关键词:
2019年的推荐系统大会(Recsys) 于今年的9月份在丹麦哥本哈根举行,来自世界各地的909位专家、学者参与了此次会议,迄今为止规模最大的一次。大会涵盖了与推荐系统相关的主题,从推荐系统的社会影响到搭建推荐系统所用的算法。
今年,除了从算法和方法的角度来看待“推荐系统”这一领域外,我们还通过发现、解决推荐系统中存在的问题来进一步认识这一领域的发展。这次会议的参会人员中还出现了社会科学家的身影。这在提醒我们,推荐系统这种技术正在影响着我们的生活,影响着人们的信息互动、娱乐消费。有句话说得好,“能力越大,责任越大”。作为技术人员,我们不仅要对用户负责,还要对和我们一起共事的同事负责。接下来的章节我们会详细地介绍这些问题,以及一些算法和应用程序。
社会影响
今年的大会特别强调了推荐系统的综合性和社会影响。第一位主题演讲人Mireille Hildebrandt谈到了GDPR如何改变经营者的动机,即谁能决定广告商或发布者等人的处理目的和处理方式,让其除了从盈利的角度出发进行优化外,还要考虑透明度和更好的方法。(注:GDPR,General Data Protection Regulation,即《通用数据保护条例》,2018年5月由欧盟出台,目的在于遏制个人信息被滥用,保护个人隐私)
第二位主题演讲者Eszter Hargittai谈到了人们的在线行为,不同平台之间人们在线行为的差异以及人们的在线行为是如何导致算法出现偏差的。最后,小组讨论了如何建立对社会负责的推荐系统的问题。
可重现性及改进
可重现性早已成为当前困扰推荐系统领域的重要话题。但是,让人人都可以使用某段代码还不够,还需要解决的一个基本问题是,如何进行试验以及如何衡量改进办法的好坏:基线有时调得不够准,数据集和任务集的选择有时也不够严谨,测试改进措施有时也没什么意义。
A Worrying Analysis of Recent Neural Recommendation Approaches一文,比较了几种较为复杂的神经CF变体方法,并且重现了这几种方法呈现的结果,还击败了其他调好的简单基线。这篇文章被评为“最佳论文”,这释放出的信号是,我们还需要在该领域投入更多,需要更加努力。
多目标/多任务优化
推荐系统的使用通常涉及多个目标,为了解决此问题,可以在多任务设置中表达问题。
优化
越来越多的推荐系统寻求针对多个目标进行优化的方法。例如,不仅要针对视频的播放量进行优化,还要对视频的点赞数和评论数也进行优化。为此,系统将具有多个损失函数,每个目标一个。在某些必要时刻,我们需要把这些损失合并为一个,因此,需要为每个损失分配一个权重。例如,
视频的浏览量与用户对视频留言评论相比,前者的重要性可能是后者的两倍。当处理许多目标时,手动设置这些权重既不是最佳选择,也可能很麻烦。获得“最佳论文”提名的另一篇论文 A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation(《电商推荐中多目标优化的帕累托效率算法》,译者注),介绍了一种自动计算权重的方法,从而达到牺牲某一目标来改变某一权重的状态(帕累托效率状态,在不牺牲其他目标的情况下无法改善单个目标)。为了达到帕累托最佳效率,通常做法是这样的:
•进化启发法:无法保证帕累托效率
•标量化方法:将所有目标合并为一个目标,即损失的加权总和。通常,标量权重由人工确定。
•在本文中,作者考虑了标量方法,并提出了两步算法,在理论保证的情况下学习标量权重。更新权重的步骤等于解决具有约束的二次方问题。
架构
Google发表了两篇论文,展示了用于视频检索和排名的多目标架构。其中一篇是: Recommending what video to watch next: a multitask ranking system。这篇文章建议使用复杂的框架处理复杂的互动,从而学习如何推荐视频:
•多个目标:参与度、满意度
•多种嵌入:图像、文本
•使用专家模型的多门混合实现上述目标
