一个多月的地铁阅读时光,阅读《Spark for python developers》电子书,不动笔墨不看书,随手在evernote中做了一下翻译,多年不习英语,自娱自乐。周末整理了一下,发现再多做一点就可基本成文了,于是开始这个地铁译系列。
我们将为开发搭建一个独立的虚拟环境,通过Spark和Anaconda提供的PyData 库为该环境补充能力。 这些库包括Pandas,Scikit-Learn, Blaze, Matplotlib, Seaborn, 和 Bokeh. 我们的做法如下:
- 使用Anaconda 的Python 发布包搭建开发环境,包括使用 IPython Notebook 环境来完成我们的数据探索任务。
- 安装并使Spark以及 PyData 库正常工作,例如Pandas,Scikit-Learn, Blaze, Matplotlib, 和 Bokeh.
- 构建一个 word count例子程序来保证一切工作正常.
近些年来涌现出了很多数据驱动型的大公司,例如Amazon, Google, Twitter, LinkedIn, 和 Facebook. 这些公司,通过传播分享,透漏它们的基础设施概念,软件实践,以及数据处理框架,已经培育了一个生机勃勃的开源软件社区,形成了企业的技术,系统和软件架构,还包括新型的基础架构,DevOps,虚拟化,云计算和软件定义网络。
受到Google File System (GFS)启发,开源的分布式计算框架Hadoop和MapReduce被开发出来处理PB级数据。在保持低成本的同时克服了扩展的复杂性,着也导致了数据存储的新生,例如近来的数据库技术,列存储数据库 Cassandra, 文档型数据库 MongoDB, 以及图谱数据库Neo4J。
Hadoop, 归功于他处理大数据集的能力,培育了一个巨大的生态系统,通过Pig, Hive, Impala, and Tez完成数据的迭代和交互查询。
当只使用MapReduce的批处理模式时,Hadoop的操作是笨重而繁琐的。Spark 创造了数据分析和处理界的革命,克服了MapReduce 任务磁盘IO和带宽紧张的缺陷。Spark 是用 Scala实现的, 同时原生地集成了 Java Virtual Machine (JVM) 的生态系统. Spark 很早就提供了Python API 并使用PySpark. 基于Java系统的强健表现,使 Spark 的架构和生态系统具有内在的多语言性.
本书聚焦于PySpark 和 PyData 生态系统 Python 在数据密集型处理的学术和科学社区是一个优选编程语言. Python已经发展成了一个丰富多彩的生态系统. Pandas 和 Blaze提供了数据处理的工具库 Scikit-Learn专注在机器学习 Matplotlib, Seaborn, 和 Bokeh完成数据可视化 因此, 本书的目的是使用Spark and Python为数据密集型应用构建一个端到端系统架构. 为了把这些概念付诸实践 我们将分析诸如 Twitter, GitHub, 和 Meetup.这样的社交网络.我们通过访问这些网站来关注Spark 和开源软件社区的社交活动与交互.
构建数据密集型应用需要高度可扩展的基础架构,多语言存储, 无缝的数据集成, 多元分析处理, 和有效的可视化. 下面要描述的数据密集型应用的架构蓝图将贯穿本书的始终. 这是本书的骨干.
我们将发现spark在广阔的PyData 生态系统中的应用场景.
