SOFA
Scalable Open Financial Architecture是蚂蚁金服自主研发的金融级分布式中间件,包含了构建金融级云原生架构所需的各个组件,是在金融场景里锤炼出来的最佳实践。
SOFATracer 是一个用于分布式系统调用跟踪的组件,通过统一的 TraceId 将调用链路中的各种网络调用情况以日志的方式记录下来,以达到透视化网络调用的目的,这些链路数据可用于故障的快速发现,服务治理等。
本文为《剖析 | SOFATracer 框架》第四篇,本篇作者米麒麟,来自陆金所。
《剖析 | SOFATracer 框架》系列由 SOFA 团队和源码爱好者们出品,目前领取已经完成,感谢大家的参与。
SOFATracer: https://github.com/alipay/sofa-tracer

前言
由于分布式链路追踪涉及到调用的每个环节,而每个环节都会产生大量的数据,为了存储这种数据,可能需要大量的成本,另外在实际的生产过程中并非所有数据都是值得关注的。
基于这些原因,SOFATracer 提供链路数据采样功能特性,一方面可以节约 I/O 磁盘空间,另一方面需要把无关数据直接过滤筛选。目前 SOFATracer 内置两种采样策略,一种是基于固定比率的采样,另一种是基于用户扩展实现的自定义采样。自定义采样模式将 SofaTracerSpan 实例作为采样计算的条件,用户可以基于此实现自行扩展自定义的采样规则。
本篇文章主要介绍 SOFATracer 数据采样策略原理,通过剖析源码实现详细讲述采样规则算法。
Dapper 论文中的采样模型与策略
跟踪采样模型
每个请求都会利用到大量服务器高吞吐量的线上服务,这是对有效跟踪最主要的需求之一。这种情况需要生成大量的跟踪数据,并且他们对性能的影响是最敏感的。延迟和吞吐量带来的损失在把采样率调整到小于1/16之后就能全部在实验误差范围内。
在实践中,我们发现即便采样率调整到 1/1024 仍然是有足够量的跟踪数据用来跟踪大量的服务。保持链路跟踪系统的性能损耗基线在一个非常低的水平是很重要的,因为它为那些应用提供了一个宽松的环境使用完整的 Annotation API 而无惧性能损失。使用较低的采样率还有额外好处,可以让持久化到硬盘中的跟踪数据在垃圾回收机制处理之前保留更长时间,这样为链路跟踪系统的收集组件提供更多灵活性。
分布式链路跟踪系统中任何给定进程的消耗和每个进程单位时间的跟踪采样率成正比。然而,在较低的采样率和较低的传输负载下可能会导致错过重要事件,而想用较高的采样率就需要能接受的相应的性能损耗。我们在部署可变采样的过程中,参数化配置采样率时,不是使用一个统一的采样方案,而是使用一个采样期望率来标识单位时间内采样的追踪。这样一来,低流量低负载会自动提高采样率,而在高流量高负载的情况下会降低采样率,使损耗一直保持在控制之内。实际使用的采样率会随着跟踪本身记录下来,这有利于从跟踪数据里准确分析排查。
跟踪采样策略
要真正做到应用级别的透明,我们需要把核心跟踪代码做的很轻巧,然后把它植入到那些无所不在的公共组件中,比如线程调用、控制流以及 RPC 库。使用自适应的采样率可以使链路跟踪系统变得可伸缩,并且降低性能损耗。链路跟踪系统的实现要求性能低损耗,尤其在生产环境中不能影响到核心业务的性能,也不可能每次请求都跟踪,所以要进行采样,每个应用和服务可以自己设置采样率。采样率应该是在每个应用自己的配置里设置的,这样每个应用可以动态调整,特别是应用刚上线时可以适当调高采样率。一般在系统峰值流量很大的情况下,只需要采样其中很小一部分请求,例如 1/1000 的采样率,即分布式跟踪系统只会在 1000 次请求中采样其中的某一次。
