目录
一: 卡顿检测以及原理
runloop卡顿检测
消息转发解决定时器循环引用
GCD定时器封装
NSProxy消息转发
Tagged Pointer
二: 性能优化,卡顿产生原理以及优化
三: app启动速度优化
四: 包大小优化
一: 卡顿检测
平时所说的“卡顿”主要是因为在主线程执行了比较耗时的操作
除了用xcode的Time profiler (程序耗时检测), Core Animation(检测刷新帧率)工具外,代码层面也可以检测.
可以添加Observer到主线程RunLoop中,通过监听RunLoop状态切换的耗时,以达到监控卡顿的目的
检测runloop间隔,打印主线程堆栈
和Core Animation 类似,YYFPSLabel放到屏幕上就可以检测刷新帧率,CADisplayLink调用频率和屏幕的刷帧频率一致,60FPS 左右,如果主线程卡顿,CADisplayLink调用频率较少
CADisplayLink NSTimer依赖于RunLoop,如果RunLoop的任务过于繁重,可能会导致NSTimer不准时,而且容易造成循环引用.(循环引用导致内存泄漏,内存就会偏高)
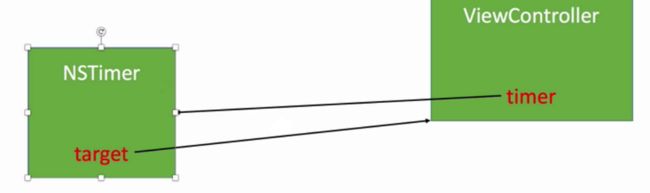
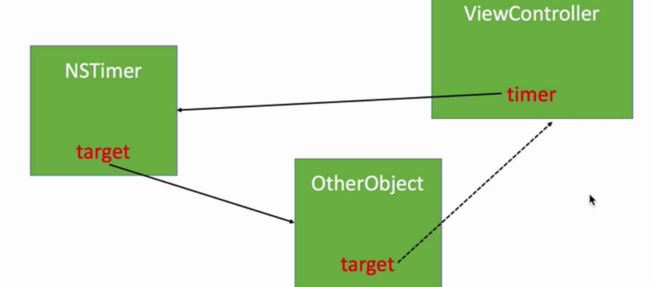
1.1 如何解决Timer循环引用?
用block回调的方法,或用消息转发
OC消息发送流程如下
1 消息发送
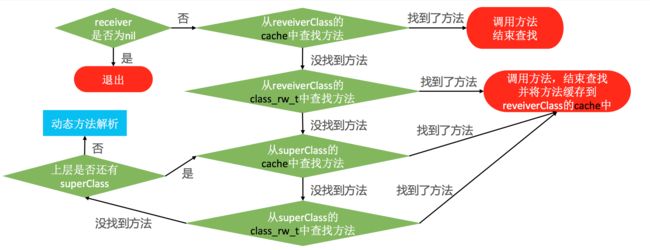
2 动态方法解析

3 消息转发

NSProxy是苹果用来消息转发的类,消息转发效率更高.
1.2 如何让定时器更准时?
GCD的定时器
//队列
dispatch_queue_t queue = dispatch_get_main_queue();
//只要不是主队列,gcd定时器就在子线程执行任务
// dispatch_queue_t queue = dispatch_queue_create("timer", DISPATCH_QUEUE_SERIAL);
//创建定时器
dispatch_source_t timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, queue);
// 设置时间
uint64_t start = 2.0;
uint64_t interval = 1.0;
dispatch_source_set_timer(timer,
dispatch_time(DISPATCH_TIME_NOW, start * NSEC_PER_SEC),
interval * NSEC_PER_SEC, 0);
// 设置回调
dispatch_source_set_event_handler(timer, ^{
});
// 启动定时器
dispatch_resume(timer);
gcd创建的对象arc下不用自己管理内存
1.3 检测runloop状态切换,打印出卡顿时主线程堆栈
LXDAppFluecyMonitor这个第三方通过监听runloop状态切换用的时间来检测是否卡顿,可以打印出卡顿时主线程堆栈

