本文将主要讨论两个Topic:Stage的划分过程和Task数据本地性
引子
前面的文章中我们已经分析了Spark应用程序即Application的注册以及Executors的启动注册流程,即计算资源已经分配完成(粗粒度的资源分配方式),换句话说Driver端的代码已经运行完成(SparkConf、SparkContext),接下来就是运行用户编写的业务逻辑代码。
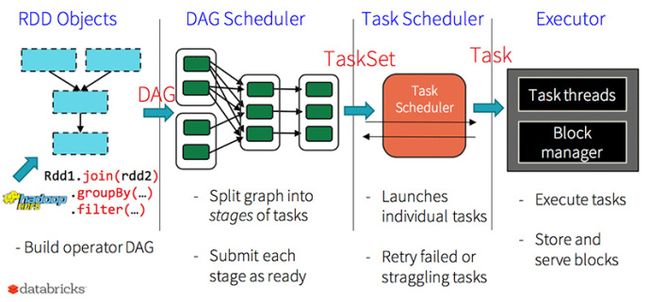
Spark中对RDD的操作大体上可以分为transformation级别的操作和action级别的操作,transformation是lazy级别的操作,action操作(count、collect等)会触发具体job的执行,而每个job又会被划分成一个或者多个Stage,后面的Stage会依赖前面的Stage,而Stage划分的依据就是是否为宽依赖(Spark中RDD的依赖关系分成宽依赖和窄依赖),所有的Stage会形成一个有向无环图(DAG),最后依据Task的数据本地性将Task发送到指定的Executor上运行,下面我们就详细分析这一过程。
Stage的划分
首先从一个Action级别的操作开始,此处以collect为例:
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
可以看到执行了SparkContext的runJob()方法:
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
内部调用了DAGScheduler的runJob方法:
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
// 记录Job的开始时间
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
waiter.awaitResult() match {
case JobSucceeded =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case JobFailed(exception: Exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
内部调用了submitJob方法用来向scheduler提交Job,并返回一个JobWaiter,使用JobWaiter的awaitResult()方法来等待DAGScheduler执行完成,并且当tasks执行完毕后将执行的结果返回给具体的resultHandler,下面我们就来看一下submitJob()方法:
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
// 获得jobId
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
// 实例化JobWaiter
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
// 可以看到,确实是返回了JobWaiter
waiter
}
DAGScheduler内部有一个DAGSchedulerEventProcessLoop(消息循环器),他继承自EventLoop,简单的说每个消息循环器中会有一个消息队列:LinkedBlockingDeque[E],E就代表具体EventLoop子类所要处理的消息的类型,DAGSchedulerEventProcessLoop具体处理的消息类型是DAGSchedulerEvent(当然他有许多子类型),每个消息循环器中会开辟一条新的线程来循环处理消息队列中的消息,DAGScheduler实例化的时候会创建一个消息循环器(eventProcessLoop),并调用了eventProcessLoop的start方法(这个方法的调用隐藏在DAGScheduler类的最后一行),而start方法的作用就是开启上面提到的那条线程开始处理消息队列中的消息,当我们使用eventProcessLoop的post方法将JobSubmitted(该消息的类型就继承自DAGSchedulerEvent)消息放入到消息队列中后,消息循环器中的线程会从队列中拿出这条消息,然后执行消息循环器的onReceive(event)方法,而在DAGSchedulerEventProcessLoop中onReceive方法内部执行的是doOnReceive方法:
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}
而doOnReceive方法在接收到具体的event后会用模式匹配来匹配收到的消息的具体类型,这里接收到的是JobSubmitted类型的消息,处理如下:
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case ...