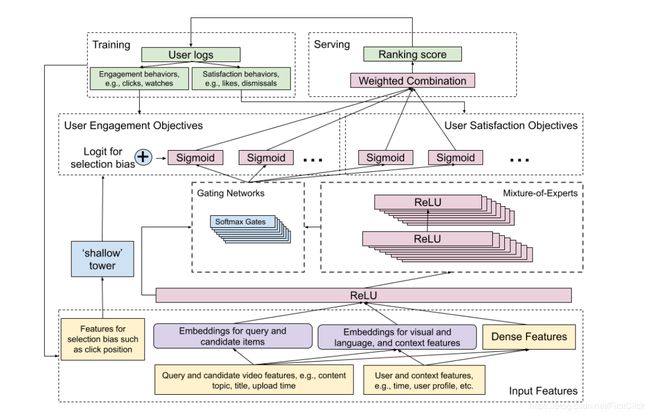
之后推出的两门课程仍围绕这个主题展开,大家对此兴趣盎然。
从隐式反馈中学习
推荐系统通常不直接衡量用户满意度,而是建立在隐式反馈信号(如点击次数、观看次数等)上。许多论文提出了更好地利用隐式反馈的方法。
Relaxed Softmax for PU Learning 提出了一种处理否定采样的新方法,这是无标记学习中常见的步骤(从隐式反馈中学习与该任务密切相关),大多数方法都假设从固态分布中采样否定。本文提出了一种基于boltzmann分布的新的负采样方案,其中选择的负采样更接近算法的决策边界,从而能够提供更多信息。
Leveraging Post-click Feedback for Content Recommendations这篇文章解决了点击后信息反馈的问题。他们关注具有点击后信息(即是否收听或跳过了歌曲)的现实世界中的音乐和视频数据集,并在点对和成对模型上显示了AUC的改进(分别为18.3%和2.5%)。
作者提出了一个通用的概率框架,用于融合三组不相交的观察结果:点击完成、点击然后跳过或不点击。每种类型反馈的置信度都是通过高斯分布的方差建模,然后执行最大似然估计。
在展示广告中,特征分布可能是不固定的,预测点击的模型需要定期更新。挑战之一是无法立即获得最新的用户反馈。在 Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction一文中,作者解决了延迟反馈的问题。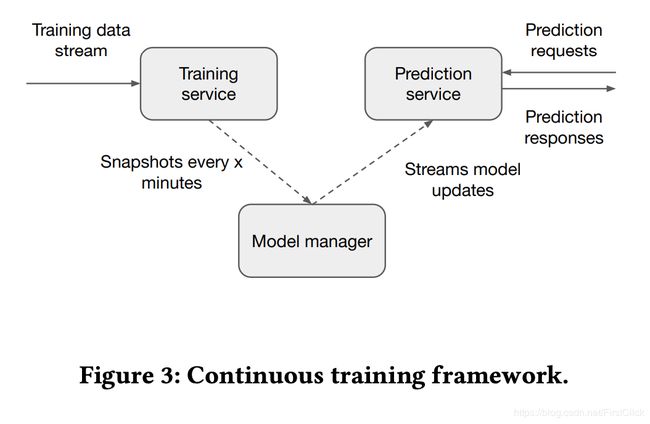
在相关的工作中,使用的损耗是延迟的反馈损耗(假定使用单独的模型来确定反馈延迟)和PU损耗(将偏置数据中的所有负样本视为未标记)。作者提出了两种损失函数,这些函数可以带来最佳的离线性能,并可以在特定模型上转化为在线收益:
•基于重要性抽样的FN加权(FN weighted )。样品首先被标记为阴性,用户参与后立即显示肯定标签。
•FN校准(FN calibration)损耗的校准版本
在反馈很明确的情况下(例如购买),即使没有推荐,用户也可能已经购买了该商品。提升(也称为增量)在此定义为由推荐引起的用户操作的增加。 Uplift-based Evaluation and Optimization of Recommenders一文提出了一种新的离线评估协议和基于提升的推荐的优化方法。
From Preference into Decision Making: Modeling User Interactions in Recommender Systems 一文引入了页面级RNN,除了可以独立考虑每个项目和操作外,还解决了页面上多个项目相互影响、多个不同操作及不同种类的操作等问题。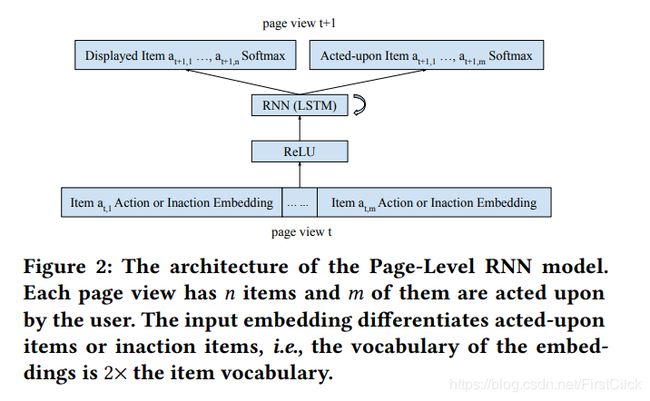
基于内容的推荐
基于内容的方法对于解决冷启动问题有很大帮助:某些项目的视图很少,某些项目则是全新的。
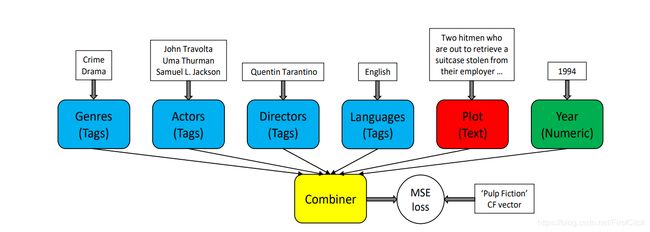
CB2CF: A Neural Multiview Content-to-Collaborative Filtering Model for Completely Cold Item Recommendations 通过生成仅包含以下内容的CF嵌入来解决此问题:
•分类特征
•连续特征
•词嵌入
然后,使用简单的CNN将上述特征映射到CF嵌入。结果表明,CB2CF不如CF,但优于单独的CB,并解决了冷启动问题。
HybridSVD: When Collaborative Information is Not Enough提出了一种方法,通过扩展传统的基于SVD的方法,同时使用协同信息和基于内容的相似性来构建产品和用户嵌入。关键思想是将用户辅助矩阵或由内容构建的相似项参数化,得出双线性形式,替换交互表中Gram矩阵中的标量乘积项。