最近做项目使用到了分布式事务,下面这篇文章将给大家介绍一下对分布式事务的一些见解,并讲解分布式事务处理框架TX-LCN的执行原理,初学入门,错误之处望各位不吝指正。
什么情况下需要使用分布式事务?
使用的场景很多,先举一个常见的:在微服务系统中,如果一个业务需要使用到不同的微服务,并且不同的微服务对应不同的数据库。
打个比方:电商平台有一个客户下订单的业务逻辑,这个业务逻辑涉及到两个微服务,一个是库存服务(库存减一),另一个是订单服务(订单数加一),示意图如下:

如果在执行这个业务逻辑时没有使用分布式事务,当库存与订单其中一个出现故障时,就很可能出现这样的情况:库存数据库的值减少了1,但是订单数据库没有变化;或是库存没变化,多了一个订单,也就是出现了数据不一致现象。
所以在类似的场合下我们要使用分布式事务,保证数据的一致性。
分布式事务的解决思路
引入:mysql中的两阶段提交策略
在谈分布式事务的解决思路之前,我们先来看看单一数据源是如何做事务处理的,我们可以从中获取一些启发。
我们以mysql的InnoDB引擎为例,由于mysql中有两套日志机制,一套是存储层的redo log,另一套是server层的binlog,每次更新数据都要对两个日志进行更新。为了防止写日志时只写了其中一个而没有写另外一个,mysql使用了一个叫两阶段提交的方式保证事务的一致性。具体是这样的:
假设创建一个这样的数据库:mysql> create table T(ID int primary key, c int);,
然后执行一条这样的更新语句:mysql> update T set c=c+1 where ID=2;
这条更新语句的执行流程是这样子的:
- 首先执行器会找引擎取ID=2这一行数据
- 拿到数据后会把数据进行+1操作,然后调用引擎接口把新数据写入
- 引擎将数据更新到内存中,并将操作记录到redo log里,此时redo log处于prepare状态。但它不会提交事务,只是通知执行器已经完成任务,可以随时提交。
- 执行器生成这个操作的binlog,并把binlog写入磁盘
- 最后执行器调用引擎的事务接口,把redo log改为提交状态,更新完成。
在上述过程中,redo log写完后没有直接提交,而是处于prepare状态,等通知执行器并把binlog写完后,redo log再进行提交。这个过程就是两阶段提交,这是一个精妙的设计。
可能你会问为什么要有两阶段提交?如果不采用两阶段提交的话,也就是使用一阶段提交,那就相当于按顺序执行写redo log和binlog,如果写完redo log 后系统出现了故障,那么就会只有redo log记录了操作,binlog没有记录,造成数据不一致;使用两阶段提交的话,假设写完redo log后系统出现了故障,由于事务还没有提交,所以可以顺利回滚。
两阶段提交的设计还有什么好处?首先要奠定一个概念:一个操作执行的时间越长,这个操作就越有可能失败。打个比方,你吃饭要用20分钟,上厕所要用1分钟,在吃饭的过程中收到微信消息的概率肯定比去上厕所的过程中收到微信消息的概率大。由于在数据库中更新操作的时间要远大于提交事务的时间,所以先把更新操作做完,等所有耗时操作都做完最后再提交事务,能够最大程度保证事务执行成功。
分布式事务的两阶段提交策略
根据上述的两阶段提交策略,分布式事务也可以采取类似的办法完成事务。
在第一阶段,我们要新增一个事务管理者的角色,通过它来协调各个数据源。还是拿开头的订单案例讲解,在执行下订单的逻辑时,先让各个数据库去执行各自的事务,比如从库存中减1,在订单库中加1,但是完成后不提交,只是通知事务管理者已经完成了任务。
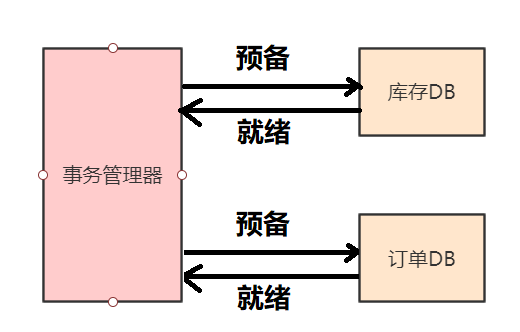
到了第二阶段,由于在阶段一我们已经收到了各个数据源是否就绪的信息,只要有一个数据源没有就绪,在第二阶段就通知所有数据源回滚;如果全部数据源都已经就绪,就通知所有数据源提交事务。