理解数据密集型应用的架构
为了理解数据密集型应用的架构 使用了下面的概念框架 该架构 被设计成5层:
• 基础设施层
• 持久化层
• 集成层
• 分析层
• 参与层
下图描述了数据密集型应用框架的五个分层:
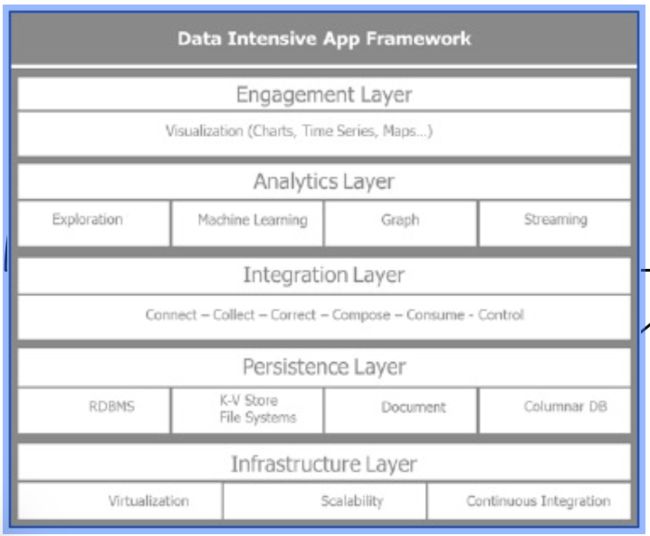
从下往上 我们遍历各层的主要用途.
基础设施层(Infrastructure layer)
基础设施层主要关注虚拟化,扩展性和持续集成. 在实践中, 虚拟化一词, 我们指的是开发环境 的VirtualBox以及Spark 和Anaconda 的虚拟机环境。 如果扩展它,我们可以在云端创建类似的环境。创建一个隔离的开发环境,然后迁移到测试环境,通过DevOps 工具,还可以作为持续集成的一部分被部署到生产环境,例如 Vagrant, Chef, Puppet, 和Docker. Docker 是一个非常流行的开源项目,可以轻松的实现新环境的部署和安装。本书局限于使用VirtualBox构建虚拟机. 从数据密集型应用架构看,我们将在关注扩展性和持续集成前提下只阐述虚拟化的基本步骤.
持久化层(Persistence layer)
持久化层管理了适应于数据需要和形态的各种仓库。它保证了多元数据存储的建立和管理。 这包括关系型数据库如 MySQL和 PostgreSQL;key-value数据存储 Hadoop, Riak, 和 Redis ;列存储数据库如HBase 和 Cassandra; 文档型数据库 MongoDB 和 Couchbase; 图谱数据库如 Neo4j. 持久化层还管理了各种各样的文件系统,如 Hadoop's HDFS. 它与各种各样的存储系统交互,从原始硬盘到 Amazon S3. 它还管理了各种各样的文件存储格式 如 csv, json, 和parquet(这是一个面向列的格式).
集成层(Integration layer)
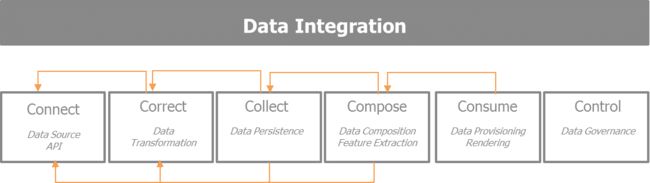
集成层专注于数据的获取、转移、质量、持久化、消费和控制.基本上由以下的5C来驱动: connect, collect, correct, compose和consume.这五个步骤描述了数据的生命周期。它们聚焦于如何获取有兴趣的数据集、探索数据、反复提炼使采集的信息更丰富,为数据消费做好准备. 因此, 这些步骤执行如下的操作:
- Connect: 目标是从各种各样数据源选择最好的方法.如果存在的话,这些数据源会提供APIs,输入格式,数据采集的速率,和提供者的限制.
