一、概述
Java IO库中的流代表有能力产出数据的数据源对象或者是有能力接收数据的接收端对象,我们一般把它分成输入和输出两部分:
- 继承自
InputStream或Reader派生的类都含有名为read的方法,用于读取单个字节或字节数组。 - 继承自
OuputStream或Writer派生的类都含有名为write的方法,用于写入单个字节或字节数组。
我们通常通过叠合多个对象来提供所期望的功能,这其实是一种装饰器设计模式。
二、字节输入流
2.1 InputStream的作用
它的作用是用来表示那些从不同数据源产生输入的类,而最终结果就是通过read方法获得数据源的内容,从数据源中读出的内容用int或byte[]来表示:
- 字节数组
-
String对象 - 文件
- 管道
- 一个由其它种类的流组成的序列,以便我们可以将它们收集合并到一个流内
- 其它数据源,如网络等
2.2 InputStream源码
InputStream是一个抽象类,所有表示字节输入的流都是继承于它,它实现了以下接口:
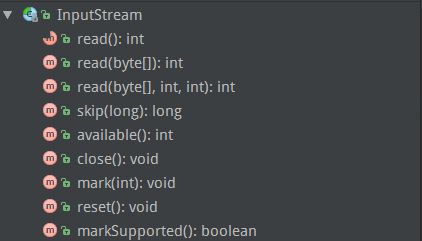
比较关键的是前面四个方法:
-
public abstract int read() throws IOException
返回输入流的下一个字节(next byte),如果已经到达输入流的末尾,那么返回-1 -
public int read(byte b[]) throws IOException
尝试从输入流中读取b.length长度的字节,存入到b中,如果已经到达末尾返回-1,否则返回成功写入到b中的字节数。 -
public int read(byte b[], int off, int len) throws IOException
尝试从输入流中读取下len长度的字节,如果len为0,那么返回0,否则返回实际读入的字节数,读入的第一个字节存放在数据b[off]中,如果没有可读的,那么返回-1。 -
public long skip(long n) throws IOException
跳过,并丢弃掉n个字节,其最大值为2048。
2.3 InputStream的具体实现类
-
ByteArrayInputStream
它接收byte[]作为构造函数的参数,我们调用read方法时,就是从byte[]数组里,读取字节。
public ByteArrayInputStream(byte buf[], int offset, int length) {
this.buf = buf;
this.pos = offset;
this.count = Math.min(offset + length, buf.length);
this.mark = offset;
}
public synchronized int read() {
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
-
StringBufferInputStream
已经过时,推荐使用StringReader。 -
FileInputStream
FileInputStream支持提供文件名、File和FileDescription作为构造函数的参数,它的read调用的是底层的native方法。
public FileInputStream(File file) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
fd = new FileDescriptor();
fd.attach(this);
path = name;
open(name);
}
public int read() throws IOException {
return read0();
}
private native int read0() throws IOException;
-
PipedInputStream
通过通信管道来交换数据,如果两个线程希望进行数据的传输,那么它们一个创建管道输出流,另一个创建管道输入流,它必须要和一个PipedOutputStream相连接。
public PipedInputStream(int pipeSize) {
if (pipeSize <= 0) {
throw new IllegalArgumentException("pipe size " + pipeSize + " too small");
}
buffer = new byte[pipeSize];
}
public PipedInputStream(PipedOutputStream out, int pipeSize) throws IOException {
this(pipeSize);
connect(out);
}
@Override
public synchronized int read() throws IOException {
if (!isConnected) {
throw new IOException("Not connected");
}
if (buffer == null) {
throw new IOException("InputStream is closed");
}
lastReader = Thread.currentThread();
try {
int attempts = 3;
while (in == -1) {
// Are we at end of stream?
