目录
- mysql复制那点事 - Seconds_behind_Master参数调查笔记
- 0. 参考文献
- 1. 问题背景
- 2. 调查结论
- 3. 调查与分析过程
- 3.1 轮转binlog时的运行逻辑
- 3.2 da执行与本实例serverid一致的binlog时的运行逻辑
- 3.3 小结
- 4. 总结
mysql复制那点事 - Seconds_behind_Master参数调查笔记
0. 参考文献
| 序号 | 文献 |
|---|---|
| 1 | MySQL 5.7 MTS源码分析 |
| 2 | MySQL · 答疑解惑 · 备库Seconds_Behind_Master计算 |
| 3 | MySQL · 答疑释惑 · server_id为0的Rotate |
| 4 | 【案例】主从替换之后的复制风暴 |
| 5 | MySQL 复制源码解析 |
| 6 | MySQL主库02设置宕机导致的主库数据丢失解决方法和原因 |
| 7 | Mysql rpl_slave.cc:handle_slave_io 源码的一些个人分析 |
| 8 | mysql slave 备库延迟是怎么得到的 |
| 9 | MySQL 编译安装并且开启DEBUG模式 |
| 10 | Bug #72376:Seconds_behind_master distorted because of previous_gtid event |
| 11 | MySQL Binlog解析(1) |
| 12 | 理解MySQL——复制(Replication) |
ps:如上的参考资料并非完全在本文中被引用,其他没有被引用的资料在本文的形成的工作中,提供了思路上和其他方面的参考,因此一并列入参考文献。感谢如上的文献作者提供的参考。
1. 问题背景
部门当前的数据库架构是双主模式,既线上由2台互为主从的数据库搭建而成的集群。高可用通过vip和headbeat来做保证。通常情况下,vip挂在主(本文称之为da)上,当da发生了异常比如宕机等问题的时候,vip自动漂移至从(本文称之为dp)。架构如下图所示:
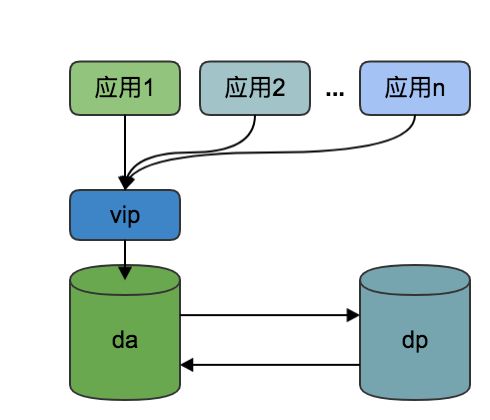
可以看出,所有的写入和读取操作都在da上进行。da产生的binlog会被dp拉取重放。同时dp也会产生binlog并被da拉取重放(注:这里不会产生循环复制(既da产生的binlog事件在dp执行过了之后,再被da读取到再执行),因为binlog中每个event都有个serverid标记,标记是哪个server产生的事物。当da读取到binlog的时候,发现serverid和本机的serverid一致,便会跳过当前的binlog event)。正常情况下,da的Seconds_behind_Master参数,应该保持在0或者很小的数值才对。但是监控系统发现,da的Seconds_behind_Master参数经常发生跳变,上一秒为0下一秒就可能为一个很大值(比如10000)。例如下面的数据,是通过脚本抓取到的线上Seconds_behind_Master情况:
2019-06-27 13:26:00
Read_Master_Log_Pos: 472851480
Relay_Log_File: da01-relay-bin.002323
Relay_Log_Pos: 371
Relay_Master_Log_File: dp01-bin.004267
Exec_Master_Log_Pos: 472851480
Seconds_Behind_Master: 0
2019-06-27 13:26:01
Read_Master_Log_Pos: 473594815
Relay_Log_File: da01-relay-bin.002323
Relay_Log_Pos: 371
Relay_Master_Log_File: dp01-bin.004267
Exec_Master_Log_Pos: 473594649
Seconds_Behind_Master: 622
2019-06-27 13:26:02
Read_Master_Log_Pos: 474422859
Relay_Log_File: da01-relay-bin.002323
Relay_Log_Pos: 371
Relay_Master_Log_File: dp01-bin.004267
Exec_Master_Log_Pos: 474422859
Seconds_Behind_Master: 02. 调查结论
前文讲到了本文调查的问题背景,在这里先给出下整个问题的调查结论。在sql/rpl_slave.cc 中计算Seconds_Behind_Master逻辑如下 (文献2):
if ((mi->get_master_log_pos() == mi->rli->get_group_master_log_pos()) && (!strcmp(mi->get_master_log_name(), mi->rli->get_group_master_log_name()))) {
if (mi->slave_running == MYSQL_SLAVE_RUN_CONNECT)
protocol->store(0LL);
else
protocol->store_null();
