
注:本文主要参照:手把手 | 教你爬下100部电影数据:R语言网页爬取入门指南(http://mp.weixin.qq.com/s/mIL-p2q7Jp-dhkXkDIrdHQ)
一入爬虫深似海,从此复制是路人。
都说在这一行混,多多少少都要会点爬虫,毕竟自己动手丰衣足食,本文记录小鑫第一次练习爬虫的过程。仅供参考,欢迎各路朋友指点。(E-mail:[email protected])
文末有源代码及数据。
准备 | 必要的工具
chrome浏览器+SelectorGadget插件。
用来获得网页中某些部分的相关标签,若不懂HTML和CSS,强烈安利这个插件。懂HTML和CSS的话,略过,用不着我来教了。
安装插件之后,在网页的右上角就会出现图标,在使用的时候单机一下就可以。
点击之后,鼠标移动到网页上就会出现一系列的变化,再单机想要知道标签的地方,比如标题部分:
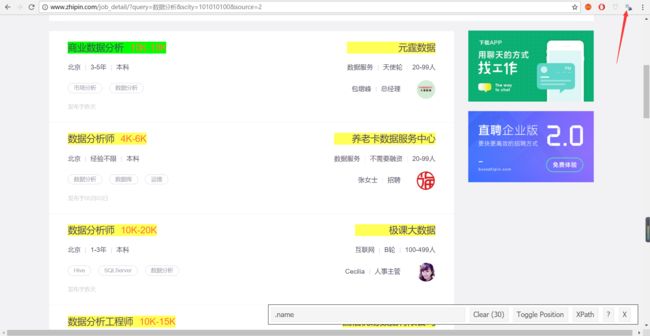
可以看到,虽然选中了标题,但同时公司名称和薪资也同样被选中了,想要取消选中公司名称很简单,单机一下公司名称所在的位置就可以了,如下图
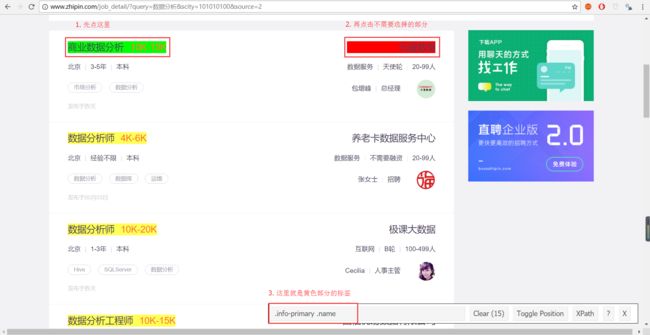
至于不选中薪资,在这里没法做到,不过没关系,在后面可以进行清理。
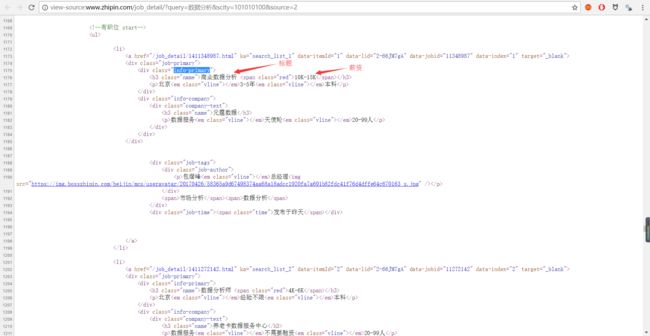
当然,也可以通过右键查看网页源代码或者右键审查,可以查看标签,这种方式显然需要一点HTML基础。
至于R的操作环境,推荐使用RStudio,没有原因,它就是非常好……
开始 | 准备爬取
网上有看到爬知乎、爬微博、爬智联招聘、爬拉勾网,各种网站的爬取方式略微不同,小鑫在找了几个招聘的网站之后,发现BOSS直聘的网址比较简单,页面源码也不复杂,因此,就从这里开始。
先加载需要的包:
library(xml2)
library(rvest)
首先,分析网址
小鑫搜索的是深圳的数据分析岗位,网址如下:
https://www.zhipin.com/job_detail/?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&scity=101280600&source=2
这里似乎发现不了规律,再点开下一页呢:https://www.zhipin.com/c101280600/h_101280600/?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=2&ka=page-2
其中个地方引起了我注意:page=2和ka=page-2,小鑫试了一下,只要改变这个数字,就能控制翻页,这个网站最多只能显示30页,每页15个。所以,不同页,除了数字不同之外,其他部分都是一模一样的,那就好办了,给出一个变量page,然后用for循环:
site1 <- "https://www.zhipin.com/c101280600/h_101280600/?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page="
site2 <- "&ka=page-"
page <- 1
for(page in 1:30){
site <- paste(site1,page,site2,page,sep="")
webpage <- read_html(site)
循…
环…
内…
容…
…
}
site1和site2控制着整个网址的固定部分,page控制网址的变动部分,从1循环到30。
循环中的第一个语句,用paste将site1、site2、page连接成一个完整的网址。
第二句:将网页信息保存到webpage这个变量里,以后的所有抓取动作,都是从这个变量里来的。
然后,确定抓取内容
这一步主要是回到网页中来:
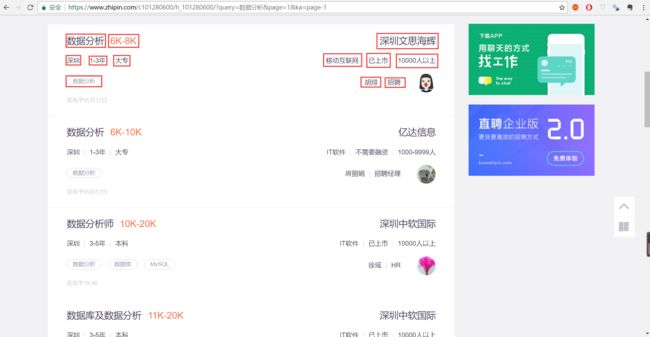
可以发现,在每条招聘信息里,可以爬取这些内容:标题、薪资、公司名、地点、经验要求、学历要求、行业、融资/上市情况、公司规模、关键词、联系人及其岗位。
不同的内容在不同的标签里面,这里仅仅拿部分内容举例说明,其他信息的爬取都是大同小异的,详见附件源码或联系小鑫(E-mail:[email protected])
值得一提的是,不同招聘信息的关键词数量不同,所以,我就单独把关键词作为另一项内容保存了起来,用于后面做词云。
OK | 开始爬取
先爬取标题和公司名称,用谷歌浏览器和插件,可得知标题和公司名称所在的标签分别是:.info-primary .name和.company-text .name,使用如下语句:
name1 <- html_nodes(webpage,'.info-primary .name')# 抓取标题
name2 <- html_nodes(webpage,'.company-text .name')# 抓取公司名称
查看name1和name2。
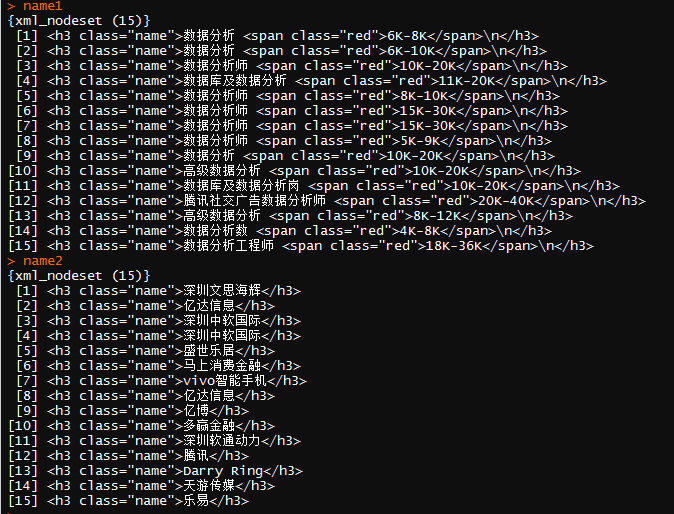
可以看出,已经爬取了正确的信息,只是需要删除那些标签和不需要的内容,接下来的思路就很简单了,使用gsub函数,将不必要的内容替换成空。
比如:< h3 class="name">、< span class="red">、< /span>\n这些标签。
name1 <- gsub("","",name1)
name1 <- gsub(" .*","",name1)