- Correct: 聚焦于数据转移以便于进一步处理 同时保证维护数据的质量和一致性
- Collect: 哪些数据存储在哪 用什么格式 方便后面阶段的组装和消费
- Compose: 集中关注如何对已采集的各种数据集的混搭, 丰富这些信息能够构建一个引入入胜的数据驱动产品。
- Consume: 关注数据的使用、渲染以及如何使正确的数据在正确的时间达到正确的效果。
- Control: 这是随着数据、组织、参与者的增长,早晚需要的第六个附加步骤,它保证了数据的管控。
下图描述了数据获取以及提炼消费的迭代过程:
分析层(Analytics layer)
分析层是Spark 处理数据的地方,通过各种模型, 算法和机器学习管道从而得出有用的见解. 对我们而言, 本书的分析层使用的是Spark. 我们将在接下来的章节深入挖掘Spark的优良特性. 简而言之,我们使它足够强大以致于在单个同一平台完成多周范式的分析处理。 它允许批处理, 流处理和交互式分析. 在大数据集上的批处理尽管有较长的时延单使我们能够提取模式和见解,也可以在流模式中处理实时事件。 交互和迭代分析更适合数据探索. Spark 提供了Python 和R语言的绑定API,通过SparkSQL 模块和Spark Dataframe, 它提供了非常熟悉的分析接口.
参与层(Engagement layer)
参与层完成与用户的交互,提供了 Dashboards,交互的可视化和告警. 我们将聚焦在 PyData 生态系统提供的工具如Matplotlib, Seaborn, 和Bokeh.
理解Spark
Hadoop 随着数据的增长水平扩展,可以运行在普通的硬件上, 所以是低成本的. 数据密集型应用利用可扩展的分布处理框架在大规模商业集群上分析PB级的数据. Hadoop 是第一个map-reduce的开源实现. Hadoop 依赖的分布式存储框架叫做 HDFS(Hadoop Distributed File System). Hadoop 在批处理中运行map-reduce任务.Hadoop 要求在每个 map, shuffle,和reduce 处理步骤中将数据持久化到硬盘. 这些批处理工作的过载和延迟明显地影响了性能.
Spark 是一个面向大规模数据处理的快速、分布式、通用的分析计算引擎. 主要不同于Hadoop的特点在于Spark 通过数据管道的内存处理允许不同阶段共享数据. Spark 的独特之处在于允许四种不同的数据分析和处理风格. Spark能够用在:
- Batch: 该模式用于处理大数据集典型的是执行大规模map-reduce 任务。
- Streaming: 该模式用于近限处理流入的信息。
- Iterative: 这种模式是机器学习算法,如梯度下降的数据访问重复以达到数据收敛。
- Interactive: 这种模式用于数据探索,有用大数据块位于内存中,所以Spark的响应时间非常快。
下图描述了数据处理的4种方式:

Spark 有三种部署方式: 单机单节点和两种分布式集群方式Yarn(Hadoop 的分布式资源管理器)或者Mesos(Berkeley 开发的开源资源管理器,同时可用于Spark):

Spark 提供了一个Scala, Java, Python, and R的多语言接口.
Spark libraries
Spark 时一个完整的解决方案, 有很多强大的库:
- SparkSQL: 提供 类SQL 的能力 来访问结构化数据,并交互性地探索大数据集
- SparkMLLIB: 用于机器学习的大量算法和一个管道框架
- Spark Streaming: 使用微型批处理和滑动窗口对进入的流数据T实现近限分析
- Spark GraphX: 对于复杂连接的尸体和关系提供图处理和计算
PySpark实战
Spark是使用Scala实现的,整个Spark生态系统既充分利用了JVM环境也充分利用了原生的HDFS. Hadoop HDFS是Spark支持的众多数据存储之一。 Spark与其相互作用多数据源、类型和格式无关.