} else {
long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp) - mi->clock_diff_with_master);
protocol->store((longlong)(mi->rli->last_master_timestamp ? max(0L, time_diff) : 0));
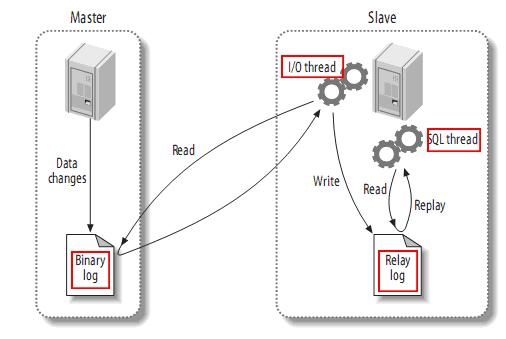
}当Exec_Master_Log_Pos 从前文的结果中可以看出,跟Seconds_Behind_Master(下文简称SBM)值有关的mysql 变量就是last_master_timestamp。因此需要追踪下在收到的binlog的serverid和mysql进程的serverid一致的情况下,last_master_timestamp是如何更新的。根据前文的复现方法,需要去确认如下的2个点: 为了便于观察mysql的运行逻辑,本文参考文献9的办法,编译了一个debug版本。在mysql运行的过程中,tail -f mysqld.trace文件观察mysql命令执行的过程。 在dp 执行flush logs 或者轮转binlog的时候,会产生一个ROTATE_EVENT事件(具体的解析可以参考文献11)。在mysqld.trace文件中,可以观察到如下的信息,标志着da此时接收到了dp的binlog轮转事件的ROTATE_EVENT。 相应的代码在sql/rpl_slave.cc文件的5819行中: 可以看到在sql进程接收到一个binlog之后,会调用queue_event进行写入relaylog。queue_event处理ROTATE_EVENT关键代码如下: 在switch中判断binlog如果是ROTATE_EVENT,则调用process_io_rotate进行处理。其中buf是sql进行拉取到的binlog的缓存,mi是代表了masterinfo。process_io_rotate主要的工作是更新master_info 的相关信息,例如下一个binglog的位置,master的binlog位置信息等。可以在mysqld.trace 文件中观察到如下的信息: process_io_rotate函数注释信息如下: 在完成相关的工作之后,来到queue_event函数的最后,写入ROTATE_EVENT,在mysqld.trace中可以看到如下的信息: 相关代码如下: 到此,ROTATE_EVENT事件被完全写入到了relaylog中。借用一张经典mysql复制原理图(文献12)说明这个过程,即完成了图中从BinaryLog 读取到RelayLog的写入过程。 在前文的描述中,可以观察到在RelayLog的写入过程中并没有去更新last_master_timestamp相关信息。因此更新last_master_timestamp的工作,只可能在sql进程中去完成。接下来本节将探索下ROTATE_EVENT在sql进程中的执行过程。 mysql复制代码中,sql进程的入口函数是handle_slave_sql: 在handle_slave_sql中,关键的代码是while (!sql_slave_killed(thd,rli))这个循环: 可以发现,每次循环的时候,都会去执行exec_relay_log_event这个函数: 在exec_relay_log_event中,执行对应的relaylog之后,会相应的更新last_master_timestamp。在这里并行复制模式和非并行复制模式下,更新last_master_timestamp的方式是不同的。在这里先介绍下非并行复制模式下更新last_master_timestamp的步骤。 在exec_relay_log_event中判断是否是并行复制是通过is_parallel_exec函数实现的。如果是并行复制模式则返回True,否则返回False。在非并行复制的模式下,会进入如下的代码执行: 可以看到,last_master_timestamp的值便是ev->common_header->when.tv_sec和(time_t) ev->exec_time的和。在代码中加上点调试信息,重新编译: 可以在mysqld.trace中观察到如下的调试信息,印证了前文关于非并行复制的结论。同时也可以看出,非并行复制下last_master_timestamp的更新是在binlogevent执行之前。 前文介绍了非并行复制模式下的last_master_timestamp的更新逻辑。本节将介绍下在并行复制模式下,last_master_timestamp是如何更新的。 在并行复制模式下last_master_timestamp的更新逻辑更为复杂。同时对于ROTATE_EVENT事件和普通的binlog事件更新模式也有所不同。接下来首先介绍下普通的binlog事件下last_master_timestamp的更新逻辑: 在文献1和文献2中对于并行复制逻辑的分析如下: 并行复制有一个分发队列gaq,sql线程将binlog事务读取到gaq,然后再分发给worker线程执行。并行复制时,binlog事件是并发穿插执行的,gaq中有一个checkpoint点称为lwm, lwm之前的binlog都已经执行,而lwm之后的binlog有些执行有些没有执行。 