name1 <- gsub("\n
","",name1)
name1 <- gsub("","",name1)
titlename <- as.data.frame(name1)
name2 <- gsub("","",name2)
name2 <- gsub("
","",name2)
companyname <- as.data.frame(name2)
这个时候,再看一下数据内容:
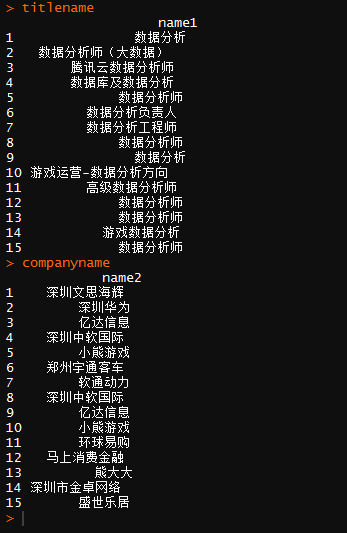
保存数据:
bossdata <- data.frame(companyname,titlename)
bossdata
可以看出,能完成到这一步,基本上算是完成了90%,后面的思路都是大同小异的,注意变换一下形式就OK了,但是还是有一个小问题,就是剩下的10%。
继续 | 最后一小步
然后就是抓取薪资,这一步也很简单,直接上代码:
# 抓取薪资
salary <- html_nodes(webpage,'.red')
salary <- gsub("","",salary)
salary <- gsub("","",salary)
bossdata <- cbind(bossdata,salary)
bossdata
问题出在了这一步:
# 抓取要求及公司信息
message <- html_nodes(webpage,'p')
message <- message[-1]
message <- gsub("","",message)
message <- gsub("",",",message)
message <- gsub("
","",message)
message <- gsub("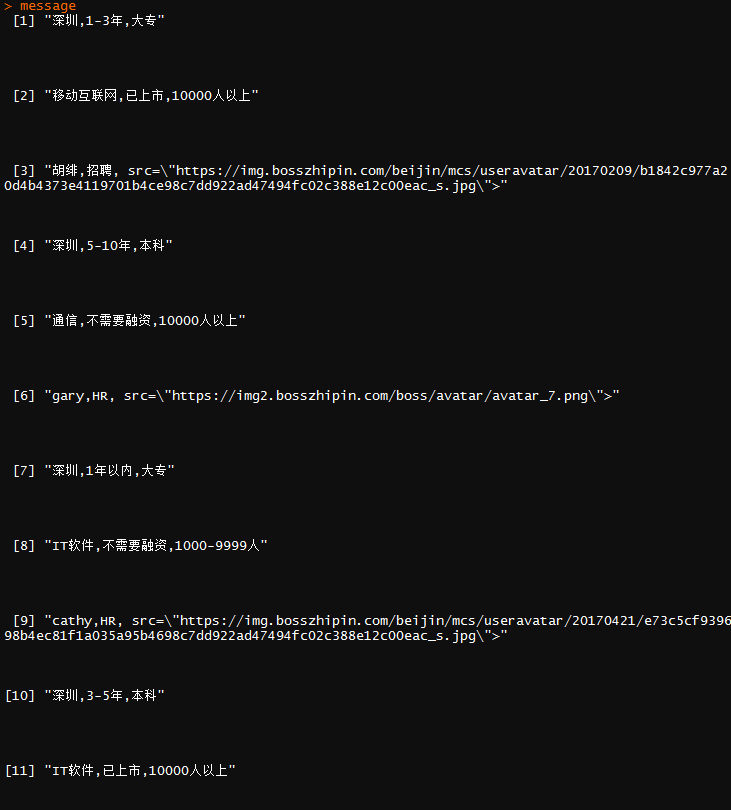
可以看得出来,问题就在于“地点、工作经验、学历”在同一个位置,“行业、融资/上市情况、公司规模”也在同一个位置,这样的情况下,就不能按照上面的方法来操作了,其实也不难,只要设置一个循环,重点就解决了。
# 先设置三个变量,分别读取message中的不同数据
xx <- c(1:as.numeric(length(message)/3))
yy <- c(1:as.numeric(length(message)/3))
zz <- c(1:as.numeric(length(message)/3))
# xx用来存放message中的地点、经验、学历要求
k1 <- 1
l1 <- 1
for(k1 in seq(1:(length(message)/3))){
xx[k1] <- message[l1]
l1 <- k1*3+1
}
xx
# 可以看出xx虽然提取正确了,但是还需要进一步处理
xx <- as.data.frame(xx)