在 Dapper 论文中强调了数据采样的重要性,如果将每条埋点数据都刷新到磁盘上会增大链路追踪框架对原有业务性能的影响。如果采样率太低,可能会导致一些重要数据的丢失。 论文中提到如果在高并发情况下 1/1024 的采样率是足够的,也不必担心重要事件数据的丢失。因为在高并发环境下,一个异常数据出现一次,那么就会出现1000 次。 然而在并发量不是很多的系统,并且对数据极为敏感时需要让业务开发人员手动设置采样率。
对于高吞吐量服务,积极采样并不妨碍最重要的分析。如果一个显著的操作在系统中出现一次,他就会出现上千次。低吞吐量服务可以负担得起跟踪每一个请求。这是促使我们下决心使用自适应采样率的原因。为了维持物质资源的需求和渐增的吞吐要求之间的灵活性,我们在收集系统自身上增加了额外的采样率支持。
如果整个跟踪过程和收集系统只使用一个采样率参数确实会简单一些,但是这就不能应对快速调整在所有部署节点上的运行期采样率配置的这个要求。我们选择了运行期采样率,这样就可以优雅的去掉我们无法写入到仓库中的多余数据。我们还可以通过调节收集系统中的二级采样率系数来调整这个运行期采样率。Dapper 的管道维护变得更容易,因为我们可以通过修改二级采样率的配置,直接增加或减少全局覆盖率和写入速度。
SOFATracer 的采样源码剖析
SOFATracer 提供链路数据采样功能特性,支持两种采样策略:基于固定采样率的采样模式和基于用户扩展实现的自定义采样模式。
采样接口模型
SOFATracer 提供定义链路追踪数据采样模式接口 com.alipay.common.tracer.core.samplers.Sampler,此接口 sample 方法通过 SofaTracerSpan 实例参数作为采样计算基础条件决定链路是否采样,实现丰富的数据采样规则。
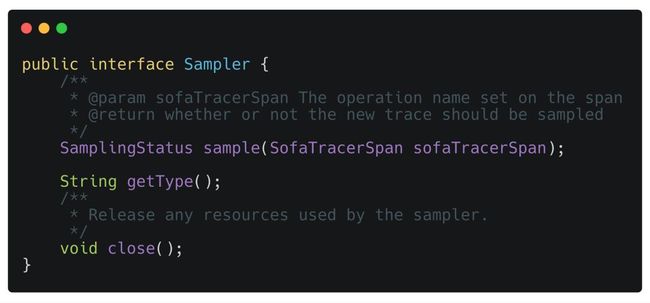
SOFATracer 基于 com.alipay.common.tracer.core.samplers.SamplerFactory 生成的采样器执行链路数据采样基本流程:
构建链路追踪器,通过采样器工厂 SamplerFactory 根据自定义采样规则实现类全限定名配置生成指定策略采样器 Sampler,其中基于用户扩展实现的采样模式优先级高,默认采样策略为基于固定采样率的采样计算规则;
Reporter 数据上报 reportSpan 或者链路跨度 SofaTracerSpan 启动调用采样器 sample 方法检查链路是否需要采样,获取采样状态 SamplingStatus 是否采样标识 isSampled。
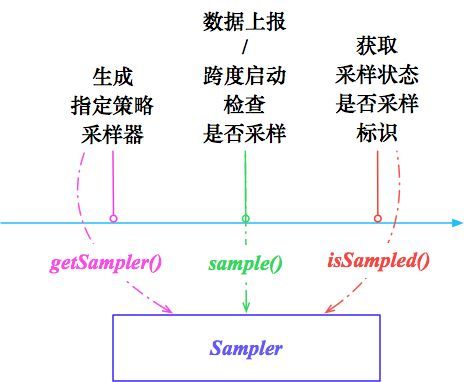
采样器的初始化
上面分析到,采样策略实例是通过 SamplerFactory 来创建的,SamplerFactory 中提供了一个 getSampler 方法用于获取采样器:
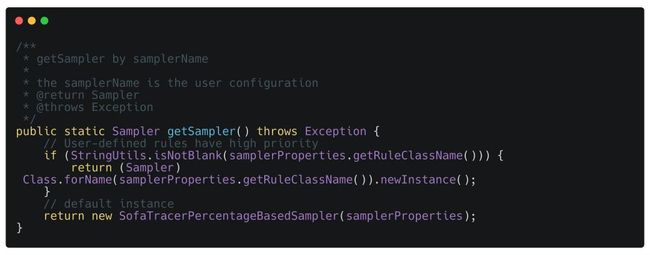
从代码片段来看,用户自定义的采样策略将会优先被加载,如果在配置文件中没有找到自定义的 ruleClassName ,则构建默认的基于固定采样率的采样器。SamplerProperties 是采样相关的配置属性,默认提供的基于固定比率的采样率是 100%,即默认情况下,所有的 Span 数据都会被记录到日志文件中。关于具体配置,在下文案例中会有详细介绍。
采样计算