1.4 Tagged Pointer
从64bit开始,iOS引入了Tagged Pointer技术,用于优化NSNumber、NSDate、NSString等小对象的存储
在没有使用Tagged Pointer之前, NSNumber等对象需要动态分配内存、维护引用计数等,NSNumber指针存储的是堆中NSNumber对象的地址值
使用Tagged Pointer之后,NSNumber指针里面存储的数据变成了:Tag + Data,也就是将数据直接存储在了指针中
当指针不够存储数据时,才会使用动态分配内存的方式来存储数据
objc_msgSend能识别Tagged Pointer,比如NSNumber的intValue方法,直接从指针提取数据,节省了以前的调用开销
NSString *str1 = [NSString stringWithFormat:@"abc"];
NSString *str2 = [NSString stringWithFormat:@"123abcjfdosfjjldsjfa112"];
NSLog(@"%@ %@", [str1 class], [str2 class]);
NSTaggedPointerString __NSCFString

二: 卡顿优化
2.1 CPU和GPU卡顿原因
CPU和GPU
在屏幕成像的过程中,CPU和GPU起着至关重要的作用
CPU(Central Processing Unit,中央处理器)
对象的创建和销毁、对象属性的调整、布局计算、文本的计算和排版、图片的格式转换和解码、图像的绘制(Core Graphics)
GPU(Graphics Processing Unit,图形处理器)
纹理的渲染
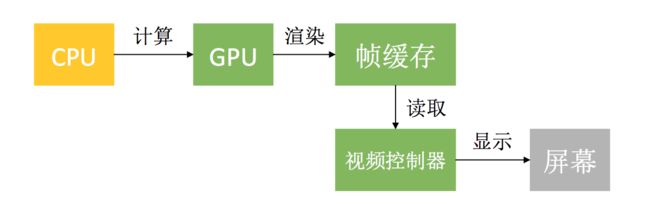
在iOS中是双缓冲机制,有前帧缓存、后帧缓存
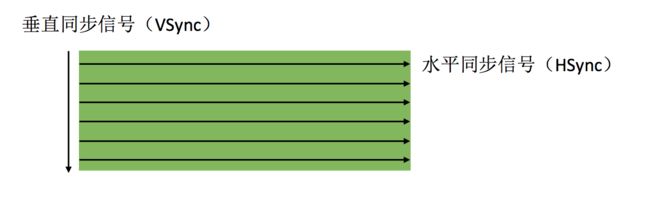
每次垂直同步信号出来时候,把处理好的帧显示在屏幕上.按照60FPS的刷帧率,每隔16ms就会有一次VSync信号
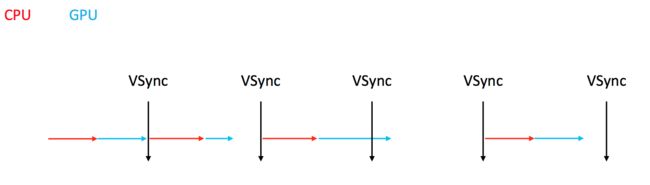
垂直同步信号来的时候,GPU如果没有处理完成,只能将上一次处理好的帧显示出来,这就是掉帧,等下一次垂直同步信号出来后,这个数据处理好后再显示.
卡顿解决的主要思路
尽可能减少CPU、GPU资源消耗
2.2 卡顿解决方案
- 卡顿优化 - CPU
1 尽量用轻量级的对象,比如用不到事件处理的地方,可以考虑使用CALayer取代UIView(下划线)
2 不要频繁地调用UIView的相关属性,比如frame、bounds、transform等属性,尽量减少不必要的修改
3 尽量提前计算好布局,在有需要时一次性调整对应的属性,不要多次修改属性
4 Autolayout会比直接设置frame消耗更多的CPU资源
5 图片的size最好刚好跟UIImageView的size保持一致
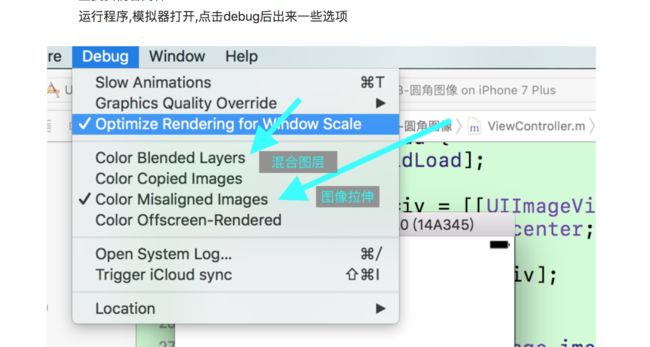
解释:
Color Blended Layers: 这个是检测混合图层的,如果有view有透明度的话对这一项打钩会显示红色,正常显示绿色.