假设worker线程数为2,gap有1,2,3,4,5,6,7,8个事务。worker 1已执行的事务为1 4 6, woker 2执行的事务为2 3 ,那么lwm为4。 并行复制更新gap checkpiont时,会推进lwm点,同时更新 coordinator会调用函数mts_checkpoint_routune定期做“checkpoint”操作,将Relay_log_info.gaq中已经执行结束的事务移出队列,移除方式为从队列头开始检查,如果done为真则移出,否则停止扫描,并标记Low Water Mark为移出的事务中最大的sequence_number(lock-interval终止点) 可以看出,并行复制下last_master_timestamp的更新逻辑与lwm和mts_checkpoint_routune函数有关。mts_checkpoint_routune函数头如下: 在coordinator中会定期调用mts_checkpoint_routine将Relay_log_info.gaq中已经执行结束的事务移出队列,并且更新Low Water Mark为移出的事务中最大的sequence_number(参见mts_checkpoint_routine中如下): 在函数的最后,会执行last_master_timestamp的更新逻辑: 可以看出如果GAP为空(既work的队列为空)则更新last_master_timestamp为0,否则更新为队列中第一个是元素的timestamp。 前文提到在并行复制模式下,普通的binlog事件会被coordinator进程分发到work中去执行。并且在mts_checkpoint_routine中去推进Low Water Mark和更新last_master_timestamp。但是如果执行的binlog是一个ROTATE_EVENT事件,则coordinator进程不会将事件分发到work中,而是在coordinator进程中自己执行并更新last_master_timestamp。 对于ROTATE_EVENT事件的执行逻辑,入口依然是exec_relay_log_event函数。在函数中调用了apply_event_and_update_pos函数执行binlog事件。 在apply_event_and_update_pos函数中,会首先调用apply_event去判断当前的binlog事件是否可以被分发到work进程执行。在这里收到的binlog事件是ROTATE_EVENT,因此apply_event返回的exec_res为0,ev->worker==rli(rli 代表了coordinator进程),因此不会进入下面的if逻辑中: 在mysqld.trace 中可以观察到如下的输出: apply_event函数定义和注释如下: 因为无法被分发到work执行,因此会进入如下的执行逻辑中: 可以发现,在此调用了update_pos进行更新。因为当前的binlog事件是ROTATE_EVENT,因此会调用如下的代码: 在do_update_pos 更新last_master_timestamp 的关键逻辑如下: 可以在mysqld.trace 中观察到如下的输出: 至此,对于并行复制和非并行复制下当收到ROTATE_EVENT事件时,更新last_master_timestamp的逻辑分析全部完成。 前文分析了当mysql收到一个ROTATE_EVENT事件的时候所运行的逻辑。本节将分析下在mysql收到与自己的serverid一致的binlog事件的时候的运行逻辑。 首先来看下io thread 接收到与本身serverid一致的binlog的时候所做的操作。在handle_slave_io函数中,会在while循环中不断的调用queue_even函数。 在queue_even函数中,对于收到与自己serverid一致的binlog的处理逻辑如下: 结合注释,可以看出当mysql收到与本实例serverid一致的binlog的时候,不会将当前的binlog事件写入relaylog中。同时会完成如下的2个事情:(ps :这是一个关键的地方,在下文中将提到它的作用) 在mysqld.trace 中可以观察到如下的日志信息: 接下里看看sql进程对binlog的处理过程。入口的函数还是exec_relay_log_event,在exec_relay_log_event函数中会调用next_event函数获取一个可执行的binlog事件。在这里next_event对于非并行复制会有一个特殊的处理: 如果是非并行复制,则当读取一个binlog的时候,都会把last_master_timestamp设置成0 。因此在非并行复制下,收到与本实例serverid一致的binlog的时候,mysqld.trace中可以观察到rli->last_master_timestamp的值会一直为0: 之后的逻辑中,如果发现rli->ign_master_log_name_end[0]不为空(对应了上一个小节中的第一项:将mi->get_master_log_name() 拷贝到rli->ign_master_log_name_end中),则构造一个serverid为0的Rotate event并返回: 紧接着调用 apply_event_and_update_pos函数。