软件以及工具
软件
| jdk1.7.0 | hadoop-2.7.3 | hive-2.1.1 |
| hbase-1.2.5 | zookeeper-3.4.10 | phoenix-4.10.0 |
获取软件包请点击
工具
-
文件上传工具
Windows推荐secureCRT下使用rz、sz上传下载文件,rz、sz需要下载软件包lrzsz
Mac同样也可以使用lrzsz 具体配置请点击
-
远程文件修改工具
Sublime Text或者NotePad++ 安装SFTP插件,Sublime Text配置SFTP插件请点击
配置免密登录
-
生成密钥
ssh-keygen -t rsa
-
将公钥复制到远程服务器上
ssh-copy-id username@remote-server
-
登录服务器
能不能更优雅的登录服务器呢?其实按照如下的配置便可以完成
//编辑config文件也可以编辑/etc/ssh/ssh_config,只不过/etc/ssh/ssh_config全局的
vim ~/.ssh/config
//如果scp-copy-id命令报错则修改config权限sudo chmod 600 config
//新增如下配置
Host server
HostName server.com
User username
IdentityFile ~/.ssh/id_rsa
输入ssh server登录
配置单节点Hadoop
-
修改主机名
vim /etc/sysconfig/network //添加 HOSTNAME=master 配置host vim /etc/hosts 192.168.133.138 master -
创建hadoop用户
useradd hadoop(接下来的操作全在hadoop用户下完成) -
创建存放软件目录
修改目录权限 sudo chown -R hadoop:hadoop /usr/local /usr/local/bigdata/software(软件) /usr/local/bigdata/tools(软件安装包) -
服务器配置ssh免密码登录
ssh-keygen -t rsa ssh-copy-id slave 免密码登录时为了执行start-all.sh等命令的时候,只要在一个节点(master)执行后其他免密码 登录的节点也会启动相关进程 -
设置sudo免密码
//编辑sudoers文件 vim /etc/sudoers //添加 hadoop ALL=(ALL) NOPASSWD: ALL -
关闭防火墙(更多配置CentOS7防火墙firewalld配置请点击)
systemctl stop firewalld.service//重启后失效 systemctl disable firewalld.service//禁用防火墙
安装JDK
解压
切换到tools目录下
tar -zxvf jdk-7-linux-x64.tar.gz -C ../software
配置环境变量
vim /etc/profile
export JAVA_HOMT=/usr/local/bigdata/software/jdk1.7.0
export PATH=$JAVA_HOMT/bin:$PATH
source /etc/profile
安装hadoop
解压
切换到tools目录下
tar -zxvf hadoop-2.7.3.tar.gz -C ../software
环境配置
使用sublime Text修改远程文件
- hadoop-env.sh 配置Hadoop Java运行环境
export JAVA_HOME=/usr/local/bigdata/software/jdk1.7.0
- core-site.xml
在/usr/local/bigdata/software/hadoop-2.7.3新建data目录
fs.defaultFS配置项表示NameNode在master节点
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/usr/local/bigdata/software/hadoop-2.7.3/data/temp
- hdfs-site.xml
dfs.replication
1
- mapred-site.xml
mapreduce.framework.name
yarn
- yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
启动Hadoop
启动HDFS
-
首先格式化NameNode
hadoop namenode -format -
执行start-dfs.sh
Starting namenodes on [master] master: starting namenode, logging to /usr/local/bigdata/software/hadoop-2.7.3/logs/hadoop-hadoop-namenode-master.out localhost: starting datanode, logging to /usr/local/bigdata/software/hadoop-2.7.3/logs/hadoop-hadoop-datanode-master.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/local/bigdata/software/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-master.out -
通过jps验证启动成功
输入jps命令后你会看到下面的进程: 15692 DataNode 15559 NameNode 16004 Jps 15861 SecondaryNameNode -
访问http://192.168.133.136:50070验证启动成功
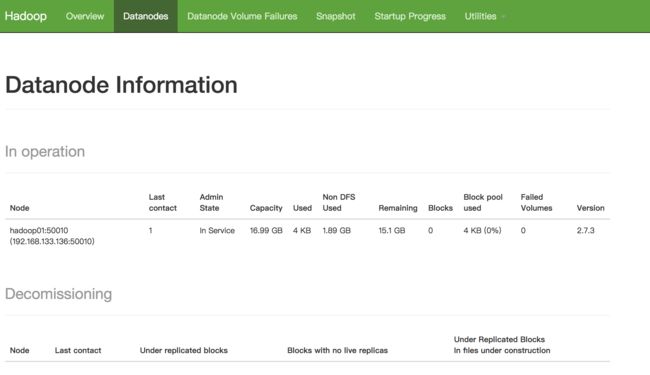
启动YARN
执行start-yarn.sh
-
