字符编码的问题,每个程序员都会遇到,深入探索其背后的原理和机制,能让我们少走很多弯路。
1、历史简述
Unicode(万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
Unicode发展由非营利机构统一码联盟负责,该机构致力于让Unicode方案替换既有的字符编码方案。因为既有的方案往往空间非常有限,亦不适用于多语环境。
统一码联盟在1991年首次发布了The Unicode Standard。
在2005年,Unicode的第十万个字元被引入成为标准之一,该字元被用于马拉雅拉姆语。
2、编码方式
目前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示2的16次(即65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展。
最新(但未实际广泛使用)的统一码版本定义了16个辅助平面,两者合起来至少需要占据21位的编码空间,比3字节略少。但事实上辅助平面字符仍然占用4字节编码空间,与UCS-4保持一致。未来版本会涵盖UCS-4的所有字符。UCS-4是一个更大的尚未填充完全的31位字符集,加上恒为0的首位,共需占据32位,即4字节。理论上最多能表示2的31次方个字符,完全可以涵盖一切语言所用的符号。
3、UCS
通用字符集(Universal Character Set)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。
通用字符集包括了其他所有字符集。它保证了与其他字符集的双向兼容,即,如果你将任何文本字符串翻译到UCS格式,然后再翻译回原编码,你不会丢失任何信息。
UCS包含了已知语言的所有字符。除了拉丁语、希腊语、斯拉夫语、希伯来语、阿拉伯语、亚美尼亚语、格鲁吉亚语,还包括中文、日文、韩文这样的方块文字,UCS还包括大量的图形、印刷、数学、科学符号。
ISO/IEC 10646定义了一个31位的字符集。
并不是所有的系统都需要支持像组合字符这样的的先进机制。因此ISO 10646指定了如下三种实现级别:
级别1:不支持组合字符和谚文字母字符。
级别2:类似于级别1,但在某些文字中,允许一列固定的组合字符,因为如果没有最起码的几个组合字符,UCS就不能完整地表达这些语言。
级别3:支持所有的通用字符集字符,如,可以在任意一个字符上加上一个箭头或一个鼻音化符号.
历史上存在两个独立的尝试创立单一字符集的组织,即:
1、国际标准化组织(ISO)于1984年创建的ISO/IEC
2、统一码联盟
统一码联盟和ISO/IEC都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。
4、实现方式
Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。
Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
前面说到,Unicode采用2个字节来编码文件,但是如果一个仅包含7位ASCII字符的Unicode文件,每个字符使用2字节就浪费了一般的存储空间,其第一字节的8位始终为0,这是难以忍受。对于这种情况,可以使用UTF-8编码,这是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他Unicode字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1进行识别。
问题来了,UTF-8变长编码格式的出现是为了节省存储空间,变长导致了UTF-8的兼容性相应降低。
类似的,对未来会出现的需要4个字节的辅助平面字符和其他UCS-4扩充字符,2字节编码的UTF-16也需要通过一定的算法进行转换。
也就是说,UTF-16是为未来准备的变长编码格式。
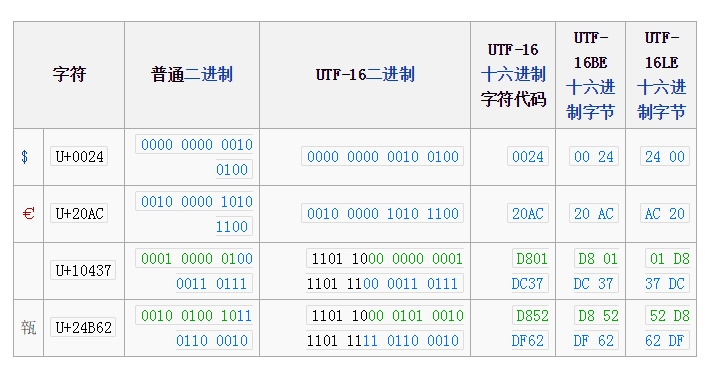
还有就是,在Mac和普通PC上,对于字节顺序的理解是不一致的。这时同一字节流可能会被解释为不同内容,如某字符为十六进制编码4E59,按两个字节拆分为4E和59,在Mac上读取时是从低字节开始,那么在Mac OS会认为此4E59编码为594E,找到的字符为“奎”,而在Windows上从高字节开始读取,则编码为U+4E59的字符为“乙”。就是说在Windows下以UTF-16编码保存一个字符“乙”,在Mac OS环境下打开会显示成“奎”。此类情况说明UTF-16的编码顺序若不加以人为定义就可能发生混淆。
于是在UTF-16编码实现方式中使用了大端序(Big-Endian,简写为UTF-16 BE)、小端序(Little-Endian,简写为UTF-16 LE)的概念,以及可附加的字节顺序记号解决方案,目前在PC机上的Windows系统和Linux系统对于UTF-16编码默认使用UTF-16 LE。目前在PC机上的Windows系统和Linux系统对于UTF-16编码默认使用UTF-16 LE。
在Windows XP附带的记事本,“另存为”对话框可以选择的四种编码方式除去非Unicode编码的ANSI(对于英文系统即ASCII编码),中文系统则为GB2312或Big5外,其余三种为“Unicode”(对应UTF-16 LE)、“Unicode big endian”(对应UTF-16 BE)和“UTF-8”。
5、UTF-8