在apply_event_and_update_pos函数中,如前所述如果是ROTATE EVENT 则返回0,不会被work进程并行执行,并进入update_pos逻辑中。在update_pos逻辑中关键的代码如下(sql/log_event.cc 文件): 可以见得real_event在server_id是0 的时候为false。因此当进入reset_notified_checkpoint函数后,因为update_timestamp条件(传入的值便是real_event的值)为false便不会更新last_master_timestamp。 从上文的分析可以得出如下的2个结论 : 本文分析了并行复制和非并行复制下,Seconds_Behind_Master参数值更新的相关逻辑。限于本文的作者水平有限,文中的错误在所难免,恳请大家批评指正。
3. 调查与分析过程
3.1 轮转binlog时的运行逻辑
3.1.1 写入ROTATE_EVENT
handle_slave_io: info: IO thread received event of type Rotate 5817 THD_STAGE_INFO(thd, stage_queueing_master_event_to_the_relay_log);
5818 event_buf= (const char*)mysql->net.read_pos + 1;
5819 DBUG_PRINT("info", ("IO thread received event of type %s",
5820 Log_event::get_type_str(
5821 (Log_event_type)event_buf[EVENT_TYPE_OFFSET])));
... ...
5831
5832 /* XXX: 'synced' should be updated by queue_event to indicate
5833 whether event has been synced to disk */
5834 bool synced= 0;
5835 if (queue_event(mi, event_buf, event_len))
5836 {
5837 mi->report(ERROR_LEVEL, ER_SLAVE_RELAY_LOG_WRITE_FAILURE,
5838 ER(ER_SLAVE_RELAY_LOG_WRITE_FAILURE),
5839 "could not queue event from master");
5840 goto err;
5841 } 8236 switch (event_type) {
... ...
8251 case binary_log::ROTATE_EVENT:
8252 {
8253 Rotate_log_event rev(buf, checksum_alg != binary_log::BINLOG_CHECKSUM_ALG_OFF ?
8254 event_len - BINLOG_CHECKSUM_LEN : event_len,
8255 mi->get_mi_description_event());
8256
8257 if (unlikely(process_io_rotate(mi, &rev)))
8258 {
8259 mi->report(ERROR_LEVEL, ER_SLAVE_RELAY_LOG_WRITE_FAILURE,
8260 ER(ER_SLAVE_RELAY_LOG_WRITE_FAILURE),
8261 "could not queue event from master");
8262 goto err;
8263 }
process_io_rotate: info: new (master_log_name, master_log_pos): ('dp-bin.000029', 4) 7767 /**
7768 Used by the slave IO thread when it receives a rotate event from the
7769 master.
7770
7771 Updates the master info with the place in the next binary log where
7772 we should start reading. Rotate the relay log to avoid mixed-format
7773 relay logs.
7774
7775 @param mi master_info for the slave
7776 @param rev The rotate log event read from the master
7777
7778 @note The caller must hold mi->data_lock before invoking this function.
7779
7780 @retval 0 ok
7781 @retval 1 error
7783 static int process_io_rotate(Master_info *mi, Rotate_log_event *rev)
... ...