PySpark 不是Spark的一个Python转写,如同Jython 相对于Java。PySpark 提供了绑定Spark的集成 API,能够在所有的集群节点中通过pickle序列化充分使用Python 生态系统,更重要的是, 能够访问由Python机器学习库形成的丰富的生态系统,如Scikit-Learn 或者象Pandas那样的数据处理。
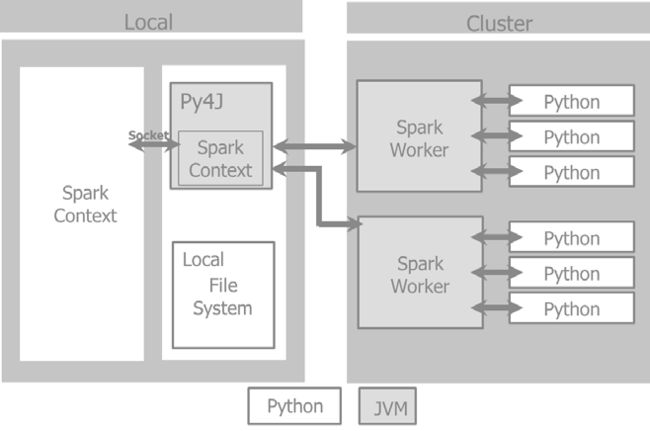
当我们着有一个Spark 程序的时候, 程序第一件必需要做的事情是创建一个SparkContext 对象,来告诉Spark如何防蚊鸡群。Python程序会创建PySparkContext。Py4J 是一个网关将Spark JVM SparkContex于python程序绑定。应用代码JVM SparkContextserializes
和闭包把他们发送给集群执行.
集群管理器分配资源,调度,运送这些闭包给集群上的 Spark workers,这需要激活 Python 虚拟机.
在每一台机器上, 管理 Spark Worker 执行器负责控制,计算,存储和缓存.
这个例子展示了 Spark driver 在本地文件系统上如何管理PySpark context 和Spark context以及如何通过集群管理器与 Spark worker完成交互。
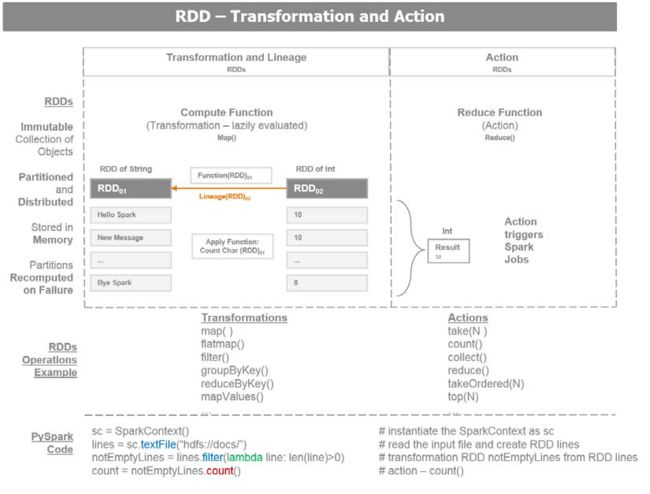
弹性分布数据集(RDS,Resilient Distributed Dataset)
Spark 应用包含了一个驱动程序来运行用户的主函数,在集群上创建分布式数据集, 并在这些数据集上执行各种并行操作
(转换和动作 )。 Spark 应用运行在独立的进程集合, 与一个驱动程序中的一个 SparkContext 协调工作。SparkContext 将从集群管理器中分配系统资源 (主机, 内存, CPU)。
SparkContext管理执行器,执行器来管理集群上的多个worker .驱动程序中有需要运行的Spark 工作。这些工作被分拆成多个任务,提交给执行器来完成。执行器负责每台机器的计算,存储和缓存。Spark 中的核心构建块是 RDD (Resilient Distributed Dataset). 一个已选元素的数据集。分布意味着数据集可以位于集群的任何节点。弹性意味着数据集在不伤害数据计算进程的条件下可以全部或部分丢失,spark 将重新计算内存中的数据关系,例如操作 DAG (Directed Acyclic Graph) 基本上,Spark 将RDD的一个状态的内存快照放入缓存。如果一台计算机在操作中挂了, Spark 将从缓存的RDD中重建并操作DAG,从而使RDD从节点故障中恢复。
这里有两类的RDD 操作:
• Transformations: 数据转换使用现存的RDD,并生产一个新转换后的RDD指针。一个RDD是不可变的,一旦创建,不能更改。 每次转换生成新的RDD. 数据转换的延迟计算的,只有当一个动作发生时执行。如果发生故障,转换的数据世系重建RDD
.
