Neil Zhu,ID Not_GOD,University AI 创始人 & Chief Scientist,致力于推进世界人工智能化进程。制定并实施 UAI 中长期增长战略和目标,带领团队快速成长为人工智能领域最专业的力量。
作为行业领导者,他和UAI一起在2014年创建了TASA(中国最早的人工智能社团), DL Center(深度学习知识中心全球价值网络),AI growth(行业智库培训)等,为中国的人工智能人才建设输送了大量的血液和养分。此外,他还参与或者举办过各类国际性的人工智能峰会和活动,产生了巨大的影响力,书写了60万字的人工智能精品技术内容,生产翻译了全球第一本深度学习入门书《神经网络与深度学习》,生产的内容被大量的专业垂直公众号和媒体转载与连载。曾经受邀为国内顶尖大学制定人工智能学习规划和教授人工智能前沿课程,均受学生和老师好评。
源地址
关于系统的介绍和如何进行索引的扩展参见 part 1 和 part 2。 本来我打算将全局查询和相关博客查询分开介绍的,可是刻意分开的难度也使得我花了很久来写这篇文章。
在 WordPress.com 有两种类型的基于 Elasticsearch 索引的查询:在所有博客上的全局查询和在一个博客内部的文章查询 {Global vs. Local}。超过 90% 的查询是局部的,大概有 23 million 每天,剩下的就是全局查询。
本文我们展示一些性能数据,并讨论采取的提升性能的权衡。
An aside about query testing
我们使用 JMeter 进行大部分的查询测试。因为我们在比较全局和局部查询,所以让一系列不同的查询运行并运行在大多数全索引上(尽管有时候进行的开发让这件事实际应用中并不可行)
总的来说,我们从搜索的log中随机采样用户的查询。对于局部查询,我们借助于从索引中伪随机地选择出来的发布文章运行相关发布文章的查询。当然也有一部分情况需要对查询进行手工修正(出于对采样技术的错误和偶然的坏查询类型的考虑)。产生好的混合查询是一门艺术和保证一切完好的整合。
A few mapping details
我已经将如何进行 WordPress 发布文章映射到 Elastic 文档进行了介绍(项目代码在这里),并且有一个关于多语言的处理方式的描述。这些内容并不跟我们下面要介绍的内容不相关,但要注意到这两点:
- 所有发布的文档是博客文档的子文档。博客文档记录了有关博客的元信息
- 子文档总是存放在和父文档相同的 shard 中。他们使用同样的路由值。这给出了一个巨大的优化途径。局部搜索可以使用查询路由来保证其执行在一个节点上,并只获取一个单一的 shard。
The global query
原初的计划是使用父博客文档来保存跟踪一些可以确定博客发布文章是否全局可搜的关于博客的元信息(是否公开可读,有成人内容,spam等)。通过使用博客文档,我们可以更新一个单一的文档,而不需要重新索引在博客中的所有文章。接着我们可以使用一个 has_parent filter在全局查询上。
然而,我们发现 parent/child filter 在扩展性上表现并不好。所有的父文档 id 必须存放进内容(60 million 的博客文档需要每个节点存放5.3GB)。Elasticsearch 可以使用的RAM是30GB,id cache 看起来可以保持,但是我们仍然发现在使用 has_parent filter 时查询更慢和服务器负载更高。下面是最终的 parent/child 性能测试结果(在一个 16 节点的 cluster上进行的):
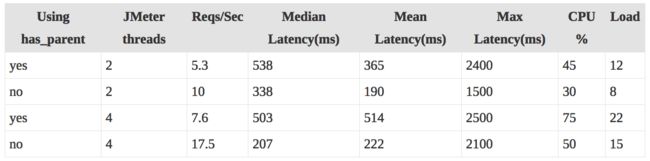
不使用 has_parent filter 节约了我们大量的服务器资源,也带来了困惑,因为这意味着我们需要更加频繁地进行 bulk 重索引。
最终我们的全局索引长这个样子:
POST global-*/post/_search
{
"query": {
"filtered": {
"query": {
"multi_match": {
"fields": ["content","title"],
"query": "Can I haz query?"
}
},
"filter": {
"and": [
{
"term": {
"lang": "en"
}
},
{
"and": [
{
"term": {
"spam": false
}
},
{
"term": {
"private": false
}
},
{
"term": {
"mature": false
}
}
]
}
]
}
}
}
}
elasticsearch 全局查询最后要知道的是:“FILTERS ARE EPIC”。如果你不理解这句嘶吼的话,最好去读读这篇,理解 filter 如何进行 cache 的。
Sidenote:在重读了这篇文章后,我意识到将 AND filter 改成 bool filter 可能会给性能带来一些提升。这也是写博客的好处。这个改变能够让我们的查询时候减半:

Global query performance with increasing numbers of shards
全局查询需要从所有的 shard 中得到的结果进行汇总,接着把这些结果搜集起来形成最终的结果。搜索存放在10个shard 上的10个结果需要在每个shard上进行查询,接着组合这100个结果得到最终的10个结果。更多的shard意味着在cluster上更多的处理,但也有更多的结果需要组合。这在我们开始进行 paging 的时候变得很有趣。为了获得遍布在10个shard上的搜索结果的90-100位需要组合1000个结果来得到最终的搜索结果。
我们在数百万个博客上进行了一些测试,通过改变shard的数量而限制 JMeter 线程数来进行测试。
这个实验的结果让我们得出下一步可以进行的尝试方向,最小化shard的数量。还可能通过提高 replication 来提升查询性能。
The local query
我们大多数的局部搜索用来发现相关的发布文章。我们执行一个 mlt_query 查询 和 multi_match 查询的组合来发送当前的发布文章找到最为相似的文章。对于一个标题为“The Best”内容是“This is the best post in the world”的发布文章,查询长这个样子:
POST global-0m-10m/post/_search?routing=12345
{
"query": {
"filtered": {
"query": {
"multi_match": {
"query": "The Best This is the best post in the world.",
"fields": ["mlt_content"]
}
},
"filter": {
"and": [
{
"term": {
"blog_id": 12345
}
},
{
"not": {
"term": {
"post_id": 3
}
}
}
]
}
}
}
}
看起来很简单,但也有很多有趣的优化可以探讨。
Routing
我们局部的查询使用搜索的路由参数限制搜索在单个的shard上。组织索引和shard使得整个博客总是在一个单独的shard上,这是最为重要的优化技术。不这样,我们便不能够记性扩展和处理百万级的查询,因为我们会浪费大量的循环搜索那些不包含或者极少的与搜索相关的文档。
Query Type
在上面的例子中,我们使用了 multi_match 查询。如果内容长一些(超过100词),我们可以使用 mlt_query。原初我们在所有查询上都使用 mlt_query 来加速查询并确保相关性。然而,使用 mlt_query 不会保证最终使用的查询拥有任何一个最终搜索词。很大程度上依赖于在发布文章中项的频数和在索引中的频数。将查询改成 multi_match 后大幅提升了我们查询的结果的相关性(通过点击率)
MLT API
我们开始构建相关的发布通过使用 MLT API 来运行查询。这样的话,我们仅仅能够发送 文档 id给 elasticsearch并信赖 elasticsearch 获得发布文章,分析并构造合适的 mlt_query 给我们约十倍的请求提升,并降低了查询的反应时间。

我们认识到获得原始的文档是最大的瓶颈。当然这个变化将大量的处理从elasticsearch移出到网络主机上,但网络主机比 elasticsearch 节点更加容易扩展(或至少是我们的系统团队更加擅长这点)
mlt_content field
这个查询变成一个单一字段 mlt_content而不是分开的标题和内容字段。搜索更少的字段会有一个显著的性能提升,并帮助我们搜索出现在不同的发布文章中不同的字段的。最新的 multi_match cross_fields 选项可能会有昂朱,但是我猜测应该没有单一字段的提升更有效。
我们也曾经存储了 mlt_content 字段,但是近期的工作已经确定了存储字段的方法并不能够提升 mlt_query 查询。
我们最终选择了 mlt_content 的历史过程也同样具有指导价值。我们在仍然使用 MLT API 的时候使用 mlt_content 字段并存储了它。刚开始时我们使用从 _source 中抽取的发布文章的标题和内容字段。转换为一个存储的 mlt_content 字段降低了在创建查询前获得文档的平均时间从 500 ms 到 100 ms。最后,这些说明了不能够在我们的应用中起到明显的效果,但是仍然值得其他使用 MLT API 的用户关注。
Improving relevancy with rescoring
我们使用了一组测试来提升我们的相关发布文章的相关度。我们这里的策略已经大部分被用于 mlt_query/multi_match 查询作为我们的基本查询,接着使用 重计分 rescoring 来调整查询结果。例如我们基于那些已经喜欢了当前的发布文章的人和他们喜欢的文章是否相似的共性构建一个查询微小地重排了我们前50个结果。使用重计分选项运行查询基本对于查询性能没有影响,但是却给了相关发布文章的ctr不错的提升。
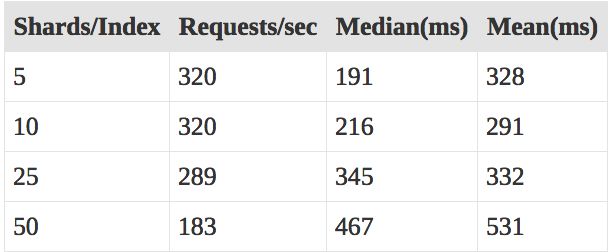
Shard size and local query performance
尽管全局搜索在更少数量却更大的shard环境上性能最佳,局部搜索却在shard更小的情况下执行的更快。这里是一些比较实验的数据,比较了不同的shard数量下执行 mlt_query 搜索:

每个shard中更少的数据(更多的shard数)对查询时间有显著的影响。
Final trade off of shard size and query performance
基于全局和局部查询的结果,我们决定使用 25 个shard/index 作为对两种查询的一种平衡。这是更为灵活的决定,但是对我们的场景确实起到了很好的效果。但是在使用这个方式 6 个月后,我们决定我们会终止太多慢(超过1秒)的查询。
我猜测这个系列永远会进行下去:重建索引来增加更多的(6-7倍)文档,同时降低查询的时间,加速所有的查询。我们将99%的查询从1.7 m降到800 ms,中位数时间从180ms降到50ms。所有这些提升都是在文档数从800million增加到5.5billion的情形下达到的。期待下一篇吧。
https://blog.codecentric.de/en/2014/05/elasticsearch-indexing-performance-cheatsheet/