采样是对于整条链路来说的,也就是说从 RootSpan 被创建开始,就已经决定了当前链路数据是否会被记录了。在 SofaTracer 类中,Sampler 实例作为成员变量存在,并且被设置为 final,也就是当构建好 SofaTracer 实例之后,采样策略就不会被改变。当 Sampler 采样器绑定到 SofaTracer 实例之后,SofaTracer 对于产生的 Span 数据的落盘行为都会依赖采样器的计算结果(针对某一条链路而言)。
SOFATracer 构建 Span 区别于 OpenTracing 规范中基于 SpanBuilder#start 开始一个新的 Span 的定义:
基于 OpenTracing 规范的实现,SofaTracerSpanBuilder#start
基于 SofaTracerSpanContext 构建
对于第一种,会在 start 方法中实现计算,然后设置到 sofaTracerSpanContext 用于向下游链路中进行透传。下面是第一种情况下计算当前 Span 是否需要采样的逻辑:
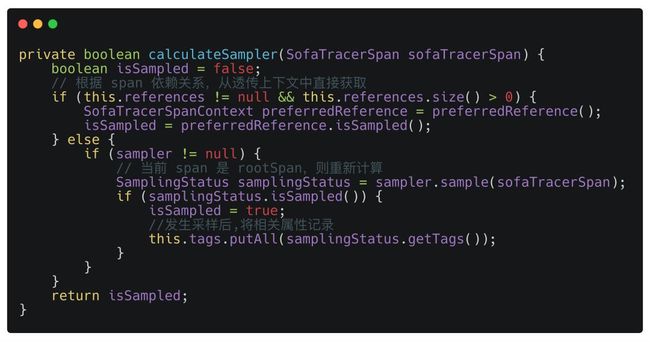
第二种情况下是基于 SofaTracerSpanContext 构建,SOFATracer 中 SofaTracerSpanContext 的构造函数默认会设置为不采样,那么对于这种情况,SOFATracer 会将采样计算延迟到 Span 上报时进行,此时计算的条件是 SofaTracer 中有采样器存在并且当前 Span 必须是 rootSpan :

采样标记透传
SOFATracer 在进行跨进程数据透传时,会将采样标记放在透传数据中,随着链路数据一直向下游进行透传。采样标记的 key 为 X-B3-Sampled。当下游服务通过此 key 解析出采样标记时,会直接在当前服务中使用此采样标记,而不用再去重新计算。
采样策略实现
SOFATracer 默认采样策略使用基于固定采样率通过 BitSet 底层实现的采样模式 SofaTracerPercentageBasedSampler,采样计算规则核心实现入口:

SofaTracerPercentageBasedSampler 基于固定采样比率采用时间复杂度为 O(N) 的蓄水池采样算法 Reservoir Sampling 构建随机 BitSet 检查是否采样。蓄水池采样算法从包含 n 个项目的集合 S 中选取 k 个样本,其中 n 为一很大或未知的数量,具体采样步骤包括:
从集合 S 中抽取首 k 项放入「水塘」中
对于每一个 S[j] 项(j ≥ k):
1)随机产生一个范围从 0 到 j 的整数 r
2)若 r < k 则把水塘中的第 r 项换成 S[j] 项
SofaTracerPercentageBasedSampler 基于蓄水池采样算法创建随机 BitSet 来源 Stack Overflow:

采样使用示例
使用 SOFATracer 的采样能力基于 tracer-sample-with-springmvc 工程,除 application.properties 之外,其他均相同。
固定采样率模式
SOFATracer 提供基于固定采样率的采样实现,采样模式需设置为 PercentageBasedSampler 。当 com.alipay.sofa.tracer.samplerName=PercentageBasedSampler 时,用户需配置com.alipay.sofa.tracer.samplerPercentage 采样率。
通过 application.properties 增加采样相关配置项提供基于固定采样率的采样模式:
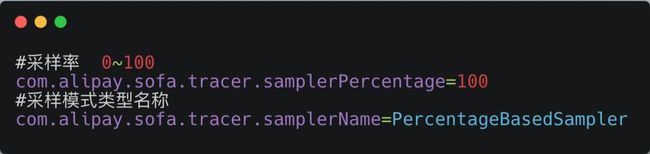
固定采样率验证方式:
1)当采样率设置为 100 时,每次都会打印摘要日志
2)当采样率设置为 0 时,不打印