xx <- apply(as.data.frame(xx),1,strsplit,",")
xx <- as.data.frame(xx)
xx[1,]
# 分别提取xx中的地点,经验,学历
place <- t(as.data.frame(xx[1,]))
experience <- t(as.data.frame(xx[2,]))
education <- t(as.data.frame(xx[3,]))
# 合并数据框
bdata <- data.frame(place,experience,education)
names(bdata) = c("place", "experience", "education")
bossdata <- data.frame(bossdata, bdata)
bossdata
后面需要提取行业、融资/上市情况、公司规模等信息,都是采用相同的方法,具体内容,可以查看附件代码。至此,最简单的一个爬虫就写好了。
一般来说,行业、融资/上市情况、公司规模这三个是在一起的,但是有两条信息,只有两个内容,如下图:
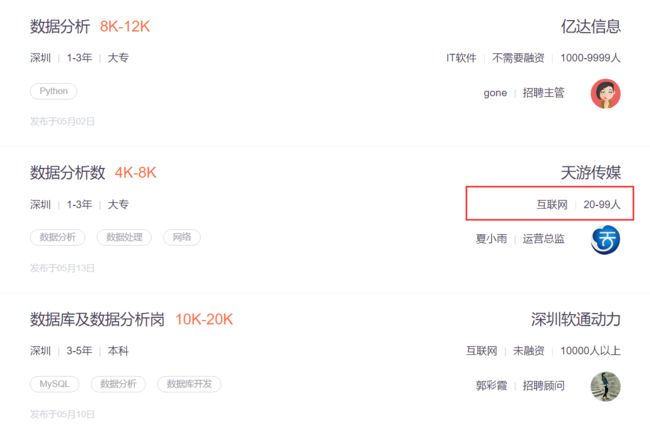
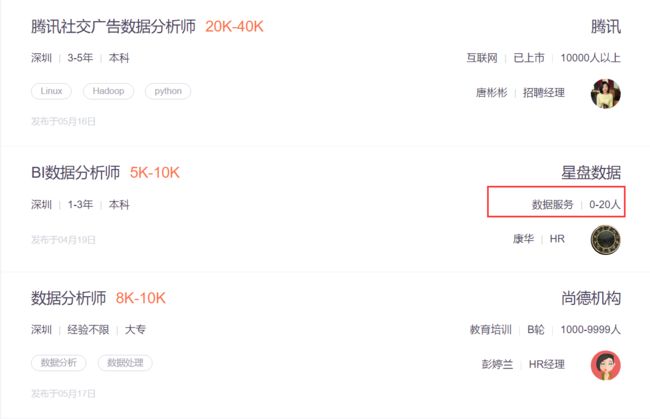
我的解决方法是:找到相应的位置,然后在那个地方填补一个缺失值NA,比如,在小鑫运行程序的时候,他们处在第一页的第十一和第十五条数据,因此,小鑫使用如下代码:
if(page == 1){
financing11 <- financing[11,]
financing15 <- financing[15,]
financing[11,] <- NA
financing[15,] <- NA
companysize[11,] <- financing11
companysize[15,] <- financing15
}
else {
print("Hello World")
}
但是这种方法有很大的弊端,小鑫在写这篇文章的时候,这两条信息又跑到了第二页第五条和第十三条。因此,第一行的代码就变成了page == 2,第二三行分别是:financing5 <- financing[5,]
financing13 <- financing[13,]
小鑫在想是不是可以让R自动识别他们的位置,然后填充NA,甚至于在以后出现第三条、第四条类似信息的时候,也能识别出空缺的位置,然后进行自动填补呢?
应该是可以的,不过小鑫现在才疏学浅,还没那个技术。待小鑫技术学成,再奉上文章。
【END】
源代码及爬取后数据
链接:http://pan.baidu.com/s/1jI5Lmke
密码:0cjv