7830 }
queue_event: info: master_log_pos: 4
harvest_bytes_written: info: counter: 769 bytes_written: 44
queue_event: info: error: 0 8656 {
8657 bool is_error= false;
8658 /* write the event to the relay log */
8659 if (likely(rli->relay_log.append_buffer(buf, event_len, mi) == 0))
8660 {
8661 mi->set_master_log_pos(mi->get_master_log_pos() + inc_pos);
8662 DBUG_PRINT("info", ("master_log_pos: %lu", (ulong) mi->get_master_log_pos()));
8663 rli->relay_log.harvest_bytes_written(rli, true/*need_log_space_lock=true*/);
... ...
}
}
3.1.2 sql 进程读取和执行ROTATE_EVENT
7158 /**
7159 Slave SQL thread entry point.
7160
7161 @param arg Pointer to Relay_log_info object that holds information
7162 for the SQL thread.
7163
7164 @return Always 0.
7165 */
7166 extern "C" void *handle_slave_sql(void *arg) 7438 while (!sql_slave_killed(thd,rli))
7439 {
7440 THD_STAGE_INFO(thd, stage_reading_event_from_the_relay_log);
7441 DBUG_ASSERT(rli->info_thd == thd);
7442 THD_CHECK_SENTRY(thd);
7443
7444 if (saved_skip && rli->slave_skip_counter == 0)
7445 {
... ...
7456 }
7457
7458 if (exec_relay_log_event(thd,rli))
7459 {
7460 ... ...
7525 }
7526 goto err;
7527 }
7528 }
5098 Top-level function for executing the next event in the relay log.
5099 This is called from the SQL thread.
5100
5101 This function reads the event from the relay log, executes it, and
5102 advances the relay log position. It also handles errors, etc.
5103
5104 This function may fail to apply the event for the following reasons:
5105
5106 - The position specfied by the UNTIL condition of the START SLAVE
5107 command is reached.
5108
5109 - It was not possible to read the event from the log.
5110
5111 - The slave is killed.
5112
5113 - An error occurred when applying the event, and the event has been
5114 tried slave_trans_retries times. If the event has been retried
5115 fewer times, 0 is returned.
5116
5117 - init_info or init_relay_log_pos failed. (These are called
5118 if a failure occurs when applying the event.)
5119
5120 - An error occurred when updating the binlog position.
5121
5122 @retval 0 The event was applied.
5123
5124 @retval 1 The event was not applied.
5125 */
5126 static int exec_relay_log_event(THD* thd, Relay_log_info* rli)
3.1.2.1 非并行复制模式下更新last_master_timestamp
5175 /*
5176 Even if we don't execute this event, we keep the master timestamp,
5177 so that seconds behind master shows correct delta (there are events
5178 that are not replayed, so we keep falling behind).
5179
5180 If it is an artificial event, or a relay log event (IO thread generated
5181 event) or ev->when is set to 0, or a FD from master, or a heartbeat
5182 event with server_id '0' then we don't update the last_master_timestamp.
5183
5184 In case of parallel execution last_master_timestamp is only updated when
5185 a job is taken out of GAQ. Thus when last_master_timestamp is 0 (which
5186 indicates that GAQ is empty, all slave workers are waiting for events from
5187 the Coordinator), we need to initialize it with a timestamp from the first
5188 event to be executed in parallel.