Color Misaligned Images: 打钩后这个检测图像是否变形,变形的话显示黄色.
Color Misaligned Images打钩后显示黄色的话,表明图片变形的话,写一个方法传入图片和imageView的尺寸,返回一张这个尺寸的图片
dispatch_async(dispatch_get_global_queue(0, 0), ^{
UIGraphicsBeginImageContextWithOptions(imgeSize, YES, 0);
// 绘制图像
[image drawInRect:CGRectMake(0, 0, imgeSize.width, imgeSize.height)];
// 取得结果
UIImage *result = UIGraphicsGetImageFromCurrentImageContext();
// 关闭上下文
UIGraphicsEndImageContext();
dispatch_async(dispatch_get_main_queue(), ^{
if (completion != nil) {
completion(result);
}
});
});
6 控制一下线程的最大并发数量
7 尽量避免日期格式转换 [NSDate dateWithString:@"1990-11-11" format:@"yyyy-MM-dd"]
8 尽量把耗时的操作放到子线程
文本处理(尺寸计算、绘制)
图片处理(解码、绘制)
9 tableView不要动态创建子控件,尽可能使用懒加载,尽量少设置透明度.
- 卡顿优化 - GPU
尽量避免短时间内大量图片的显示,尽可能将多张图片合成一张进行显示
GPU能处理的最大纹理尺寸是4096x4096,一旦超过这个尺寸,就会占用CPU资源进行处理,所以纹理尽量不要超过这个尺寸
尽量减少视图数量和层次
减少透明的视图(alpha<1),不透明的就设置opaque为YES
尽量避免出现离屏渲染
在OpenGL中,GPU有2种渲染方式
On-Screen Rendering:当前屏幕渲染,在当前用于显示的屏幕缓冲区进行渲染操作
Off-Screen Rendering:离屏渲染,在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作
离屏渲染消耗性能的原因
需要创建新的缓冲区
离屏渲染的整个过程,需要多次切换上下文环境,先是从当前屏幕(On-Screen)切换到离屏(Off-Screen);等到离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上,又需要将上下文环境从离屏切换到当前屏幕
- 离屏渲染
哪些操作会触发离屏渲染?
光栅化,layer.shouldRasterize = YES
遮罩,layer.mask
圆角,同时设置layer.masksToBounds = YES、layer.cornerRadius大于0
考虑通过CoreGraphics绘制裁剪圆角,或者叫UI提供圆角图片
用 Instuments 的 GPU Driver 预设,能够实时查看到 CPU 和 GPU 的资源消耗。在这个预设内,你能查看到几乎所有与显示有关的数据,比如 Texture 数量、CA 提交的频率、GPU 消耗等,在定位界面卡顿的问题时。
- 图片加载
1.加载小图片\使用频率比较高的图片
1> 利用imageNamed:方法加载过的图片, 永远有缓存, 这个缓存是由系统管理的, 无法通过代码销毁缓存
通过 imageNamed 创建 UIImage 时,系统实际上只是在 Bundle 内查找到文件名,然后把这个文件名放到 UIImage 里返回,并没有进行实际的文件读取和解码。当 UIImage 第一次显示到屏幕上时,其内部的解码方法才会被调用,同时解码结果会保存到一个全局缓存去。在图片解码后,App 第一次退到后台和收到内存警告时,该图片的缓存才会被清空,其他情况下缓存会一直存在。
2.加载大图片\使用频率比较低的图片(一次性的图片, 比如版本新特性的图片)
1> 利用initWithContentsOfFile:\imageWithContentsOfFile:等方法加载过的图片, 没有缓存, 只要用完了, 就会自动销毁
2.3 耗电网络优化
CPU处理,Processing
网络,Networking
定位,Location
图像,Graphics
- 耗电优化
尽可能降低CPU、GPU功耗,少用定时器
PerformSelecter
