一.环境说明
虚拟机:vmware 11
操作系统:Ubuntu 16.04
Hadoop版本:2.7.2
Zookeeper版本:3.4.9
二.节点部署说明

三.Hosts增加配置
sudo gedit /etc/hosts
wxzz-pc、wxzz-pc0、wxzz-pc1、wxzz-pc2均配置如下:
127.0.0.1 localhost 192.168.72.132 wxzz-pc 192.168.72.138 wxzz-pc0 192.168.72.135 wxzz-pc1 192.168.72.136 wxzz-pc2
四.zookeeper上配置
Zoo.cfg配置文件内容如下:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/zookeeper-3.4.9/tmp/dataDir dataLogDir=/opt/zookeeper-3.4.9/tmp/logs/ clientPort=2181 server.1=wxzz-pc:2182:2183 server.2=wxzz-pc0:2182:2183 server.3=wxzz-pc1:2182:2183
在/opt/zookeeper-3.4.9/tmp/dataDir下新建”myid”文件,wxzz-pc、wxzz-pc0、wxzz-pc1三台虚拟机中myid文件分别对应的内容为:1、2、3,也就是server.X=wxzz-pc:2182:2183,对应X的数值。
五.Hadoop配置
1.core-site.xml 配置
fs.defaultFS hdfs://myhadoop:8020 hadoop.tmp.dir /opt/hadoop-2.7.2/tmp/hadoop-${user.name} ha.zookeeper.quorum wxzz-pc:2181,wxzz-pc0:2181,wxzz-pc1:2181
2. hdfs-site.xml 配置
dfs.replication 2 dfs.block.size 10485760 hadoop.tmp.dir /opt/hadoop-2.7.2/tmp/hadoop-${user.name} dfs.namenode.name.dir ${hadoop.tmp.dir}/dfs/name dfs.datanode.data.dir ${hadoop.tmp.dir}/dfs/data dfs.permissions false dfs.permissions.enabled false dfs.webhdfs.enabled true dfs.nameservices myhadoop dfs.ha.namenodes.myhadoop nn1,nn2 dfs.namenode.rpc-address.myhadoop.nn1 wxzz-pc:8020 dfs.namenode.http-address.myhadoop.nn1 wxzz-pc:50070 dfs.namenode.rpc-address.myhadoop.nn2 wxzz-pc0:8020 dfs.namenode.http-address.myhadoop.nn2 wxzz-pc0:50070 dfs.namenode.servicerpc-address.myhadoop.nn1 wxzz-pc:53310 dfs.namenode.servicerpc-address.cluster1.nn2 wxzz-pc0:53310 dfs.ha.automatic-failover.enabled.cluster1 true dfs.namenode.shared.edits.dir qjournal://wxzz-pc:8485;wxzz-pc0:8485;wxzz-pc1:8485/myhadoop dfs.client.failover.proxy.provider.myhadoop org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.journalnode.edits.dir /opt/hadoop-2.7.2/journal dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /opt/hadoop-2.7.2/.ssh/id_rsa dfs.ha.fencing.ssh.connect-timeout 1000 dfs.namenode.handler.count 10 dfs.ha.automatic-failover.enabled.myhadoop true
3. mapred-site.xml 配置
mapreduce.framework.name yarn mapreduce.jobhistory.address 0.0.0.0:10020 mapreduce.jobhistory.webapp.address 0.0.0.0:19888
4.yarn-site.xml 配置
yarn.resourcemanager.ha.enabled true yarn.resourcemanager.cluster-id rm-id yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 wxzz-pc yarn.resourcemanager.hostname.rm2 wxzz-pc0 yarn.resourcemanager.zk-address wxzz-pc:2181,wxzz-pc0:2181,wxzz-pc1:2181 yarn.nodemanager.aux-services mapreduce_shuffle
六.服务启动
1.在各个Journal Node节点上,输入以下命令启动Journal Node
sbin/hadoop-daemon.sh start journalnode
2.在[nn1]上,进行格式化,并启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
3.在[nn2]上,同步[nn1]的元数据信息,并启动
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
经过以上3步,[nn1]和[nn2]均处在standby状态
4.[nn1]节点上,将其转换为active状态
bin/hdfs haadmin –transitionToActive --forcemanual nn1
5.在[nn1]上,启动所有datanode
sbin/hadoop-daemons.sh start datanode
6.在[nn1]上,启动yarn
sbin/start-yarn.sh
如果要关闭集群,在[nn1]上输入sbin/stop-all.sh即可。以后每次启动的时候,需要按照上面的步骤启动,不过不需要执行2 的格式化操作。
七.运行效果
管理界面:

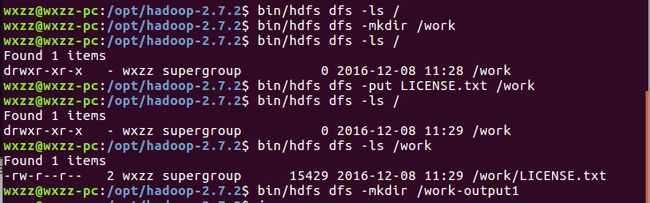
命令行效果:
1.[连载]《C#通讯(串口和网络)框架的设计与实现》
2.[开源]C#跨平台物联网通讯框架ServerSuperIO(SSIO)介绍
2.应用SuperIO(SIO)和开源跨平台物联网框架ServerSuperIO(SSIO)构建系统的整体方案
3.C#工业物联网和集成系统解决方案的技术路线(数据源、数据采集、数据上传与接收、ActiveMQ、Mongodb、WebApi、手机App)
5.ServerSuperIO开源地址:https://github.com/wxzz/ServerSuperIO
物联网&集成技术(.NET) QQ群:54256083