5189 */
5190 if ((!rli->is_parallel_exec() || rli->last_master_timestamp == 0) &&
5191 !(ev->is_artificial_event() || ev->is_relay_log_event() ||
5192 (ev->common_header->when.tv_sec == 0) ||
5193 ev->get_type_code() == binary_log::FORMAT_DESCRIPTION_EVENT ||
5194 ev->server_id == 0))
5195 {
5196 rli->last_master_timestamp= ev->common_header->when.tv_sec +
5197 (time_t) ev->exec_time;
5198 DBUG_ASSERT(rli->last_master_timestamp >= 0);
5199 }
DBUG_PRINT("info", ("before rli->last_master_timestamp = %lu", rli->last_master_timestamp));
DBUG_PRINT("info", ("before rli->is_parallel_exec() = %d", int(rli->is_parallel_exec())));
if ((!rli->is_parallel_exec() || rli->last_master_timestamp == 0) &&
!(ev->is_artificial_event() || ev->is_relay_log_event() ||
(ev->common_header->when.tv_sec == 0) ||
ev->get_type_code() == binary_log::FORMAT_DESCRIPTION_EVENT ||
ev->server_id == 0))
{
rli->last_master_timestamp= ev->common_header->when.tv_sec +
(time_t) ev->exec_time;
DBUG_PRINT("info", ("after rli->last_master_timestamp = %lu", rli->last_master_timestamp));
DBUG_PRINT("info", ("after rli->is_parallel_exec() = %d", int(rli->is_parallel_exec())));
DBUG_ASSERT(rli->last_master_timestamp >= 0);
}exec_relay_log_event: info: before rli->last_master_timestamp = 0
exec_relay_log_event: info: before rli->is_parallel_exec() = 0
exec_relay_log_event: info: after rli->last_master_timestamp = 1562201989
exec_relay_log_event: info: after rli->is_parallel_exec() = 0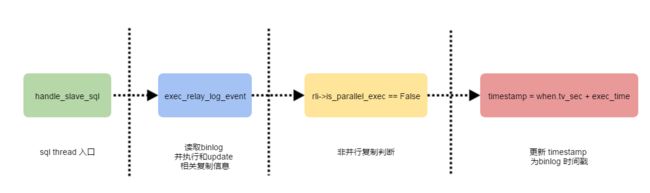
3.1.2.2 并行复制模式下更新last_master_timestamp
3.1.2.2.1 普通的binlog事件下last_master_timestamp的更新逻辑
last_master_timestamp为lwm所在事务结束的event的时间。因此,并行复制是在事务执行完成后才更新last_master_timestamp,更新是以事务为单位。同时更新gap checkpiont还受slave_checkpoint_period参数的影响。
/**
Processing rli->gaq to find out the low-water-mark (lwm) coordinates
which is stored into the cental recovery table.
@param rli pointer to Relay-log-info of Coordinator
@param period period of processing GAQ, normally derived from
@c mts_checkpoint_period
@param force if TRUE then hang in a loop till some progress
@param need_data_lock False if rli->data_lock mutex is aquired by
the caller.
@return FALSE success, TRUE otherwise
*/
bool mts_checkpoint_routine(Relay_log_info *rli, ulonglong period,
bool force, bool need_data_lock) do
{
if (!is_mts_db_partitioned(rli))
mysql_mutex_lock(&rli->mts_gaq_LOCK);
cnt= rli->gaq->move_queue_head(&rli->workers);
if (!is_mts_db_partitioned(rli))
mysql_mutex_unlock(&rli->mts_gaq_LOCK);
#ifndef DBUG_OFF
if (DBUG_EVALUATE_IF("check_slave_debug_group", 1, 0) &&
cnt != opt_mts_checkpoint_period)
sql_print_error("This an error cnt != mts_checkpoint_period");
#endif
} while (!sql_slave_killed(rli->info_thd, rli) &&
cnt == 0 && force &&
!DBUG_EVALUATE_IF("check_slave_debug_group", 1, 0) &&
(my_sleep(rli->mts_coordinator_basic_nap), 1)); /*
Update the rli->last_master_timestamp for reporting correct Seconds_behind_master.
If GAQ is empty, set it to zero.
Else, update it with the timestamp of the first job of the Slave_job_queue
which was assigned in the Log_event::get_slave_worker() function.
*/
ts= rli->gaq->empty()
? 0
: reinterpret_cast3.1.2.2.2 ROTATE_EVENT事件下last_master_timestamp的更新模式
5247 /* ptr_ev can change to NULL indicating MTS coorinator passed to a Worker */
5248 exec_res= apply_event_and_update_pos(ptr_ev, thd, rli);
5249 /*
5250 Note: the above call to apply_event_and_update_pos executes
5251 mysql_mutex_unlock(&rli->data_lock);
5252 */
5253
5254 /* For deferred events, the ptr_ev is set to NULL
5255 in Deferred_log_events::add() function.
5256 Hence deferred events wont be deleted here.
5257 They will be deleted in Deferred_log_events::rewind() funciton.
5258 */ 4709 if (reason == Log_event::EVENT_SKIP_NOT)
4710 {
4711 // Sleeps if needed, and unlocks rli->data_lock.