通过jps验证启动成功,新增NodeManager和ResourceManager
输入jps命令后你会看到下面的进程: 18051 SecondaryNameNode 18654 Jps 17751 NameNode 18335 NodeManager 17884 DataNode 18215 ResourceManager -
访问http://192.168.133.136:8088界面查看任务的运行情况
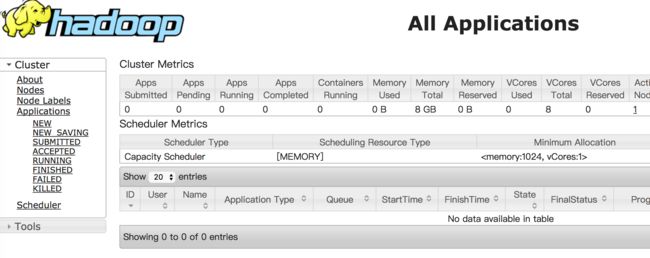
备注:其实我们可以使用start-all.sh来同时启动HDFS和YARN,使用stop-all.sh关闭
运行单词统计的例子
hdfs dfs -mkdir -p /user/hadoop/mr/wc/in
hdfs dfs -put /etc/profile /user/hadoop/mr/wc/in
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /user/hadoop/mr/wc/in/profile user/hadoop/mr/wc/out
hadoop fs -ls user/hadoop/mr/wc/out
配置Hadoop集群
Hadoop集群集群的配置和单节点Hadoop配置基本差不多,我们按照单节点Hadoop配置的方法,重命名机器名,绑定host,配置ssh,关闭防火墙等。现在需要列出集群的配置文件的不同,下面是集群可以正常启动基本配置。
备注:本教程配置为1个master和一个slave
环境配置
- slaves文件
将作为DataNode的主机名写入该文件,本教程master节点仅作为NameNode使用,所以只删除原有内容添加内容:
slave
这个表示有1个NameNode
- hadoop-env.sh
export JAVA_HOME=/usr/local/bigdata/software/jdk1.7.0
- core-site.xml
fs.defaultFS配置项表示NameNode在master节点
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/usr/local/bigdata/software/hadoop-2.7.3/data/temp
- 新增masters文件配置SecondaryNameNode
测试发现没有masters文件只需配置hdfs-site.xml便可以指定SN
表示slave为SecondaryNameNode,同时还需配置hdfs-site.xml
slave
- hdfs-site.xml
dfs.namenode.secondary.http-address配置SecondaryNameNode请求地址
dfs.namenode.secondary.http-address
slave:50090
dfs.replication表示有几个副本,slaves文件中配置的slaves个数
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/bigdata/software/hadoop-2.7.3/data/temp/dfs/name
dfs.datanode.data.dir
file:/usr/local/bigdata/software/hadoop-2.7.3/data/temp/dfs/data
- mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
- yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
备注:配完master的配置文件后,将jdk和hadoop拷贝(scp)到别的机器
启动Hadoop集群
-
在mster机器下,执行start-all.sh命令,启动后执行jps我们会看到下面的进程
17082 Jps 16303 NameNode 16650 ResourceManager 在slave机器下,启动后执行jps我们会看到下面的进程
3147 SecondaryNameNode
3146 NodeManager
3036 DataNode
3335 Jps-
同时也可以在任何机器上执行hdfs dfsadmin -report查看集群状态
[hadoop@slave data]$ hdfs dfsadmin -report Configured Capacity: 18238930944 (16.99 GB) Present Capacity: 15099506688 (14.06 GB) DFS Remaining: 15099498496 (14.06 GB) DFS Used: 8192 (8 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (1): Name: 192.168.133.137:50010 (slave) Hostname: slave Decommission Status : Normal Configured Capacity: 18238930944 (16.99 GB) DFS Used: 8192 (8 KB) Non DFS Used: 3139424256 (2.92 GB) DFS Remaining: 15099498496 (14.06 GB) DFS Used%: 0.00% DFS Remaining%: 82.79% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sat Apr 08 02:12:37 EDT 2017
备注:集群启动成功后我们同样也可运行单词统计的例子
遇到的问题:
一定要关闭机器的防火墙,保证机器间的互通
当遇到NameNode无法启动时,删除/usr/local/bigdata/software/hadoop-2.7.3/data/temp重新mkdir下面的文件,然后执行hadoop namenode -format、start-all.sh