spark通信流程
概述
spark作为一套高效的分布式运算框架,但是想要更深入的学习它,就要通过分析spark的源码,不但可以更好的帮助理解spark的工作过程,还可以提高对集群的排错能力,本文主要关注的是Spark的Master的启动流程与Worker启动流程。
现在Spark最新版本为1.6,但是代码的逻辑不够清晰,不便于理解,这里以1.3为准
Master启动
我们启动一个Master是通过Shell命令启动了一个脚本start-master.sh开始的,这个脚本的启动流程如下
start-master.sh -> spark-daemon.sh start org.apache.spark.deploy.master.Master
我们可以看到脚本首先启动了一个org.apache.spark.deploy.master.Master类,启动时会传入一些参数,比如cpu的执行核数,内存大小,app的main方法等
查看Master类的main方法
private[spark] object Master extends Logging {
val systemName = "sparkMaster"
private val actorName = "Master"
//master启动的入口
def main(argStrings: Array[String]) {
SignalLogger.register(log)
//创建SparkConf
val conf = new SparkConf
//保存参数到SparkConf
val args = new MasterArguments(argStrings, conf)
//创建ActorSystem和Actor
val (actorSystem, _, _, _) = startSystemAndActor(args.host, args.port, args.webUiPort, conf)
//等待结束
actorSystem.awaitTermination()
}
这里主要看startSystemAndActor方法
/**
* Start the Master and return a four tuple of:
* (1) The Master actor system
* (2) The bound port
* (3) The web UI bound port
* (4) The REST server bound port, if any
*/
def startSystemAndActor(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (ActorSystem, Int, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
//利用AkkaUtils创建ActorSystem
val (actorSystem, boundPort) = AkkaUtils.createActorSystem(systemName, host, port, conf = conf,
securityManager = securityMgr)
val actor = actorSystem.actorOf(
Props(classOf[Master], host, boundPort, webUiPort, securityMgr, conf), actorName)
....
}
}
spark底层通信使用的是Akka
通过ActorSystem创建Actor -> actorSystem.actorOf, 就会执行Master的构造方法->然后执行Actor生命周期方法
执行Master的构造方法初始化一些变量
private[spark] class Master(
host: String,
port: Int,
webUiPort: Int,
val securityMgr: SecurityManager,
val conf: SparkConf)
extends Actor with ActorLogReceive with Logging with LeaderElectable {
//主构造器
//启用定期器功能
import context.dispatcher // to use Akka's scheduler.schedule()
val hadoopConf = SparkHadoopUtil.get.newConfiguration(conf)
def createDateFormat = new SimpleDateFormat("yyyyMMddHHmmss") // For application IDs
//woker超时时间
val WORKER_TIMEOUT = conf.getLong("spark.worker.timeout", 60) * 1000
val RETAINED_APPLICATIONS = conf.getInt("spark.deploy.retainedApplications", 200)
val RETAINED_DRIVERS = conf.getInt("spark.deploy.retainedDrivers", 200)
val REAPER_ITERATIONS = conf.getInt("spark.dead.worker.persistence", 15)
val RECOVERY_MODE = conf.get("spark.deploy.recoveryMode", "NONE")
//一个HashSet用于保存WorkerInfo
val workers = new HashSet[WorkerInfo]
//一个HashMap用保存workid -> WorkerInfo
val idToWorker = new HashMap[String, WorkerInfo]
val addressToWorker = new HashMap[Address, WorkerInfo]
//一个HashSet用于保存客户端(SparkSubmit)提交的任务
val apps = new HashSet[ApplicationInfo]
//一个HashMap Appid-》 ApplicationInfo
val idToApp = new HashMap[String, ApplicationInfo]
val actorToApp = new HashMap[ActorRef, ApplicationInfo]
val addressToApp = new HashMap[Address, ApplicationInfo]
//等待调度的App
