语信息流更改为术语 - 文档信息,以创建倒排索引。 挑战在于有效地执行此操作,不仅对于最初创建倒排索引时的大量文档,而且还在使用消息流或爬的新文档更新索引。 倒排索引的格式是为快速查询处理而设计的,并且在某种程度上取决于所使用的排序算法。 索引也被压缩以进一步提高效率。
索引分发(index distribution)
索引分发组件跨多个计算机分发索引,并可能跨网络上的多个站点分发索引。 分发对于网络搜索引擎的高效性能至关重要。 通过分发文档子集的索引(文档分发 document distribution),索引和查询处理可以并行完成。 分配标记子集(标记分发 term distribution)的索引也可以支持并行处理查询。 复制(Replication)是一种分发形式,其中索引或索引部分的副本存储在多个站点中,以便通过减少通信延迟来提高查询处理效率。 点对点(P2P)搜索涉及一种不太有组织的分布形式,其中网络中的每个节点都维护着自己的索引和文档集合。
用户交互(user interaction)
查询输入(query input)
查询输入组件为查询语言提供接口和解析器(parser)。最简单的查询语言(例如在大多数Web搜索接口中使用的语言)只有少量的运算符。运算符是查询语言中的命令,用于指示应以特殊方式处理的文本。通常,运算符通过约束文档中的文本如何匹配查询中的文本来帮助阐明查询的含义。简单查询语言中的运算符的示例是使用引号来指示所包含的单词应该作为文档中的短语出现,而不是作为没有关系的单个单词。但是,典型的Web查询包含少量没有运算符的关键字。关键字(keyword)只是一个对指定查询主题很重要的单词。由于大多数网络搜索引擎的排名算法都是针对关键字查询而设计的,因此可能包含较低比例关键字的较长查询通常效果不佳。例如,查询“搜索引擎”的结果比查询“什么是搜索引擎中使用的典型实现技术和数据结构”的结果更好。搜索引擎设计面临的挑战之一是为一系列查询提供良好的结果,并为更具体的查询提供更好的结果。
对于希望对搜索结果拥有大量控制权的人或使用搜索引擎的应用程序,可以使用更复杂的查询语言。 与SQL查询语言(Elmasri&Navathe,2006)一样,这些查询语言不是为搜索应用程序的终端用户设计的。布尔查询语言(boolean query language)在信息检索方面有着悠久的历史。 这种语言的运算符包括布尔与(Boolean AND),布尔或(Boolean OR)和布尔非(Boolean NOT),以及某种形式的邻近运算符(proximity operator),它指定单词必须在特定距离内一起出现(通常以字数计)。 其他查询语言(包括这些以及其他按照概率框架(probabilistic framework)设计运算符)允许指定与文档结构和内容相关的特征。
查询转换(query transformation)
查询转换组件包括一系列的技术,这些技术被设计用来在排序之前和之后提高原始查询的效率。最简单的处理涉及文档文本中使用的一些相同的文本转换技术。必须对查询文本进行标记(tokening),过滤停用词(stopping)和词干分析(stemming),以此生成与文档术语(document term)可以比较的索引术语(index term)。
拼写检查(spell checking)和查询建议(query suggestion)是查询转换的2种技术,他们生成相似的输出。这2种技术会给用户的初始查询文本呈现可选项,用于纠正他的拼写错误或者补充更多的查询信息。这些技术通常利用从web应用收集的大量的查询日志(query log)。查询扩展(query expansion)技术也给查询建议或者增加额外的term,但是通常是基于文档中term出现的分析。这个分析会使用不同的信息来源,比如整个文档集合、被检索的文档或者用户电脑上的文档。相关性反馈(relevance feedback)是一个扩展查询的技术,他基于term在文档(被用户认为相关的文档)中的出现情况。
注:token是一系列attribute的组合,而term是其中一个attribute。以后遇到token和term不翻译
结果输出(results output)
结果输出组件负责把排序组件返回的已排序的文档进行展示。这个组件的任务包括生成用户汇总检索文件信息的snippets(片段),高亮重要的词和段落,把结果聚类来识别文档组,把合适的广告加到结果中。文档可能包含不同的语言,需要被翻译成同一种。
排序(ranking)
打分(scoring)
打分组件(别名query processing)使用基于检索模型的排序算法给每个文档打分。一些搜索引擎的设计者会声明他们使用的检索模型。但其他的设计者只会公开排序算法,而不会公开检索模型。排序算法使用的特征和权重,来自经验(基于测试和评估),与主题和用户相关;否则搜索引擎不能很好工作。
现在已经有了很多种不同的检索模型和导出排序算法的方法。很多模型的基本打分公式如下:
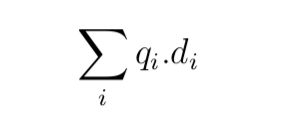
q i是第i个term的查询term权重,d i是文档term的权重。term权重基于特定的检索模型,但是跟tf-idf权重类似。第七章会讨论基于BM25和query likehood检索模型的排序算法。
打分一定要快,要在结果输出组件限定的时间内完成。这里会有性能调优的任务。
性能调优
性能调优涉及到排序算法和相关的索引的设计,目标是降低响应时间增加吞吐量。
两种打分方式:
term-at-a-time打分方式:通过查询term访问index,计算文档对这个term的贡献度,累积文档的贡献度,然后继续访问下一个索引
document-at-a-time打分方式:同时访问查询term涉及的所有index,通过移动指针找到文档所有的term计算文档的分数
优化的保证:
安全优化(safe optimization):保证跟优化前打分一样
非安全优化(unsafe optimization):不能保证跟优化前打分一样
需要根据实际情况评估优化对排序效果的影响。
分发(distribution)
索引可以分发,排序也可以。一个查询代理(query broker)负责把查询通过网络分发出去,并把排序结果合并。代理基于索引的分发来工作。缓存(caching)是另一种分发方式,索引甚至之前的排序结果都在本地内存中。如果一个查询或者索引term很火,那么缓存起来回来会节省很多时间。
评估(evaluation)
日志(logging)
记录用户的查询和反馈是最重要的事情之一,它可以用来提高搜索的质量和效率。查询日志可以用来做拼写检查,查询建议和查询缓存等。用户的点击、浏览时间等行为可以训练排序算法。
排序分析
使用日志数据或者相关性评价来衡量排序算法的效率。
性能分析
略