总结一下这个两阶段提交的过程就是:首先事务管理器通知各个数据源进行操作,并返回是否准备好的信息。等所有数据源都准备好后,再统一发送事务提交(回滚)的通知让各个数据源提交事务。由于最后的提交操作耗时极短,所以操作失败的可能性会很低。
那么这个两阶段提交协议可能存在什么缺点呢?很可能存在被阻塞的问题,假如其中一个数据源出现了某些问题阻塞了,既不能返回成功信息,也不能返回失败信息,那么整个事务将被阻塞。对应的策略是添加一些倒计时的操作,或者是重新发送消息。
分布式事务框架TX-LCN
讲了这么多理论的知识,下面讲解一款真正应用在生产中的分布式事务框架TX-LCN的运行原理。(典型的分布式事务框架不止TX-LCN,比如还有阿里的GTS,不过GTS是收费的,TX-LCN是开源的)
我们先看一下官方文档中给出的运行原理示意图:

思路和我们上面讲的两阶段分布式事务处理流程差不多(有小不同),核心步骤分为3步:
- 创建事务组:在事务发起方开始执行业务代码之前先调用TxManager创建事务组对象,然后拿到事务表示GroupId的过程。简单来说就是对这次下订单的操作在事务管理中心里创建一个对象,拿到一个id。
- 加入事务组:参与方在执行完业务方法后,将该模块的事务信息通知给TxManager的操作。也就是指各个数据源(各个服务)完成操作后,和事务管理中心说一声,注册一下自己。
- 通知事务组:发起方执行业务代码后,将发起方执行结果状态通知给TxManager,TxManager将根据事务最终状态和事务组的信息来通知相应的参与模块提交或回滚事务,并返回结果给事务发起方。和客户打交道的下订单服务会收到减库存和加订单是否成功消息,它会把这两个消息通知给事务管理者,事务管理者根据情况通知两个库存服务提交事务或回滚事务。
目前发现网上有一篇不错的TX-LCN执行源码分析文章: https://blog.csdn.net/cgj296645438/article/details/93860384
文章中跟着源码走一遍会发现和上面的流程图差不多,落实到代码中有一些精彩的地方,比如:
public Object runTransaction(DTXInfo dtxInfo, BusinessCallback business) throws Throwable {
if (Objects.isNull(DTXLocalContext.cur())) {
DTXLocalContext.getOrNew();
} else {
return business.call();
}
log.debug("<---- TxLcn start ---->");
DTXLocalContext dtxLocalContext = DTXLocalContext.getOrNew();
TxContext txContext;
// ---------- 保证每个模块在一个DTX下只会有一个TxContext ---------- //
if (globalContext.hasTxContext()) {
// 有事务上下文的获取父上下文
txContext = globalContext.txContext();
dtxLocalContext.setInGroup(true);
log.debug("Unit[{}] used parent's TxContext[{}].", dtxInfo.getUnitId(), txContext.getGroupId());
} else {
// 没有的开启本地事务上下文
txContext = globalContext.startTx();
}
//......
}这段代码保证了每个模块下只会有一个TxContext,换个说法就是假设一个业务逻辑不是操作不同的数据源,而是对同一个数据源执行多次相同的操作,那么该数据源对应的模块在DTX下会只有一个TxContext
LCN的事务协调机制
LCN的口号是:LCN并不生产事务,LCN只是本地事务的协调工。大家肯定会有个疑问,它不生产事务,那么它是怎么控制各个模块在完成事务的逻辑操作之后不马上提交,而是等到TxManager最后一起通知各模块提交的呢?
因为每个模块都是一个TxClient,每个TxClient下都有一个连接池,是框架自定义的连接池,对Connection使用静态代理的方式进行包装。
public class LcnConnectionProxy implements Connection {
private Connection connection;
public LcnConnectionProxy(Connection connection) {
this.connection = connection;
}
/**
* notify connection
*
* @param state transactionState
* @return RpcResponseState RpcResponseState
*/
public RpcResponseState notify(int state) {
try {
if (state == 1) {
log.debug("commit transaction type[lcn] proxy connection:{}.", this);
connection.commit();
} else {
log.debug("rollback transaction type[lcn] proxy connection:{}.", this);
connection.rollback();
}
connection.close();
log.debug("transaction type[lcn] proxy connection:{} closed.", this);
return RpcResponseState.success;
} catch (Exception e) {
log.error(e.getLocalizedMessage(), e);
return RpcResponseState.fail;
}
}
@Override
public void setAutoCommit(boolean autoCommit) throws SQLException {
connection.setAutoCommit(false);
}
//......
}连接池在没有接收到通知事务之前会一直占有着这次分布式事务的连接资源。等到最后TxManager通知TxClient时,TxClient才会去执行相应的提交或回滚。所以LCN的事务协调机制相当于是拦截了一下连接池,控制了连接的事务提交。
LCN的事务补偿机制
由于我们不能保证事务每次都正常执行,如果在执行某个业务方法时,本应该执行成功的操作却因为服务器挂机或网络抖动等问题导致事务没有正常提交,这种场景就需要通过补偿来完成事务。
在这种情况下TxManager会做一个标示;然后返回给发起方。告诉他本次事务有存在没有通知到的情况,然后TxClient再次执行该次请求事务。
参考资料:
极客时间丁奇Mysql实战与尚学堂视频配套资料