一个Python解释器
接下来的旅程——你需要下载好Python,Python解释器通常放在 /usr/local/bin/python3.7 ; 在Unix系统的bash中输入 where python3

在 Windows 机器上, Python 安装通常放在 C:\Python37 中,尽管你可以在运行安装程序时更改此设置。要将此目录添加到路径中,可以将以下命令键入 命令提示符窗口:
set path=%path%;C:\python37
把 /usr/local/bin 放到你 Unix shell 的搜索路径当中 , 这样就能键入命令 python3 ,进入交互模式(interactive mode),如下:

变量
变量就像一个容器,方便存储数据。常量也可以用于存储数据。根据名字可以区分两者的区别:常量保存数据不能更改,变量可以多次更改。
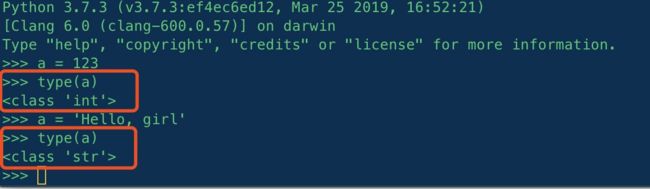
把计算机当做一栋房子,变量就像在这栋房子中的一间房间,拥有自己的地址(id)。变量名就像是房间号,房间的类型就像是变量的类型(type)。
>>> a = 'name' >>> id(a) 4564940088 >>> type(a) <class 'str'> >>>
Python是弱类型语言:
- 变量无须声明即可直接赋值:对一个不存在的变量赋值就相当于定义了一个新变量。
- 变量的数据类型可以动态改变:同一个变量可以一会儿被赋值为整数值,一会儿被赋值为字符串。
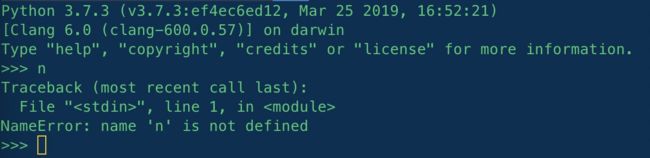
如果一个变量未定义(未赋值),试图使用它时会向你提示错误:
print函数输出变量
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
print() 的语法格式如上:
- *object 代表可以接受不同的对象、任意多个变量或值,因此print()函数完全可以输出多个值。例如:
>>> user_name = 'Alice' >>> user_age = '18' >>> print('女猪脚:', user_name, '的年龄永远:', user_age) 女猪脚: Alice 的年龄永远: 18
- sep参数(取自英文单词separate)代表分隔符,print()函数默认分隔符为空格,用户可以自定义设置,例如:
>>> print('女猪脚:', user_name, '的年龄永远:', user_age, sep='-*-') 女猪脚:-*-Alice-*-的年龄永远:-*-18
- end参数的默认值为'\n','\n'代表了换行。如果希望print()函数输出之后不会换行,用户可以重设end参数,例如:
>>> print(1);print(2);print(3) 1 2 3 >>> print(1, end='');print(2, end='^*^');print(3,end='oh') 12^*^3oh
- file参数指定print()函数的输出目标,file参数的默认值为sys.stdout,该默认值代表了系统标准输出,也就是屏幕,因此print()函数默认输出到屏幕。
实际上,完全可以通过改变该参数让print()函数输出到指定文件。(这一点好像用的不多,等学了IO模块我们再看看例子吧。)
- flush参数用于控制输出缓存,该参数一般保持为False即可,这样可以获得较好的性能。
print()函数会生成可读性更强的输出,即略去两边的引号,并且打印出经过转义的特殊字符:

