Abstract
特点:有一个多任务的loss,简化了学习过程,并且提高了效率。比传统的R-CNN和SPP-Net更加快,而且精度高。
1. Introduction
对目标的精确定位目前还存在两大挑战:
第一:大量的候选区域需要被估计。为了精度定位,卷积层的特征需要共享之前他在原图像中的位置。然后这个方法限制了后向传播的误差,接着潜在的影响了精度。
第二:候选对象位置需要是精练来达到高精度。传统的R-CNN和SPP-net以前的这个挑选候选区域过程在一个独立于的学习过程的。
本篇文章:提出了一个单一过程的学习过程。在学习过程中,同时找出那些候选区域并且能精炼他的空间位置。并且本文还提出一个新的方法:在学习过程来共享卷积特征,允许将全部的反向误差都传播回来,来增加精度。除此之外还用了截断SVD等等一些手段来增加精度并且加快速度。
1.1. RCNN and SPPnet
具体看前两篇。
1.2. Contributions

code
2. Fast R-CNN training
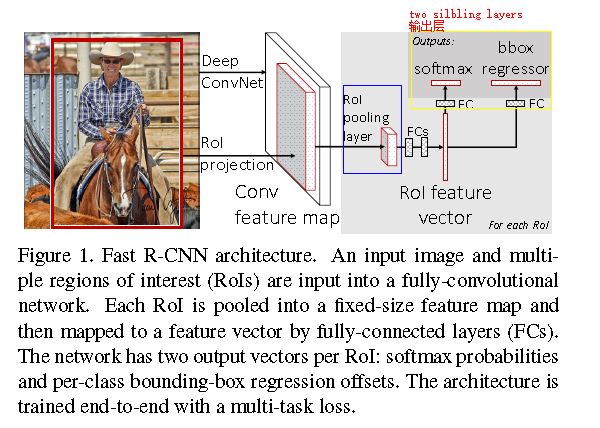
快速R-CNN网络将整个图像和一组object proposals作为输入。
网络首先使用几个卷积(conv)和最大池层来处理整个图像,以产生conv feature map。
然后,对于每个对象proposal,感兴趣区域(RoI)池层从特征图中抽取固定长度的特征向量。
每个特征向量被馈送到完全连接(fc)层序列,其最终分支成两个同级输出层:
一个产生对K个对象类加上全部捕获的“背景”类的softmax概率估计(one that produces softmax probability estimates over K object classes plus a catch-all “background” class)
另一个对每个K对象类输出四个实数,每组4个值编码提炼定义K个类中的一个的的 边 界框位置。(another layer that outputs four real-valued numbers for each of the K object classes. Each set of 4 values encodes refined bounding-box positions for one of the K classes.)
2.1. The RoI pooling layer
The region of interest (RoI) pooling layer是简化版的spatial pyramid pooling(SPP-net).因为(RoI) pooling layer只有单一的尺度。
Rol pooling layer的作用主要有两个:
一个是将image中的RoI定位到feature map中对应patch
另一个是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。
RoI池层使用最大池化将任何有效的RoI区域内的特征转换成具有H×W(例如,7×7)的固定空间范围的小feature map,其中H和W是层超参数它们独立于任何特定的RoI。
在本文中,RoI是conv feature map中的一个矩形窗口。
每个RoI由定义其左上角(r,c)及其高度和宽度(h,w)的四元组(r,c,h,w)定义。
RoI层仅仅是Sppnets中的spatial pyramid pooling layer的特殊形式,其中只有一个金字塔层.
2.2. Using pretrained networks
之前始于训练截断我们训练了3个Image network.当提个预训练模型来初始化FRCN的时候,需要进行3个转变。
结构变了
1.最后一层最大池化层变成了RoI池化层,可以为全连接层产生固定大小的feature。
2.两个sibling层,同时实现不同的功能。
输入变了
3.a batch of N images 和a list of R RoIs.batch的大小和RoI的输出量是动态变化的
2.3. Finetuning for detection
limitation:在3层的softmax classifier 在检测的时候进行了微调。因为3层的softmax classifier接受固定长度的feature向量。它是来自spatial pyramid pooling。在此之前的网络结构卷积层工作方式是offline的。所以在微调阶段,反向传播不可能到达卷积层。换句话说在微调阶段:只有3层的classifier被更新了参数。
由于以上限制limitation的存在:在SPPnet中SGD采用的方式是,在众多的RoI候选区域(将所有图片的RoI区域放在一起)进行采样。所以每一个Minibatch里面的RoI可能是来自不同图片的。
为了消除这个限制limitation:本文采取的SGD策略是有等级的采样:先对输入图片进行采样,然后在已经采样得到的图片中采样得到RoI.这些来自同一个通篇的ROI对于计算和储存是很有效果的。
Multi-task loss.

Mini-batch sampling.
Back-propagation through RoI pooling layers.

SGD hyper-parameters.
解析博客
2.4. Scale invariance
SPPnet用了两种实现尺度不变的方法:
1. brute force (single scale),直接将image设置为某种scale,直接输入网络训练,期望网络自己适应这个scale。
2. image pyramids (multi scale),生成一个图像金字塔,在multi-scale训练时,对于要用的RoI,在金字塔上找到一个最接近227x227的尺寸,然后用这个尺寸训练网络。
虽然看起来2比较好,但是非常耗时,而且性能提高也不对,大约只有%1,所以这篇论文在实现中还是用了1。
3. Fast R-CNN detection
输入分两种形式:
1.single-scale:单一尺度的图片和它的大约2000多张的候选图。
2.multi-scale:一张图片的金字塔和对应金字塔的候选区域。

3.1. Truncated SVD for faster detection
在分类中,计算全连接层比卷积层快,而在检测中由于一个图中要提取2000个RoI,所以大部分时间都用在计算全连接层了。文中采用奇异值分解的方法来减少计算fc层的时间。
SVD
矩阵知识