3)当采样率设置为 0~100 之间时,按概率打印
以请求 10 次来验证下结果。
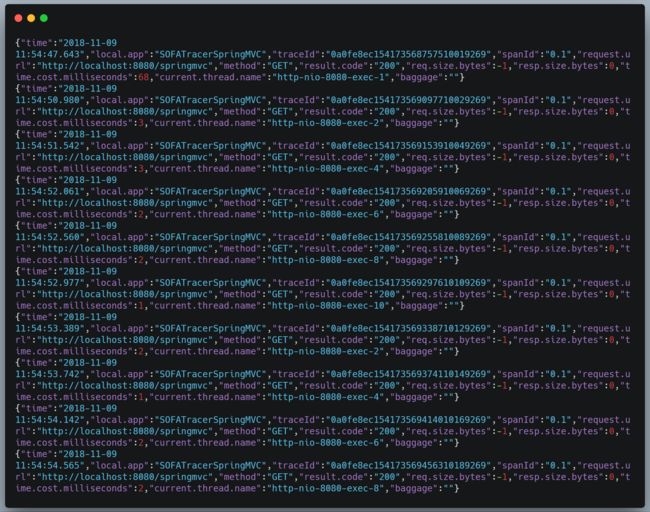
1.当采样率设置为 100 时,每次都会打印摘要日志
启动工程,浏览器中输入:http://localhost:8080/springmvc ;并且刷新地址 10 次,查看日志如下:
2. 当采样率设置为 0 时,不打印
启动工程,浏览器中输入:http://localhost:8080/springmvc ;并且刷新地址 10 次,查看 ./logs/tracerlog/ 目录,没有 spring-mvc-degist.log 日志文件
3. 当采样率设置为 0~100 之间时,按概率打印
这里设置成 20
刷新 10 次请求
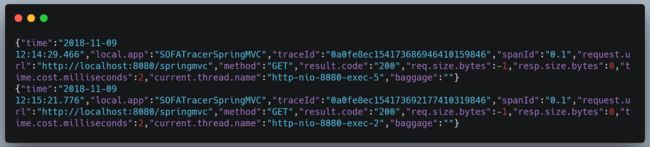
刷新 20 次请求
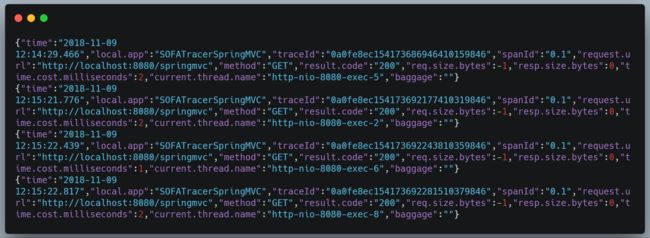
按 20% 进行采样,测试结果仅供参考。
自定义采样模式
SOFATracer 提供基于用户自定义扩展的采样接口,采样模式需实现 com.alipay.common.tracer.core.samplers.Sampler 接口。当 com.alipay.sofa.tracer.samplerCustomRuleClassName = CustomOpenRulesSamplerRuler 时,用户需实现 CustomOpenRulesSamplerRuler.sample 方法基于当前 SofaTracerSpan 参数采样条件定义采样计算规则。
通过 application.properties 增加采样相关配置项支持自定义采样模式:

用户自定义采样规则类实现 com.alipay.common.tracer.core.samplers.Sampler 接口示例:

在 sample 方法中,用户可以根据当前 SofaTracerSpan 提供的信息来决定是否进行打印。此案例是通过判断 isServer 来决定是否采样,isServer=true 不采样,否则采样。 相关实验结果,大家可以自行验证下。
总结
本篇主要剖析 Dapper 论文采样模型策略和 SOFATracer 采样源码实现,详细描述针对埋点数据如何制定采样规则。按照 SOFATracer 基于固定采样率的采样模式和基于用户扩展实现的自定义采样模式选择适合业务需求场景的采样策略,更好地集成 SOFATracer 数据采样版块实现自定义采样计算规则。通过此篇源码剖析希望帮助大家更好的理解 SOFATracer 链路跟踪采样模块的核心原理和具体实现。
文中出现的相关链接:
Drapper 论文原文地址:https://ai.google/research/pubs/pub36356
时间复杂度为 O(N) 的蓄水池采样算法 Reservoir Sampling https://en.wikipedia.org/wiki/Reservoir_sampling
随机 BitSet 来源 StackOverflow:https://stackoverflow.com/questions/12817946/generate-a-random-bitset-with-n-1s
tracer-sample-with-springmvc:https://github.com/alipay/sofa-tracer/tree/master/tracer-samples/tracer-sample-with-springmvc
公众号:金融级分布式架构(Antfin_SOFA)