}
可以看到执行的是DAGScheduler的handleJobSubmitted方法:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
// 实例化ResultStage
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
submitWaitingStages()
}
下面我们逐步分析:
private def newResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
getParentStagesAndId
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
val parentStages = getParentStages(rdd, firstJobId)
val id = nextStageId.getAndIncrement()
(parentStages, id)
}
getParentStages
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
// 实例化一个空的集合用来存储ResultStage的父Stage
val parents = new HashSet[Stage]
// 实例化一个空的集合用来存储已经遍历过的RDD
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
// 防止递归调用的时候出现StackOverflowError异常
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
// Kind of ugly: need to register RDDs with the cache here since
// we can't do it in its constructor because # of partitions is unknown
// 循环遍历RDD的所有依赖关系
for (dep <- r.dependencies) {
dep match {
// 如果是宽依赖
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
// 如果是窄依赖就将依赖的RDD压入到waitingForVisit栈中继续便利
case _ =>
waitingForVisit.push(dep.rdd)
}
}
}
}
// 将最后一个RDD放入到等待visit的Stack中
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
// 如果waitingForVisit不为空就将栈顶的RDD弹出,并使用上面定义的visit()进行处理
visit(waitingForVisit.pop())
}
// 最后返回ResultStage的所有父Stages组成的List
parents.toList
}
首先判断该RDD(也就是最后一个RDD)和依赖的父RDD之间是宽依赖(ShuffleDependency)还是窄依赖(NarrowDependency的子类)。可以看到这里是通过RDD的dependencies方法来获取依赖关系的:
final def dependencies: Seq[Dependency[_]] = {
checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse {
if (dependencies_ == null) {
dependencies_ = getDependencies
}
dependencies_
}
}
因为是第一次提交,所以直接调用getDependencies方法,而map操作产生的MapPartitionsRDD并没有复写该方法,所以调用的是抽象类RDD的getDependencies方法:
protected def getDependencies: Seq[Dependency[_]] = deps
而这里的deps就是默认构造方法中的deps:
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
而重载的构造方法中默认就是实例化了OneToOneDependency即默认是窄依赖的:
def this(@transient oneParent: RDD[_]) =
this(oneParent.context , List(new OneToOneDependency(oneParent)))
再例如reduceByKey操作最后生成的是ShuffleRDD,而ShuffleRDD复写了getDependencies方法:
override def getDependencies: Seq[Dependency[_]] = {
List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
}
很明显可以看出是宽依赖。
让我们再重新回到之前的判断中,如果是窄依赖就把依赖的RDD压入到栈中;如果是宽依赖就使用getShuffleMapStage方法获得父Stage并放入到parents中,下面来看getShuffleMapStage方法:
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
// 首先根据shuffleId判断shuffleToMapStage是否存在Stage,如果存在就直接返回
case Some(stage) => stage
case None =>
// We are going to register ancestor shuffle dependencies
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
// Then register current shuffleDep
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
首先根据shuffleId判断shuffleToMapStage是否存在Stage,如果存在就直接返回;如果不存在,也就是说还没有注册到shuffleToMapStage中,会执行如下两个步骤:
- 获得祖先的依赖关系为宽依赖的依赖(从右向左查找)然后一次创建并向shuffleToMapStage中注册ShuffleStage(从左向右创建)
- 创建并注册当前的Shuffle Stage
我们先来看getAncestorShuffleDependencies这个方法:
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
val parents = new Stack[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
waitingForVisit.push(dep.rdd)
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents
}
和getParentStages类似,不同的是这里的parents保存的是父依赖关系中的ShuffleDependency,下面就是循环遍历这些ShuffleDependency组成的集合执行newOrUsedShuffleStage(dep, firstJobId)操作,dep就是集合中的一个ShuffleDependency,下面我们来看这个newOrUsedShuffleStage方法:
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
// 即将创建的Stage的最后一个RDD,也就是最右侧的RDD
val rdd = shuffleDep.rdd
// Tasks的个数,由此可见,Stage的并行度是由该Stage内的最后一个RDD的partitions的个数所决定的
val numTasks = rdd.partitions.length
// 实例化ShuffleMapStage
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
(0 until locs.length).foreach { i =>
if (locs(i) ne null) {
// locs(i) will be null if missing
stage.addOutputLoc(i, locs(i))
}
}
} else {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
下面我们看一下newShuffleMapStage的具体实现:
private def newShuffleMapStage(
rdd: RDD[_],
numTasks: Int,
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int,
callSite: CallSite): ShuffleMapStage = {
// 可以看到此处又是调用的getParentStagesAndId函数,然后重复上述的步骤
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, firstJobId)
val stage: ShuffleMapStage = new ShuffleMapStage(id, rdd, numTasks, parentStages,
firstJobId, callSite, shuffleDep)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(firstJobId, stage)
stage
}
可以看到内部又调用了getParentStagesAndId函数,然后再次重复上述的步骤,至此我们可以得出一个结论:即最左侧的Stage最先被创建,然后从左向右一次创建各个Stage(左边的Stage的id比右边的小,从0开始),并且后面的Stage保存有上一个Stage(也可能是多个)的引用。然后我们回到newOrUsedShuffleStage方法中(限于篇幅不再重复贴出上面的源码,大家可以使用自己的IDEA或者Eclipse查看源码,或者向上滑动至newOrUsedShuffleStage方法的部分),下面就是MapOutputTracker相关的逻辑代码,这里先简单的提议下,以后会专门对MapOutputTracker进行分析,下面就是补充的内容:
简单的说就是:后面的Task可以通过Driver端的MapOutputTracker也就是MapOutputTrackerMaster获得ShuffleMapTask的运行结果的元数据信息(包括数据存放的位置、大小等),然后根据获得的元数据信息获取需要处理的数据,而这里的逻辑大家可以看成是对这些元数据信息的占位的作用
然后将最后一个ShuffleStage(为什么是最后一个ShuffleStage,因为我们上面已经得出了结论,Stage是从左向右一次创建的,所以这里是最后一个ShuffleStage,当然也可能是多个)最终返回到newResultStage方法中,由于离得太远,我们再次贴出newResultStage方法的源码:
private def newResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
下面终于到了创建ResultStage这一步了,创建完成ResultStage后将其返回给handleJobSubmitted方法中的finalStage,至此一个完整的DAG(有向无环图)就正式完成了。
Task数据本地性算法
我们继续跟踪handleJobSubmitted方法:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
// 打日志
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
// 记录job提交的事件
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 提交finalStage
submitStage(finalStage)
submitWaitingStages()
}
接下例就是实例化ActiveJob,然后通过submitStage方法提交我们上一部分的到的finalStage:
private def submitStage(stage: Stage) {
// 得到jobId
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 确保当前的Stage没有未完成计算的父Stage,也不是正在运行的Stage,而且也没有提示提交失败
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
上述源码说明提交Tasks的时候也是先提交父Stage的Tasks,即前面的Stage计算完成后才能计算后面的Stage,明白这一点之后我们进入到submitMissingTasks方法(此处我们只选取关键部分的代码):
private def submitMissingTasks(stage: Stage, jobId: Int) {
...