当调用 NSObject 的 performSelecter:afterDelay: 后,实际上其内部会创建一个 Timer 并添加到当前线程的 RunLoop 中。所以如果当前线程没有 RunLoop,则这个方法会失效。
当调用 performSelector:onThread: 时,实际上其会创建一个 Timer 加到对应的线程去,同样的,如果对应线程没有 RunLoop 该方法也会失效。
优化I/O操作
尽量不要频繁写入小数据,最好批量一次性写入
读写大量重要数据时,考虑用dispatch_io,其提供了基于GCD的异步操作文件I/O的API。用dispatch_io系统会优化磁盘访问
数据量比较大的,建议使用数据库(比如SQLite、CoreData)网络优化
减少、压缩网络数据
如果多次请求的结果是相同的,尽量使用缓存
使用断点续传,否则网络不稳定时可能多次传输相同的内容
网络不可用时,不要尝试执行网络请求
让用户可以取消长时间运行或者速度很慢的网络操作,设置合适的超时时间
批量传输,比如,下载视频流时,不要传输很小的数据包,直接下载整个文件或者一大块一大块地下载。如果下载广告,一次性多下载一些,然后再慢慢展示。如果下载电子邮件,一次下载多封,不要一封一封地下载定位优化
如果只是需要快速确定用户位置,最好用CLLocationManager的requestLocation方法。定位完成后,会自动让定位硬件断电
如果不是导航应用,尽量不要实时更新位置,定位完毕就关掉定位服务
尽量降低定位精度,比如尽量不要使用精度最高的kCLLocationAccuracyBest
需要后台定位时,尽量设置pausesLocationUpdatesAutomatically为YES,如果用户不太可能移动的时候系统会自动暂停位置更新
尽量不要使用startMonitoringSignificantLocationChanges,优先考虑startMonitoringForRegion:硬件检测优化
用户移动、摇晃、倾斜设备时,会产生动作(motion)事件,这些事件由加速度计、陀螺仪、磁力计等硬件检测。在不需要检测的场合,应该及时关闭这些硬件
三: APP的启动优化
3.1 启动流程
APP的启动可以分为2种
冷启动(Cold Launch):从零开始启动APP
热启动(Warm Launch):APP已经在内存中,在后台存活着,再次点击图标启动APP
APP启动时间的优化,主要是针对冷启动进行优化
通过添加环境变量可以打印出APP的启动时间分析(Edit scheme -> Run -> Arguments)
DYLD_PRINT_STATISTICS设置为1
如果需要更详细的信息,那就将DYLD_PRINT_STATISTICS_DETAILS设置为1
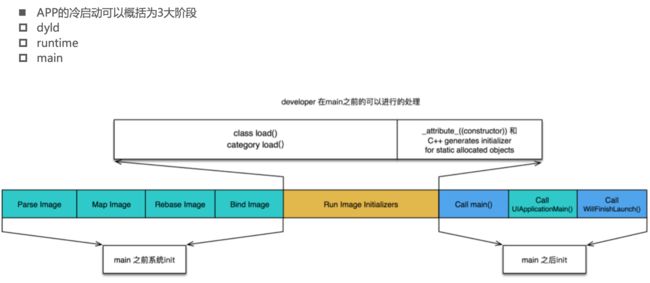
dyld(dynamic link editor),Apple的动态链接器,可以用来装载Mach-O文件(可执行文件、动态库等)
启动APP时,dyld所做的事情有
装载APP的可执行文件(可执行文件包含代码和动态库依赖信息),同时会递归加载所有依赖的动态库
当dyld把可执行文件、动态库都装载完毕后,会通知Runtime进行下一步的处理
启动APP时,runtime所做的事情有
调用map_images进行可执行文件内容的解析和处理
在load_images中调用call_load_methods,调用所有Class和Category的+load方法
进行各种objc结构的初始化(注册Objc类 、初始化类对象等等)
调用C++静态初始化器和attribute((constructor))修饰的函数
到此为止,可执行文件和动态库中所有的符号(Class,Protocol,Selector,IMP,…)都已经按格式成功加载到内存中,被runtime 所管理
总结一下
APP的启动由dyld主导,将可执行文件加载到内存,顺便加载所有依赖的动态库
并由runtime负责加载成objc定义的结构
所有初始化工作结束后,dyld就会调用main函数
接下来就是UIApplicationMain函数,AppDelegate的application:didFinishLaunchingWithOptions:方法
3.2 启动优化
按照不同的阶段
dyld
减少动态库、合并一些动态库(定期清理不必要的动态库)
减少Objc类、分类的数量、减少Selector数量(定期清理不必要的类、分类), 装在可执行文件时候有加载类分类的操作.