• Actions: 动作是一个RDD触发了Spark job,并缠上一个值。一个动作操作引发Spark 执行数据转换操作,需要计算动作返回的RDD。动作导致操作的一个DAG。 DAG 被编译到不同阶段,每个阶段执行一系列任务。 一个任务是基础的工作单元。
这是关于RDD的有用信息:
- RDD 从一个数据源创建,例如一个HDFS文件或一个数据库查询 .
有三种方法创建 RDD:
∞从数据存储中读取
∞ 从一个现存的RDD转换
∞使用内存中的集合
- RDDs 的转换函数有 map 或 filter, 它们生成一个新的RDD.
- 一个RDD上的一个动作包括 first, take, collect, 或count 将发送结果到Spark 驱动程序. Spark驱动程序是用户与Spark集群交互的客户端。
下图描述了RDD 数据转换和动作:
理解 Anaconda
Anaconda 是由 Continuum(https://www.continuum.io/)维护的被广泛使用的Python分发包. 我们将使用 Anaconda 提供的流行的软件栈来生成我们的应用. 本书中,使用 PySpark和PyData生态系统。PyData生态系统由Continuum维护,支持并升级,并提供 Anaconda Python 分发包。Anaconda
Python分发包基本避免了python 环境的安装过程恶化从而节约了时间;我们用它与Spark对接. Anaconda 有自己的包管理工具可以替代传统的 pip install 和easy_install. Anaconda 也是完整的解决方案,包括一下有名的包如 Pandas, Scikit-Learn, Blaze, Matplotlib, and Bokeh. 通过一个简单的命令久可以升级任何已经安装的库:
$ conda update
通过命令可以我们环境中已安装库的列表:
$ conda list
主要组件如下:
- Anaconda: 这是一个免费的Python分发包包含了科学,数学,工程和数据分析的200多个Python包
- Conda: 包管理器负责安装复杂软件栈的所有依赖,不仅限于 Python ,也可以管理R和其它语言的安装进程。
- Numba: 通过共性能函数和及时编译,提供了加速Python代码的能力。
- Blaze: 通过统一和适配的接口来访问提供者的数据来实现大规模数据分析,包括Python 流处理, Pandas, SQLAlchemy, 和Spark.
- Bokeh: 为巨型流数据集提供了交互数据的可视化.
- Wakari: 允许我们在一个托管环境中分享和部署 IPython Notebooks和其它应用
下图展示了 Anaconda 软件栈中的组件:

搭建Spark 环境
本节我们学习搭建 Spark环境:
- 在Ubuntu 14.04的虚拟机上创建隔离的开发环境,可以不影响任何现存的系统
- 安装 Spark 1.3.0 及其依赖.
- 安装Anaconda Python 2.7 环境包含了所需的库 例如Pandas, Scikit-Learn, Blaze, and Bokeh, 使用PySpark, 可以通过IPython Notebooks访问
- 在我们的环境中搭建后端或数据存储,使用MySQL作为关系型数据库;MongoDB作文档存储;Cassandra 作为列存储数据库。 根据所需处理数据的需要,每种存储服务于不同的特殊目的。MySQL RDBMs可以使用SQL轻松地完成表信息查询;如果我们处理各种API获得的大量JSON类型数据, 最简单的方法是把它们存储在一个文档里;对于实时和时间序列信息,Cassandra 是最合适的列存储数据库.