val waitingApps = new ArrayBuffer[ApplicationInfo]
val completedApps = new ArrayBuffer[ApplicationInfo]
var nextAppNumber = 0
val appIdToUI = new HashMap[String, SparkUI]
//保存DriverInfo
val drivers = new HashSet[DriverInfo]
val completedDrivers = new ArrayBuffer[DriverInfo]
val waitingDrivers = new ArrayBuffer[DriverInfo] // Drivers currently spooled for scheduling
主构造器执行完就会执行preStart --》执行完receive方法
//启动定时器,进行定时检查超时的worker
//重点看一下CheckForWorkerTimeOut
context.system.scheduler.schedule(0 millis, WORKER_TIMEOUT millis, self, CheckForWorkerTimeOut)
preStart方法里创建了一个定时器,定时检查Woker的超时时间 val WORKER_TIMEOUT = conf.getLong("spark.worker.timeout", 60) * 1000 默认为60秒
到此Master的初始化的主要过程到我们已经看到了,主要就是构造一个Master的Actor进行等待消息,并初始化了一堆集合来保存Worker信息,和一个定时器来检查Worker的超时
Master启动时序图
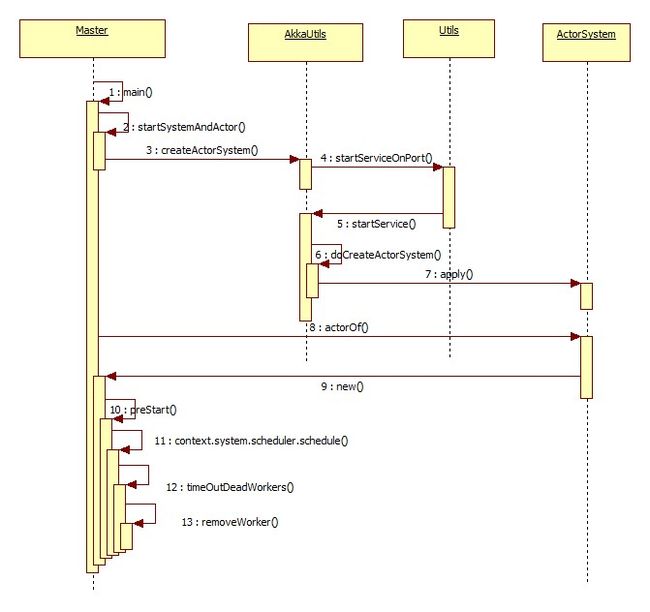
Woker的启动
通过Shell脚本执行salves.sh -> 通过读取slaves 通过ssh的方式启动远端的worker
spark-daemon.sh start org.apache.spark.deploy.worker.Worker
脚本会启动org.apache.spark.deploy.worker.Worker类
看Worker源码
private[spark] object Worker extends Logging {
//Worker启动的入口
def main(argStrings: Array[String]) {
SignalLogger.register(log)
val conf = new SparkConf
val args = new WorkerArguments(argStrings, conf)
//新创ActorSystem和Actor
val (actorSystem, _) = startSystemAndActor(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir)
actorSystem.awaitTermination()
}
这里最重要的是Woker的startSystemAndActor
def startSystemAndActor(
host: String,
port: Int,
webUiPort: Int,
cores: Int,
memory: Int,
masterUrls: Array[String],
workDir: String,
workerNumber: Option[Int] = None,
conf: SparkConf = new SparkConf): (ActorSystem, Int) = {
// The LocalSparkCluster runs multiple local sparkWorkerX actor systems
val systemName = "sparkWorker" + workerNumber.map(_.toString).getOrElse("")
val actorName = "Worker"
val securityMgr = new SecurityManager(conf)
//通过AkkaUtils ActorSystem
val (actorSystem, boundPort) = AkkaUtils.createActorSystem(systemName, host, port,
conf = conf, securityManager = securityMgr)
val masterAkkaUrls = masterUrls.map(Master.toAkkaUrl(_, AkkaUtils.protocol(actorSystem)))
//通过actorSystem.actorOf创建Actor Worker-》执行构造器 -》 preStart -》 receice
actorSystem.actorOf(Props(classOf[Worker], host, boundPort, webUiPort, cores, memory,
masterAkkaUrls, systemName, actorName, workDir, conf, securityMgr), name = actorName)
(actorSystem, boundPort)
}
这里Worker同样的构造了一个属于Worker的Actor对象,到此Worker的启动初始化完成
Worker与Master通信
根据Actor生命周期接着Worker的preStart方法被调用
override def preStart() {
assert(!registered)
logInfo("Starting Spark worker %s:%d with %d cores, %s RAM".format(
host, port, cores, Utils.megabytesToString(memory)))
logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")
logInfo("Spark home: " + sparkHome)
createWorkDir()
context.system.eventStream.subscribe(self, classOf[RemotingLifecycleEvent])
shuffleService.startIfEnabled()
webUi = new WorkerWebUI(this, workDir, webUiPort)
webUi.bind()
//Worker向Master注册
registerWithMaster()
....
