在Spark中有几个重要概念:
- Application - 源代码就是应用
- Job - action会触发一个job
- Stage - 按照宽窄依赖来分的
- Task - 最终执行的工作
- Driver - 跑源代码main func,跑各种并行操作的机器
- Executor - 执行task细节的机器
我们从以下简单的一行代码入手,来看spark中的各个术语的含义。
scala>sc.textFile("README.md").filter(_.contains("Spark")).count
其中,sc代表SparkContext,它通过一些default的SparkConfig构建出来。这一行代码就算是一个Application。sc通过textFile, filter操作RDDs,最后count这个Action触发一个job。
整体上描述一下spark的运行:Application会运行在driver上,driver会根据代码中的action创建并提交job(runJob/submitJob)。然后从job的最后一个RDD朝前演算,遇到一个宽依赖就创建一个stage。最后以stage为单位创建task集合,并在excutor中执行每项task
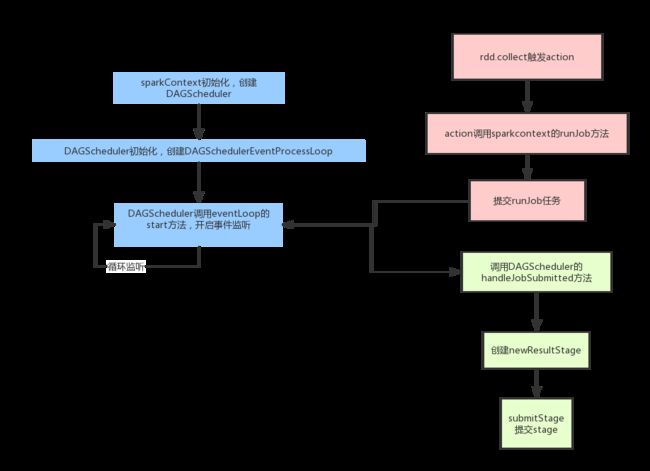
spark拆分任务的流程图如下:
涉及到的几个class:
SparkContext, DAGScheduler, DAGSchedulerEventProcessLoop, TaskScheduler
几个class的相互关系
- SparkContext中初始化DAGScheduler, TaskScheduler
- DAGScheduler中初始化DAGSchedulerEventProcessLoop(eventProcessLoop)
- DAGScheduler的构造函数参数中包含TaskScheduler
流程介绍
整个过程就是将RDD DAG按照宽窄依赖切分成Stage DAG:
- 首先在SparkContext初始化的时候会创建DAGScheduler,这个DAGScheduler每个应用只有一个。然后DAGScheduler创建的时候,会初始化一个事件捕获对象DAGSchedulerEventProcessLoop,并且开启监听(start)。之后我们的任务都会发给这个事件监听器,它会按照任务的类型创建不同的任务(doOnReceive)。
- 再从客户端程序方面说,当我们调用action操作的时候,就会触发runJob,它内部其实就是向前面的那个事件监听器提交一个任务。
- 然后事件监听器调用DAGScheduler的handleJobSubmitted做真正的处理
- 处理的时候,要去创建一个ResultStage(每个job只有一个ResultStage,其余的都是ShuffleMapStage),这会根据RDD的依赖关系,按照广度优先(总是先找到自己的所有直接parents)的思想遍历所有RDD,遇到ShuffleRDD就创建一个新的stage,最终形成一个以ResultStage为尾的stage DAG(透过访问ResultStage,朝前不停遍历就可以找到所有的stage)
- 形成stage DAG图后,遍历等待执行的stage列表,如果这个stage所依赖的父stage执行完了,它就可以执行了;否则还需要继续等待。
- 最终stage会以taskset的形式,提交给TaskScheduler,最后提交给excutor。
private def getMissingAncestorShuffleDependencies(
rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
val ancestors = new Stack[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
getShuffleDependencies(toVisit).foreach { shuffleDep =>
if (!shuffleIdToMapStage.contains(shuffleDep.shuffleId)) {
ancestors.push(shuffleDep) //广度遍历
waitingForVisit.push(shuffleDep.rdd)
} // Otherwise, the dependency and its ancestors have already been registered.
}
}
}
ancestors
}
参考: http://www.cnblogs.com/xing901022/p/6674966.html
stage拆分的整个函数调用过程如下:

举例说明:
如下图,spark job依赖关系:
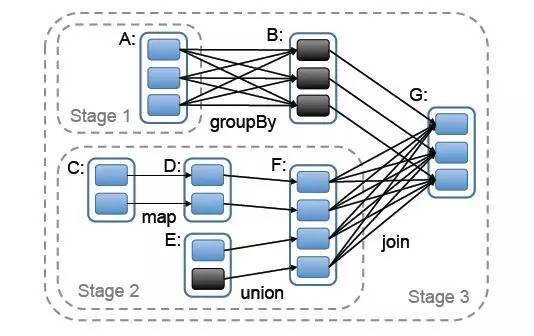
上图抽象如下:
[E] <--------------
\
[C] <------[D]------[F]--(s_F)----
\
[A] <-----(s_A)----- [B] <-------- [G]
Note: [] means an RDD, () means a shuffle dependency.
结果解析
对 G 调用 creatResultStage,先为所有parent创建ShuffleMapStage,然后创建本身的 ResultStage。 如上图getOrCreateParentStages会先创建上游 stage1和stage2, 然后创建自己的 stage3
getOrCreateParentStages 会调用 getShuffleDependencies 获得 rdd_G 所有直接宽依赖 HashSet(s_F, s_A), 然后遍历集合,对 s_F 和 s_A 调用 getOrCreateShuffleMapStage
对 s_A 调用 getOrCreateShuffleMapStage, shuffleIdToMapStage 中获取判断为None, 对 rdd_A 调用getMissingAncestorShuffleDependencies, 返回为空, 对 s_A 调用 createShuffleMapStage, 由于rdd_A 没有parent stage 直接就创建 stage1 返回
对 s_F 调用 getOrCreateShuffleMapStage, shuffleIdToMapStage 中获取判断为None, 对 rdd_F 调用 getMissingAncestorShuffleDependencies, 返回为空, 对 s_F 调用 createShuffleMapStage, 由于rdd_F 没有parent stage 直接就创建 stage2 返回
把 List(stage1,stage2) 作为 stage3 的 parents stages 创建 stage3
至此,Stage都建立起来之后,就要开始执行各个stage
submitStage -> getMissingParentStages -> submitMissingTasks -> submitStage
整体上来讲:
- 在submitStage中会计算stage之间的依赖关系,依赖关系分为宽依赖和窄依赖两种
- 如果计算中发现当前的stage没有任何依赖或者所有的依赖都已经准备完毕,则提交task
- 提交task是调用函数submitMissingTasks来完成
-当前stage执行完毕之后,再调用函数submitStage来执行child stage
TaskScheduler在SparkContext初始化期间就会初始化并且start,其backend会根据deploy mode作相应调整
submitMissingTasks -> taskScheduler(TaskSchedulerImpl).submitTasks -> backend.reviveOffers -> executor.launchTask -> threadPool.execute
private def submitMissingTasks(stage: Stage, jobId: Int) {
......
......
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
submitWaitingChildStages(stage)
}
注意:
- stageID从1开始,按照"爷->父->子->孙"一次递增1
private val nextStageId = new AtomicInteger(0)
val id = nextStageId.getAndIncrement()
- 每个job只有一个ResultStage,其余的都是ShuffleMapStage
- 每个Stage的实例中,都包含一个parents的属性,这样就可以透过"孙"stage朝前找到所有的"祖先"stage