if (isClosed) {
return -1;
}
if ((attempts-- <= 0) && lastWriter != null && !lastWriter.isAlive()) {
throw new IOException("Pipe broken");
}
notifyAll();
wait(1000);
}
} catch (InterruptedException e) {
IoUtils.throwInterruptedIoException();
}
int result = buffer[out++] & 0xff;
if (out == buffer.length) {
out = 0;
}
if (out == in) {
in = -1;
out = 0;
}
notifyAll();
return result;
}
-
SequenceInputStream
将多个InputStream连接在一起,一个读完后就完毕,并读下一个,它接收两个InputStream对象或者一个容纳InputStream对象的容器Enumeration。
public int read() throws IOException {
while (in != null) {
int c = in.read();
if (c != -1) {
return c;
}
nextStream();
}
return -1;
}
-
ObjectInputStream
它和一个InputStream相关联,源数据都是来自于这个InputStream,它继承于InputStream,并且它和传入的InputStream并不是直接关联的,中间通过了BlockDataInputStream进行中转,要关注的就是它的readObject方法,它会把一个之前序列化过的对象进行反序列化,然后得到一个Object对象,它的目的在于将(把二进制流转换成为对象)和(从某个数据源中读出字节流)这两个操作独立开来,让它们可以随意地组合。
public ObjectInputStream(InputStream in) throws IOException {
verifySubclass();
bin = new BlockDataInputStream(in);
handles = new HandleTable(10);
vlist = new ValidationList();
serialFilter = ObjectInputFilter.Config.getSerialFilter();
enableOverride = false;
readStreamHeader();
bin.setBlockDataMode(true);
}
public final Object readObject() throws IOException, ClassNotFoundException {
if (enableOverride) {
return readObjectOverride();
}
// if nested read, passHandle contains handle of enclosing object
int outerHandle = passHandle;
try {
Object obj = readObject0(false);
handles.markDependency(outerHandle, passHandle);
ClassNotFoundException ex = handles.lookupException(passHandle);
if (ex != null) {
throw ex;
}
if (depth == 0) {
vlist.doCallbacks();
}
return obj;
} finally {
passHandle = outerHandle;
if (closed && depth == 0) {
clear();
}
}
}
-
FilterInputStream
它的构造函数参数就是一个InputStream:
protected FilterInputStream(InputStream in) {
this.in = in;
}
public int read() throws IOException {
return in.read();
}
这个类很特殊,前面的InputStream子类都是传入一个数据源(Pipe/byte[]/File)等等,然后通过重写read方法从数据源中读取数据,而FilterInputStream则是将InputStream组合在内部,它调用in去执行InputStream定义的抽象方法,也就是说它不会改变组合在内部的InputStream所对应的数据源。
另外,它还新增了一些方法,这些方法底层还是调用了read方法,但是它封装了一些别的操作,比如DataInputStream中的readInt,它调用in连续读取了四次,然后拼成一个int型返回给调用者,之所以采用组合,而不是继承,目的是将(把二进制流转换成别的格式)和(从某个数据源中读出字节流)这两个操作独立开来,让它们可以随意地组合。
public final int readInt() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch1 << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0));
}
三、字节输出流
3.1 OuputStream的作用
OuputStream决定了输出要去往的目标:
- 字节数组
- 文件
- 管道
3.2 OutputStream源码
和InputStream类似,也是一个抽象类,它的子类代表了输出所要去往的目标,它的关键方法如下:

我们主要关注的是
write方法,前两个
write方法最终都是调用了抽象的
write(int oneByte)方法,最终怎么写入是由子类实现的。
3.3 OutputStream的具体实现类
-
ByteArrayOutputStream
在ByteArrayOutputStream的内部,有一个可变长的byte[]数组,当我们调用write方法时,就是向这个数组中写入数据,它还提供了toByteArray/toString方法,来获得当前内部byte[]数组中的内容。 -
FileOutputStream
它和上面类似,只不过写入的终点换成了所打开的文件。 -
PipedOutputStream
和PipedInputStream相关联。 -
ObjectOutputStream
和ObjectInputStream类似,只不过它内部组合的是一个OutputStream,当调用writeObject(Object object)方法时,其实是先将Object进行反序列化转换为byte,再输出到OuputStream所指向的目的地。 -
FilterOutputStream
它的思想和FilterInputStream类似,都是在内部组合了一个OuputStream,FilterOutputStream提供了写入int/long/short的write重载函数,当我们调用这些函数之后,FilterOutputStream最终会通过内部的OuputStream向它所指向的目的地写入字节。