复现极限模型
codenn 原理
其原理大致是将代码特征映射到一个向量,再将描述文字也映射到一个向量,将其cos距离作为loss训练。
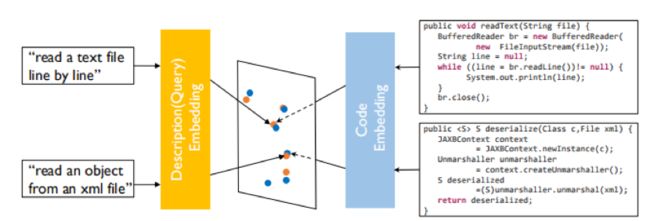
对于代码特征,原论文提取了函数名、调用API序列和token集;对于描述文字,通常选取docstring(Python)或函数上方或内部注释(JavaScript)。对于函数名、token集,会按照驼峰命名和下划线命名进一步划分成更小的词法单元,而API序列则保留不再分割。
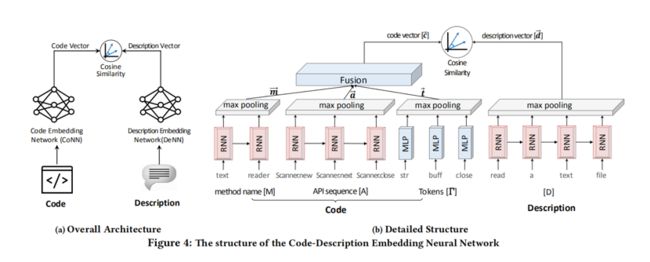
所有的这些词素,对于有序的会使用RNN或其变种处理,再将RNN每一个词的输出进行池化;对于无序的,会用MLP(多层感知机,但是论文作者其实只用了单层)处理再进行池化。所有的代码特征池化得到的特征向量再经过一层全连层,使其维度与描述向量的维度一致。
\[ \mathcal{L}(\theta)=\sum_{
最后以cos距离作为loss。为了便于batch处理这些变长的数据,这些数据会被截断或者填充到某一个长度,截断截尾,填充填后。
原模型使用了4个评价指标Precision@K、MAP、MRR和NDCG,具体可以参看这个Slides:Information Retrieval - web.stanford.edu 。这里就介绍前两个,首先是Precision@K,这个同下面Mao Yutao同学的top K,不再赘述;MAP除了n之外也有个参数K',其值就是K取1到K'的所有Precision@K的平均值;两个指标都是取值0到1,越高越好。
模型的优缺点
优点:
(1)异构数据源和自然语言查询的统一表示是异构的。通过将源代码和自然语言查询联合嵌入到同一个向量表示中 它们的相似性可以更精确地测量。
(2)通过深度学习更好地理解查询,与传统技术不同,DeepCS通过深度学习学习查询和源代码表示。查询的特征,如语义相关词和语序,在我们的模型中都有有考虑。因此,它能够更好地识别查询和代码的语义。
(3)根据自然语言语义对代码片段进行聚类,我们的方法的一个优点是,它将语义上相似的代码片段嵌入到彼此相近的向量中。语义相似代码片段按语义分组。因此,除了精确匹配的片段之外,DeepCS还推荐语义相关的片段。
缺点:
它有时排序部分相关的结果高于精确匹配的结果。这是因为Deeps通过考虑它们的语义向量来排名结果。