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
val job = s.activeJob.get
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
}
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times.
// Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast
// the serialized copy of the RDD and for each task we will deserialize it, which means each
// task gets a different copy of the RDD. This provides stronger isolation between tasks that
// might modify state of objects referenced in their closures. This is necessary in Hadoop
// where the JobConf/Configuration object is not thread-safe.
// 如果是ShuffleMapStage就将其中RDD,及其依赖关系广播出去;如果是ResultStage
// 就将其中的RDD及其计算方法func广播出去。由此也可以看出真正触发计算的是ResultStage
// ShuffleMapStage不会触发计算。
var taskBinary: Broadcast[Array[Byte]] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array()
case stage: ResultStage =>
closureSerializer.serialize((stage.rdd, stage.func): AnyRef).array()
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
}
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.internalAccumulators)
}
case stage: ResultStage =>
val job = stage.activeJob.get
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, stage.internalAccumulators)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
stage.pendingPartitions ++= tasks.map(_.partitionId)
logDebug("New pending partitions: " + stage.pendingPartitions)
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
}
}
taskIdToLocations就是用来保存partition的id到TaskLocation映射关系的,我们进入到getPreferredLocs方法:
private[spark]
def getPreferredLocs(rdd: RDD[_], partition: Int): Seq[TaskLocation] = {
getPreferredLocsInternal(rdd, partition, new HashSet)
}
继续追踪getPreferredLocsInternal:
private def getPreferredLocsInternal(
rdd: RDD[_],
partition: Int,
visited: HashSet[(RDD[_], Int)]): Seq[TaskLocation] = {
// If the partition has already been visited, no need to re-visit.
// This avoids exponential path exploration. SPARK-695
if (!visited.add((rdd, partition))) {
// Nil has already been returned for previously visited partitions.
return Nil
}
// 如果partition被缓存了,直接返回缓存的信息
// If the partition is cached, return the cache locations
val cached = getCacheLocs(rdd)(partition)
if (cached.nonEmpty) {
return cached
}
// 如果该RDD是从外部读取数据,则执行RDD的preferredLocations方法
// If the RDD has some placement preferences (as is the case for input RDDs), get those
val rddPrefs = rdd.preferredLocations(rdd.partitions(partition)).toList
if (rddPrefs.nonEmpty) {
return rddPrefs.map(TaskLocation(_))
}
// 如果是窄依赖,就一直递归调用查找该依赖关系上的第一个RDD的Location作为该locs
// If the RDD has narrow dependencies, pick the first partition of the first narrow dependency
// that has any placement preferences. Ideally we would choose based on transfer sizes,
// but this will do for now.
rdd.dependencies.foreach {
case n: NarrowDependency[_] =>
for (inPart <- n.getParents(partition)) {
val locs = getPreferredLocsInternal(n.rdd, inPart, visited)
if (locs != Nil) {
return locs
}
}
case _ =>
}
Nil
}
我们进入到RDD的preferredLocations方法:
final def preferredLocations(split: Partition): Seq[String] = {
checkpointRDD.map(_.getPreferredLocations(split)).getOrElse {
getPreferredLocations(split)
}
}
可以看见内部调用的是RDD的getPreferredLocations方法:
/**
* Optionally overridden by subclasses to specify placement preferences.
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
很显然最后具体的数据本地性计算是被子RDD而具体实现的,下面是具体实现该方法的RDD列表,具体的实现方法不再讨论,有兴趣的朋友可以研究一下,如果开发者需要开发自定义的RDD从外部数据源中读取数据,为了保证Task的数据本地性就必须实现该RDD的getPreferredLocations方法。

在获取了数据本地性信息之后,我们就根据Stage的类型来生成ShuffleMapTask和ResultTask,然后使用TaskSet进行封装,最后调用TaskScheduler的submitTasks方法提交具体的TaskSet。
本文参照的是Spark 1.6.3版本的源码,同时给出Spark 2.1.0版本的连接:
Spark 1.6.3 源码
Spark 2.1.0 源码
本文为原创,欢迎转载,转载请注明出处、作者,谢谢!