减少C++虚函数数量
runtime
少在+load方法里写逻辑代码可以用+initialize方法和dispatch_once取代
main
在不影响用户体验的前提下,尽可能将一些操作延迟,不要全部都放在finishLaunching方法中
按需加载
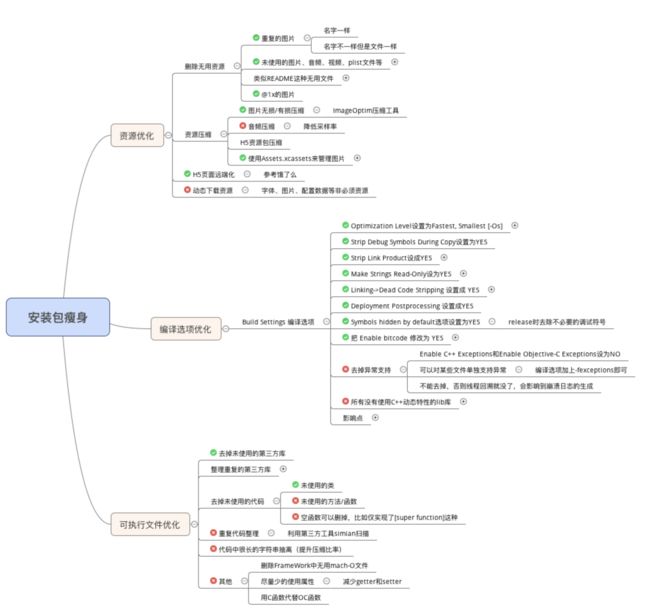
四: 安装包瘦身
安装包(IPA)主要由可执行文件(源代码文件 编译链接生产的)、资源(图片 音视频 stroyboard xib)组成
项目编译完生产app文件,app文件压缩后成IPA文件
1 资源(图片、音频、视频等)采取无损压缩
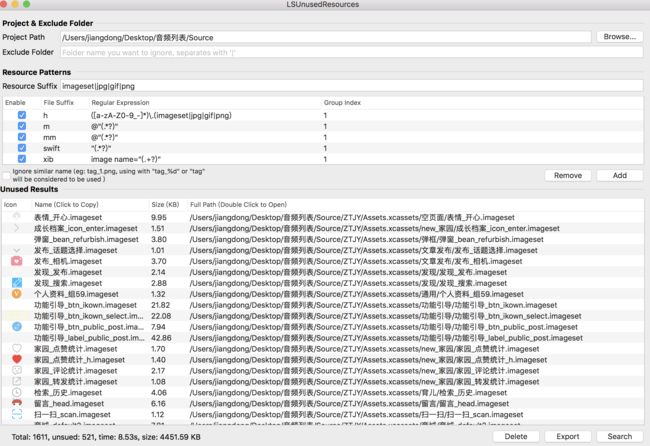
2 去除没有用到的资源: https://github.com/tinymind/LSUnusedResources
3 编译器优化
Deployment Postprocessing和Strip Linked Product,两个需要都设置为YES才有用。
原理是打开这两个选项后构建ipa会去除掉symbol符号,就是那些类名啊函数名啊啥的。这样子的影响就是运行时你没法进行线程回溯,符号都没了回溯了也是乱码。但是不会影响正常的崩溃日志生成和解析。
4 利用AppCode(https://www.jetbrains.com/objc/)检测未使用的代码:菜单栏 -> Code -> Inspect Code
5 手动移除代码
- 梳理项目里的第三方代码,没有直接用的全部删除.
- 梳理用到的第三方代码,如果有功能类似的,移除一个.
- 如果只使用了第三方一部分代码,可以自己实现这个功能,移除这个第三方.
- 项目里旧的类,要及时移除,类里面引用的类也要逐一检查,看是否可以移除
6 视频/音频 大图片资源不要放到包里,可以从服务端下载.
7 图片尽可能放到Assets.xcassets,放进去下载安装包只下载 x2或x3图片.
8 使用 xib/storyboard 来开发视图界面会一定程序增加安装包的大小。尽可能用diamante布局.
9 引入第三方库之前要调研导致包增大多少.