}
这里调用了一个registerWithMaster方法,开始向Master注册
def registerWithMaster() {
// DisassociatedEvent may be triggered multiple times, so don't attempt registration
// if there are outstanding registration attempts scheduled.
registrationRetryTimer match {
case None =>
registered = false
//开始注册
tryRegisterAllMasters()
....
}
}
registerWithMaster里通过匹配调用了tryRegisterAllMasters方法
,接下来看
private def tryRegisterAllMasters() {
//遍历master的地址
for (masterAkkaUrl <- masterAkkaUrls) {
logInfo("Connecting to master " + masterAkkaUrl + "...")
//Worker跟Mater建立连接
val actor = context.actorSelection(masterAkkaUrl)
//向Master发送注册信息
actor ! RegisterWorker(workerId, host, port, cores, memory, webUi.boundPort, publicAddress)
}
}
通过masterAkkaUrl和Master建立连接后
actor ! RegisterWorker(workerId, host, port, cores, memory, webUi.boundPort, publicAddress)Worker向Master发送了一个消息,带去一些参数,id,主机,端口,cpu核数,内存等待
override def receiveWithLogging = {
......
//接受来自Worker的注册信息
case RegisterWorker(id, workerHost, workerPort, cores, memory, workerUiPort, publicAddress) =>
{
logInfo("Registering worker %s:%d with %d cores, %s RAM".format(
workerHost, workerPort, cores, Utils.megabytesToString(memory)))
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
//判断这个worker是否已经注册过
} else if (idToWorker.contains(id)) {
//如果注册过,告诉worker注册失败
sender ! RegisterWorkerFailed("Duplicate worker ID")
} else {
//没有注册过,把来自Worker的注册信息封装到WorkerInfo当中
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,
sender, workerUiPort, publicAddress)
if (registerWorker(worker)) {
//用持久化引擎记录Worker的信息
persistenceEngine.addWorker(worker)
//向Worker反馈信息,告诉Worker注册成功
sender ! RegisteredWorker(masterUrl, masterWebUiUrl)
schedule()
} else {
val workerAddress = worker.actor.path.address
logWarning("Worker registration failed. Attempted to re-register worker at same " +
"address: " + workerAddress)
sender ! RegisterWorkerFailed("Attempted to re-register worker at same address: "
+ workerAddress)
}
}
}
这里是最主要的内容;
receiveWithLogging里会轮询到Worker发送的消息,
Master收到消息后将参数封装成WorkInfo对象添加到集合中,并加入到持久化引擎中
sender ! RegisteredWorker(masterUrl, masterWebUiUrl)向Worker发送一个消息反馈
接下来看Worker的receiveWithLogging
override def receiveWithLogging = {
case RegisteredWorker(masterUrl, masterWebUiUrl) =>
logInfo("Successfully registered with master " + masterUrl)
registered = true
changeMaster(masterUrl, masterWebUiUrl)
//启动定时器,定时发送心跳Heartbeat
context.system.scheduler.schedule(0 millis, HEARTBEAT_MILLIS millis, self, SendHeartbeat)
if (CLEANUP_ENABLED) {
logInfo(s"Worker cleanup enabled; old application directories will be deleted in: $workDir")
context.system.scheduler.schedule(CLEANUP_INTERVAL_MILLIS millis,
CLEANUP_INTERVAL_MILLIS millis, self, WorkDirCleanup)
}
worker接受来自Master的注册成功的反馈信息,启动定时器,定时发送心跳Heartbeat
case SendHeartbeat =>
//worker发送心跳的目的就是为了报活
if (connected) { master ! Heartbeat(workerId) }
Master端的receiveWithLogging收到心跳消息
override def receiveWithLogging = {
....