动手试试:
>>> s = 'First line.\nSecond line.' # \n means newline >>> s # without print(), \n is included in the output 'First line.\nSecond line.' >>> print(s) # with print(), \n produces a new line First line. Second line.
变量的命名规则
Python需要使用标识符给变量命名,标识符就是给程序中的变量、类、方法命名的符号(简单来说,标识符就是合法的名字)
- 标识符可以由字母、数字、下划线(_)组成,不能以数字开头
- 标识符不能是Python关键字,但可以包含关键字
- 标识符不能包含空格
Python的关键字和内置函数
Python还包含一系列关键字和内置函数,一般不建议使用它们作为变量名。
- 使用Python关键字作为变量名,Python解释器会报错
- 使用内置函数的名字作为变量名,Python解释器不会报错,只是改内置函数就被这个变量覆盖了,该内置函数就不能再使用了。
利用Python程序查看它所包含的关键字:
>>> import keyword >>> keyword.kwlist ['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
Python 的内置函数和类型。以下按字母表顺序列出它们。
| 内置函数 |
||||
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
附知识:三种程序设计中命名规则
一、匈牙利命名法
广泛应用于Microsoft Windows这类环境中。这种命名技术是由一位能干的 Microsoft 程序员查尔斯·西蒙尼(Charles Simonyi) 提出的。
匈牙利命名法通过在变量名前面加上相应的小写字母的符号标识作为前缀,标识出变量的作用域,类型等。这些符号可以多个同时使用,顺序是先m_(成 员变 量),再指针,再简单数据类型,再其他。例如:m_lpszStr, 表示指向一个以0字符结尾的字符串的长指针成员变量。
匈牙利命名法关键是:标识符的名字以一个或者多个小写字母开头作为前缀;前缀之后的是首字母大写的一个单词或多个单词组合,该单词要指明变量的用途。
例如:bEnable, nLength, hWnd。
匈牙利命名法中常用的小写字母的前缀:
| 前缀 | 类型 | 描述 |
| a | Array | 数组 |
| b | Bool | 布尔 |
| p | Point | 指针 |
二、驼峰命名法
驼峰命名法,正如它的名称所表示的那样,指的是混合使用大小写字母来构成标识符的名字。其中第一个单词首字母小写,余下的单词首字母大写。例如:
printEmployeePaychecks();
函数名中每一个逻辑断点都有一个大写字母来标记。
三、帕斯卡(Pascal)命名法:
与驼峰命名法类似。
只不过驼峰命名法是第一个单词首字母小写,而帕斯卡命名法则是第一个单词首字母大写。因此这种命名法也有人称之为“大驼峰命名法”。
例如:
DisplayInfo();
UserName
都是采用了帕斯卡命名法。
在C#中,以帕斯卡命名法和骆驼命名法居多。
事实上,很多程序设计者在实际命名时会将驼峰命名法和帕斯卡结合使用,例如变量名采用驼峰命名法,而函数采用帕斯卡命名法。
四、下划线命名法
下划线法是随着C语言的出现流行起来的,在UNIX/LIUNX这样的环境,以及GNU代码中使用非常普遍。
4.1 函数的命名
函数名使用下划线分割小写字母的方式命名:
设备名_操作名();
操作名一般采用:谓语(此时设备名作为宾语或者标明操作所属的模块)或者谓语 宾语/表语(此时设备名作为主语或者标明操作所属的模块) 等形式,如:
tic_init();
adc_is_busy();
uart_tx_char();
中断函数的命名直接使用 设备名_isr() 的形式命名,如:
timer2_isr();
4.2 变量的命名
变量的命名也采用下划线分割小写字母的方式命名。命名应当准确,不引起歧义,且长度适中。如:
int length; uint32 test_offset;
- 单字符的名字也是常用的,如i,j,k等,它们通常可用作函数内的局部变量。tmp常用做临时变量名。
- 局部静态变量,应加s_词冠(表示static),如:
static int s_lastw;
- 全局变量(尤其是供外部访问的全局变量),应加g_词冠(表示global),如:
void (* g_capture_hook)(void);
4.3 常量及宏的命名
采用下划线分割大写字母的方式命名,一般应以设备名作为前缀,防止模块间命名的重复。如:
#define TIMER0_MODE_RELOAD 2 #define TIMER2_COUNT_RETRIEVE(val) ((uint16)(65536 - (val)))
当然,看作接口的宏可以按照函数的命名方法命名,例如:
#define timer2_clear() (TF2 = 0) #define timer0_is_expired() (TF0)
据考察,没有一种命名规则可以让所有的程序员赞同,程序设计教科书一般都不指定命名规则。
命名规则对软件产品而言并不是“成败悠关”的事,我们不要化太多精力试图发明世界上最好的命名规则,而应当制定一种令大多数项目成员满意的命名规则,并在项目中贯彻实施。