下图给出了我们将要构建的环境视图 将贯穿本书的使用:
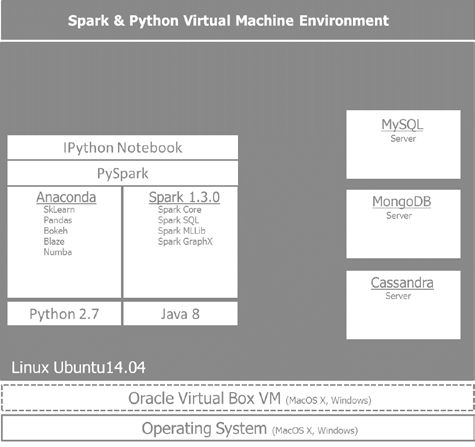
在Oracle VirtualBox 搭建Ubuntu
搭建一个运行Ubuntu 14.04的virtualbox环境是搭建开发环境最安全的办法,可以避免与现存库的冲突,还可以用类似的命令将环境复制到云端。
为了搭建Anaconda和Spark的环境,我们要创建一个运行Ubuntu 14.04的virtual box虚拟机.
步骤如下:
- Oracle VirtualBox VM从 https://www.virtualbox.org/wiki/Downloads 免费下载,径直安装就可以了.
- 装完 VirtualBox,打开Oracle VM VirtualBox Manager,点击按钮New.
- 给新的VM指定一个名字, 选择Linux 类型和Ubuntu(64 bit)版本.
- 需要从Ubuntu的官网下载ISO的文件分配足够的内存(4GB推荐) 和硬盘(20GB推荐).我们使用Ubuntu 14.04.1 LTS版本,下载地址: http://www.ubuntu.com/download/desktop.
- 一旦安装完成, 就可以安装VirtualBox Guest Additions了 (从VirtualBox 菜单,选择新运行的VM) Devices|Insert Guest Additions CD image. 由于windows系统限制了用户界面,可能会导致安装失败.
- 一旦镜像安装完成,重启VM,就已经可用了.打开共享剪贴板功能是非常有帮助的。选择VM点击 Settings, 然后General|Advanced|Shared Clipboard 再点击 Bidirectional.
安装Anaconda的Python 2.7版本
PySpark当前只能运行在Python 2.7(社区需求升级到Python 3.3),安装Anaconda, 按照以下步骤:
- 下载 Linux 64-bit Python 2.7的Anaconda安装器 http://continuum.io/downloads#all.
- 下载完Anaconda 安装器后, 打开 terminal进入到它的安装位置.在这里运行下面的命令, 在命令中替换2.x.x为安装器的版本号:
#install anaconda 2.x.x
#bash Anaconda-2.x.x-Linux-x86[_64].sh
- 接受了协议许可后, 将让你确定安装的路径 (默认为 ~/anaconda).
- 自解压完成后, 需要添加 anaconda 执行路径到 PATH 的环境变量:
# add anaconda to PATH
bash Anaconda-2.x.x-Linux-x86[_64].sh
安装 Java 8
Spark运行在 JVM之上所以需要安装Java SDK而不只是JRE, 这是我们构建spark应用所要求的. 推荐的版本是Java Version 7 or higher. Java 8 是最合适的, 它包安装 Java 8, 安装以下步骤:
- 安装 Oracle Java 8 使用的命令如下:
# install oracle java 8
$ sudo apt-get install software-properties-common
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer
- 设置 JAVA_HOME 环境变量,保证Java 执行程序在PATH中.
3.检查JAVA_HOME 是否被正确安装:
#
$ echo JAVA_HOME
安装 Spark
首先浏览一下Spark的下载页 http://spark.apache.org/downloads.
html.