case Heartbeat(workerId) => {
idToWorker.get(workerId) match {
case Some(workerInfo) =>
//更新最后一次心跳时间
workerInfo.lastHeartbeat = System.currentTimeMillis()
.....
}
}
}
记录并更新workerInfo.lastHeartbeat = System.currentTimeMillis()最后一次心跳时间
Master的定时任务会不断的发送一个CheckForWorkerTimeOut内部消息不断的轮询集合里的Worker信息,如果超过60秒就将Worker信息移除
//检查超时的Worker
case CheckForWorkerTimeOut => {
timeOutDeadWorkers()
}
timeOutDeadWorkers方法
def timeOutDeadWorkers() {
// Copy the workers into an array so we don't modify the hashset while iterating through it
val currentTime = System.currentTimeMillis()
val toRemove = workers.filter(_.lastHeartbeat < currentTime - WORKER_TIMEOUT).toArray
for (worker <- toRemove) {
if (worker.state != WorkerState.DEAD) {
logWarning("Removing %s because we got no heartbeat in %d seconds".format(
worker.id, WORKER_TIMEOUT/1000))
removeWorker(worker)
} else {
if (worker.lastHeartbeat < currentTime - ((REAPER_ITERATIONS + 1) * WORKER_TIMEOUT)) {
workers -= worker // we've seen this DEAD worker in the UI, etc. for long enough; cull it
}
}
}
}
如果 (最后一次心跳时间<当前时间-超时时间)则判断为Worker超时,
将集合里的信息移除。
当下一次收到心跳信息时,如果是已注册过的,workerId不为空,但是WorkerInfo已被移除的条件,就会sender ! ReconnectWorker(masterUrl)发送一个重新注册的消息
case None =>
if (workers.map(_.id).contains(workerId)) {
logWarning(s"Got heartbeat from unregistered worker $workerId." +
" Asking it to re-register.")
//发送重新注册的消息
sender ! ReconnectWorker(masterUrl)
} else {
logWarning(s"Got heartbeat from unregistered worker $workerId." +
" This worker was never registered, so ignoring the heartbeat.")
}
Worker与Master时序图
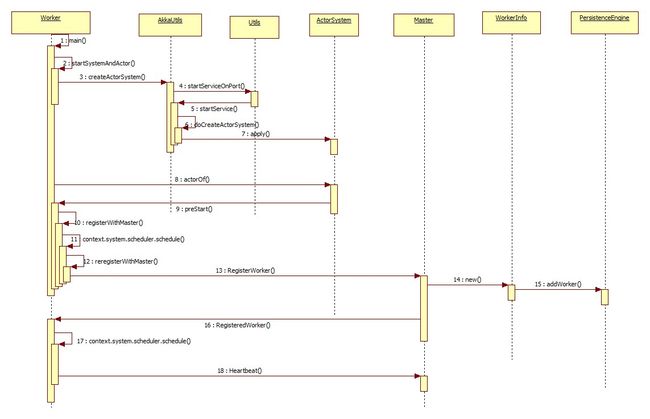
Master与Worker启动以后的大致的通信流程到此,接下来就是如何启动集群上的Executor 进程计算任务了。