- 编写LLVM插件检测出重复代码、未被调用的代码
-
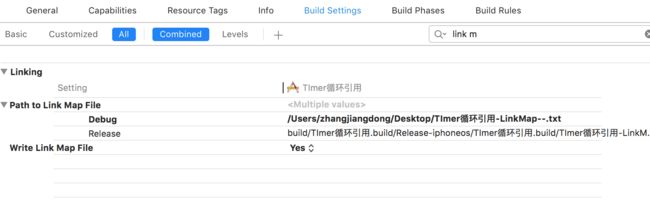
LinkMap分析哪里占用包资源大
Build settings 搜索 link map Write Link Map File 设置成yes, 上面路径前缀设置成桌面,编译后桌面会多一个当前架构下 .txt格式的文件(例如:TImer循环引用-LinkMap-normal-x86_64)
生成LinkMap文件,可以查看可执行文件的具体组成
 屏幕快照 2019-03-10 17.37.31.png
屏幕快照 2019-03-10 17.37.31.png
可借助第三方工具解析LinkMap文件: https://github.com/huanxsd/LinkMap
bitcode
Bitcode 类似于一个中间码,被上传到 AppleStore 之后,苹果会根据下载应用的用户的手机指令集类型生成只有该指令集的二进制,进行下发,从而达到精简安装包体积的目的。不同的设备只下载支持自己设备架构的包.
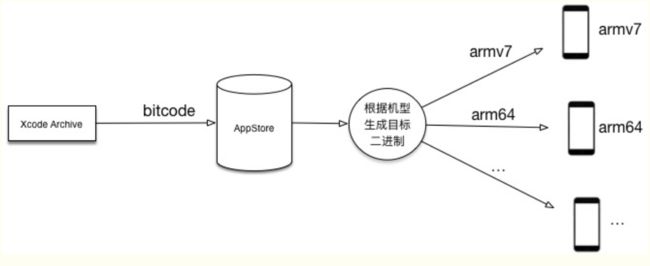
但是如果其中包含第三方库,不支持 Bitcode 时候,需要将 Enable BitCode 设置成 NO。而且这个选项是项目里只要有一个第三方库不支持,就不能开的,否则连接错误。
Other linker flags
Targets选项下有Other linker flags的设置,用来填写XCode的链接器参数,如:-ObjC -all_load -force_load等。
在ios开发中,我们经常会使用到第三方的一些静态库,导入第三方类库运行程序后你会发现,编译时可以正常编译但是运行时会app会闪退,报出selector not recognized的错误。一般的第三方库的开发文档中都会写出这种问题的解决方法,如在Other Linker Flags中加入-ObjC或者-all_load或者-force_load这样的解决方法。为什要这要做呢?报错为什么编译的时候有问题呢,首先我们先引入一个链接器的概念.
还记得我们在学习C程序的时候,从C代码到可执行文件经历的步骤是:
源代码 > 预处理器 > 编译器 > 汇编器 > 机器码 > 链接器 > 可执行文件
在最后一步需要把.o文件和C语言运行库链接起来,这时候需要用到ld命令。源文件经过一系列处理以后,会生成对应的.obj文件,然后一个项目必然会有许多.obj文件,并且这些文件之间会有各种各样的联系,例如函数调用。链接器做的事就是把这些目标文件和所用的一些库链接在一起形成一个完整的可执行文件
那我们为什么要设置Other Linker Flags呢 因为Other Linker Flags其实就是链接器工作时除了默认参数外的其他参数。
运行时的异常时由于静态库, 链接器,与OC语言的动态的特性之间的问题, 如果一个类有了分类,那么链接器就不会将静态库的类与分类之间的代码完成进行合并,这就阻止了在最终的应用程序中的可执行文件缺失了分类中的代码,这样函数调用接失败了.
-ObjC
一般这个参数足够解决前面提到的问题,这个flag告诉链接器把库中定义的Objective-C类和Category都加载进来。这样编译之后的app会变大,因为加载了很多不必要的文件而导致可执行文件变大。
-all_load
但是如果静态库中有类和category的话只有加入这个flag才行,但是Objc也不是万能的,当静态库中只有分类而没有类的时候,Objc就失效了,这就需要使用-all_load或者-force_load了。
-all_load会强制链接器把目标文件都加载进来,即使没有objc代码。但是这个参数也有一个弊端,那就是你使用了不止一个静态库文件,那么你很有可能会遇到ld: duplicate symbol错误,因为不同的库文件里面可能会有相同的目标文件 这里会有两种方法解决 1:用命令行就行拆包. 2:就是用下面的这个参数
-force_load
这个flag所做的事情跟-all_load其实是一样的,只是-force_load需要指定要进行全部加载的库文件的路径,这样的话,你就只是完全加载了一个库文件,不影响其余库文件的按需加载 .
如果静态库,不加-ObjC 的话,只把使用到的类加载进来,不会加载分类,会减少一些包大小,但是需要把使用到的功能点一遍,确保没有崩溃.如果部分静态库需要用分类,可以部分分类加-force_load.