它提供了多种可能来下载Spark的早期版本,不同的分发包和下载类型。 我们选择最新的版本. pre-built for Hadoop 2.6 and later. 安装 Spark 的最简方法是使用 Spark
package prebuilt for Hadoop 2.6 and later, 而不是从源代码编译,然后 移动 ~/spark 到根目录下。下载最新版本 Spark—Spark 1.5.2, released on November 9, 2015:
选择Spark 版本 1.5.2 (Nov 09 2015),
选择包类型 Prebuilt for Hadoop 2.6 and later,
选择下载类型 Direct Download,
下载spark: spark-1.5.2-bin-hadoop2.6.tgz,
- 验证 1.3.0 签名校验,也可以运行:
# download spark
$ wget http://d3kbcqa49mib13.cloudfront.net/spark-1.5.2-bin-hadoop2.6.tgz
接下来, 我们将提取和清理文件:
`
extract,clean up,move the unzipped files under the spark directory
$ rm spark-1.5.2-bin-hadoop2.6.tgz
$ sudo mv spark-* spark
`
现在,我们能够运行 Spark 的 Python 解释器了:
# run spark
$ cd ~/spark
./bin/pyspark
应该可以看到类似这样的效果:
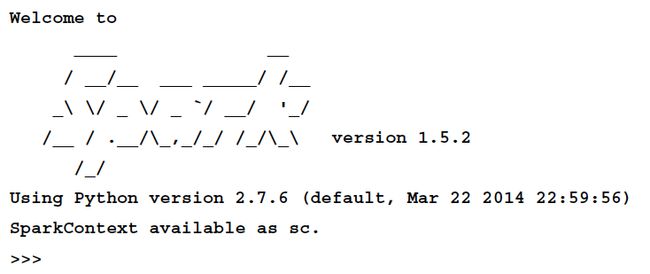
解释器已经提供了一个Spark context 对象, sc, 我们可以看到:
`
>>>print(sc)
`
使用 IPython Notebook
IPython Notebook 比控制台拥有更更友好的用户体验.
可以使用如新命令启动IPython Notebook:
$ IPYTHON_OPTS="notebook --pylab inline" ./bin/pyspark
在目录 examples/AN_Spark,启动PySpark和IPYNB或者在Jupyter或
IPython Notebooks 的安装目录启动:
# cd to /home/an/spark/spark-1.5.0-bin-hadoop2.6/examples/AN_Spark
$ IPYTHON_OPTS='notebook' /home/an/spark/spark-1.5.0-bin-hadoop2.6/bin/
pyspark --packages com.databricks:spark-csv_2.11:1.2.0
# launch command using python 3.4 and the spark-csv package:
$ IPYTHON_OPTS='notebook' PYSPARK_PYTHON=python3
/home/an/spark/spark-1.5.0-bin-hadoop2.6/bin/pyspark --packages com.databricks:spark-csv_2.11:1.2.0
构建在 PySpark上的第一个应用
我们已经检查了一切工作正常,将word
count 作为本书的第一个实验是义不容辞的:
# Word count on 1st Chapter of the Book using PySpark
import re
# import add from operator module
from operator import add
# read input file
file_in = sc.textFile('/home/an/Documents/A00_Documents/Spark4Py
20150315')
# count lines
print('number of lines in file: %s' % file_in.count())
# add up lengths of each line
chars = file_in.map(lambda s: len(s)).reduce(add)
print('number of characters in file: %s' % chars)
# Get words from the input file
words =file_in.flatMap(lambda line: re.split('\W+', line.lower().
strip()))
# words of more than 3 characters
swords = words.filter(lambda x: len(x) > 3)
# set count 1 per word
words = words.map(lambda w: (w,1))
# reduce phase - sum count all the words
words = words.reduceByKey(add)
在这个程序中, 首先从目录 /home/an/
Documents/A00_Documents/Spark4Py 20150315 中读取文件到 file_in. 然后计算文件的行数以及每行的字符数.
我们把文件拆分成单词并变成小写。 为了统计单词的目的, 我们选择多于三个字符的单词来避免象 the, and, for 这样的高频词. 一般地, 这些被认为是停词,应该被语言处理任务过滤掉 .
在该阶段,我们准备了 MapReduce 步骤,每个单词 map 为值1, 计算所有唯一单词的出现数量.
这是IPython Notebook中的代码描述. 最初的 10 cells是在数据集上的单词统计预处理 数据集在本地文件中提取.