UTF-8,是我们最经常看到的编码格式之一。前面已经简单介绍过,这是一种变长编码格式,变长的目的是节省存储空间。
UTF-8使用一至六个字节为每个字符编码(2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说最多四个字节)。
下面介绍其编码规则:
1、128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
2、带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文等则需要两个字节编码(Unicode范围由U+0080至U+07FF)。
3、其他基本多文种平面(BMP)中的字元(这包含了大部分常用字,如大部分的汉字)使用三个字节编码(Unicode范围由U+0800至U+FFFF)。
4、其他极少使用的Unicode 辅助平面的字元使用四至六字节编码。(Unicode范围由U+10000至U+1FFFFF使用四字节,Unicode范围由U+200000至U+3FFFFFF使用五字节,Unicode范围由U+4000000至U+7FFFFFFF使用六字节)。
对上述提及的第四种字元而言,UTF-8使用四至六个字节来编码似乎太耗费资源了。但UTF-8对所有常用的字元都可以用三个字节表示,而且它的另一种选择,UTF-16编码,对前述的第四种字符同样需要四个字节来编码,所以要决定UTF-8或UTF-16哪种编码比较有效率,还要视所使用的字元的分布范围而定。
下面来看看UTF-8具体怎么编码各种类型的字符:
1、单字节编码,字节由零开始:0zzzzzzz。(z取值0或1,下同)
2、两字节编码:(110yyyyy 10zzzzzz)第一个字节由110开始,接着的字节由10开始
3、三字节编码:(01110xxxx10yyyyyy 10zzzzzz)第一个字节由1110开始,接着的字节由10开始。
4、四字节编码:(11110www 10xxxxxx 10yyyyyy 10zzzzzz)将由11110开始,接着的字节由10开始

UTF-16
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表。即把Unicode字符集的抽象码位映射为16位长的整数,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
Unicode的编码空间从U+0000到+10FFFF,共有1,112,064个码位(code point)可用来映射字符. Unicode的编码空间可以划分为17个平面(plane),每个平面包含216(65,536)个码位。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从0016到1016,共计17个平面。第一个平面称为基本多语言平面(Basic Multilingual Plane, BMP),或称第零平面(Plane 0)。其他平面称为辅助平面(Supplementary Planes)。基本多语言平面内,从U+D800到U+DFFF之间的码位区段是永久保留不映射到Unicode字符。UTF-16就利用保留下来的0xD800-0xDFFF区段的码位来对辅助平面的字符的码位进行编码。
分平面来介绍UTF-16的实现方式:
1、第一个Unicode平面(码位从U+0000至U+FFFF)包含了最常用的字符。该平面被称为基本多语言平面,缩写为BMP(Basic Multilingual Plane, BMP)。UTF-16与UCS-2编码这个范围内的码位为16比特长的单个码元,数值等价于对应的码位. BMP中的这些码位是仅有的可以在UCS-2中表示的码位.
2、辅助平面(Supplementary Planes)中的码位,在UTF-16中被编码为一对16比特长的码元(即32bit,4Bytes),称作代理对(surrogate pair),具体方法是:
码位减去0x10000,得到的值的范围为20比特长的0..0xFFFFF.
高位的10比特的值(值的范围为0..0x3FF)被加上0xD800得到第一个码元或称作高位代理。
低位的10比特的值(值的范围也是0..0x3FF)被加上0xDC00得到第二个码元或称作低位代理(low surrogate),现在值的范围是0xDC00..0xDFFF.
算法可理解为:辅助平面中的码位从U+10000到U+10FFFF,共计FFFFF个,即220
=1,048,576个,需要20位来表示。如果用两个16位长的整数组成的序列来表示,第一个整数(称为前导代理)要容纳上述20位的前10位,第二个整数(称为后尾代理)容纳上述20位的后10位。还要能根据16位整数的值直接判明属于前导整数代理的值的范围(210=1024),还是后尾整数代理的值的范围(也是210
=1024)。因此,需要在基本多语言平面中保留不对应于Unicode字符的2048个码位,就足以容纳前导代理与后尾代理所需要的编码空间。这对于基本多语言平面总计65536个码位来说,仅占3.125%.
3、Unicode标准规定U+D800..U+DFFF的值不对应于任何字符.
参考资料:
https://zh.wikipedia.org/wiki/Unicode
https://zh.wikipedia.org/wiki/UTF-8
https://zh.wikipedia.org/wiki/UTF-16