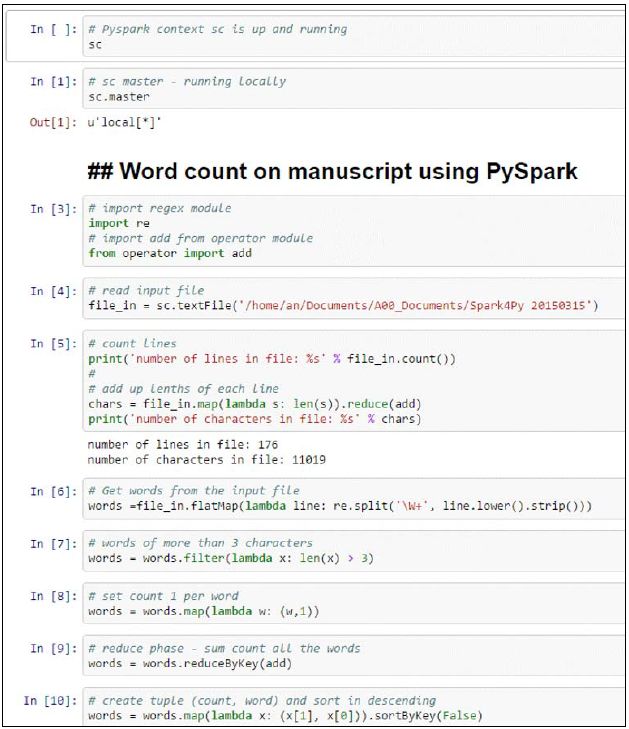
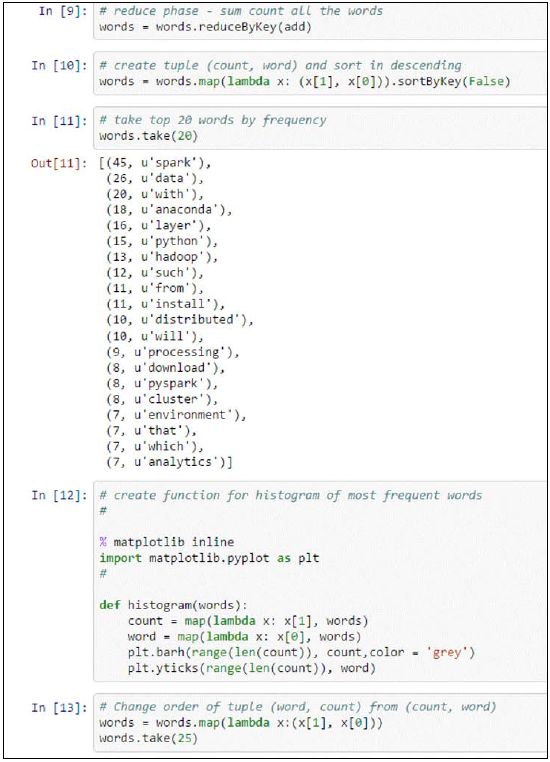
以(count, word)格式交换词频统计元组是为了把count作为元组的key 进行排序 :
# create tuple (count, word) and sort in descending
words = words.map(lambda x: (x[1], x[0])).sortByKey(False)
# take top 20 words by frequency
words.take(20)
未来显示结果, 我们创建(count, word) 元组来以逆序显示词频出现最高的20个词:
生成直方图:
# create function for histogram of most frequent words
% matplotlib inline
import matplotlib.pyplot as plt
#
def histogram(words):
count = map(lambda x: x[1], words)m
word = map(lambda x: x[0], words)
plt.barh(range(len(count)), count,color = 'grey')
plt.yticks(range(len(count)), word)
# Change order of tuple (word, count) from (count, word)
words = words.map(lambda x:(x[1], x[0]))
words.take(25)
# display histogram
histogram(words.take(25))
我们可以看到以直方图形式画出的高频词,我们已经交换了初识元组 (count,word) 为(word, count):

所以,我们也已经回顾了本章所有的高频词 Spark, Data 和 Anaconda.