4712 if (sql_delay_event(ev, thd, rli))
4713 DBUG_RETURN(SLAVE_APPLY_EVENT_AND_UPDATE_POS_OK);
4714
4715 exec_res= ev->apply_event(rli);
4717 if (!exec_res && (ev->worker != rli))
4718 {
... ...
}Log_event::shall_skip: info: skip reason=0=NOT
LOG_EVENT:apply_event: info: event_type=Rotate
apply_event_and_update_pos: info: apply_event error = 0/**
Scheduling event to execute in parallel or execute it directly.
In MTS case the event gets associated with either Coordinator or a
Worker. A special case of the association is NULL when the Worker
can't be decided yet. In the single threaded sequential mode the
event maps to SQL thread rli.
@note in case of MTS failure Coordinator destroys all gathered
deferred events.
@return 0 as success, otherwise a failure.
*/
int Log_event::apply_event(Relay_log_info *rli) 4832 DBUG_PRINT("info", ("apply_event error = %d", exec_res));
4833 if (exec_res == 0)
4834 {
4835 /*
4836 Positions are not updated here when an XID is processed. To make
4837 a slave crash-safe, positions must be updated while processing a
4838 XID event and as such do not need to be updated here again.
4839
4840 However, if the event needs to be skipped, this means that it
4841 will not be processed and then positions need to be updated here.
4842
4843 See sql/rpl_rli.h for further details.
4844 */
4845 int error= 0;
4846 if (*ptr_ev &&
4847 (ev->get_type_code() != binary_log::XID_EVENT ||
4848 skip_event || (rli->is_mts_recovery() && !is_gtid_event(ev) &&
4849 (ev->ends_group() || !rli->mts_recovery_group_seen_begin) &&
4850 bitmap_is_set(&rli->recovery_groups, rli->mts_recovery_index))))
4851 {
4852 #ifndef DBUG_OFF
4853 /*
4854 This only prints information to the debug trace.
4855
4856 TODO: Print an informational message to the error log?
4857 */
... ...
4873 error= ev->update_pos(rli);
... ...
}
}/*
Got a rotate log event from the master.
This is mainly used so that we can later figure out the logname and
position for the master.
We can't rotate the slave's BINlog as this will cause infinitive rotations
in a A -> B -> A setup.
The NOTES below is a wrong comment which will disappear when 4.1 is merged.
This must only be called from the Slave SQL thread, since it calls
flush_relay_log_info().
@retval
0 ok
*/
int Rotate_log_event::do_update_pos(Relay_log_info *rli)if (rli->is_parallel_exec())
{
bool real_event= server_id && !is_artificial_event();
rli->reset_notified_checkpoint(0,
real_event ?
common_header->when.tv_sec +
(time_t) exec_time : 0,
true/*need_data_lock=true*/,
real_event? true : false);
}Rotate_log_event::do_update_pos: info: server_id=248; ::server_id=236
Rotate_log_event::do_update_pos: info: new_log_ident: dp-bin.000063
Rotate_log_event::do_update_pos: info: pos: 4
Rotate_log_event::do_update_pos: info: old group_master_log_name: 'dp-bin.000062' old group_master_log_pos: 154
Relay_log_info::inc_group_relay_log_pos: info: log_pos: 4 group_master_log_pos: 154
Rotate_log_event::do_update_pos: info: new group_master_log_name: 'dp-bin.000063' new group_master_log_pos: 4
Rotate_log_event::do_update_pos: info: ------> 1562684581(此处为本文加入的调试信息,在reset_notified_checkpoint更新last_master_timestamp的时候打印出。)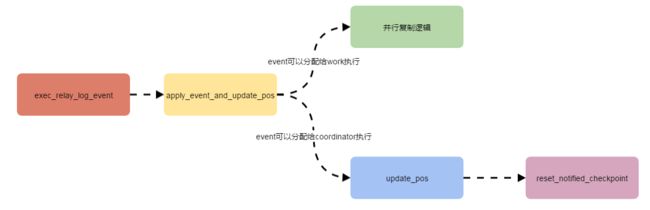
3.2 da执行与本实例serverid一致的binlog时的运行逻辑
3.2.1 io thread 处理与本实例serverid一致的binlog
5740 while (!io_slave_killed(thd,mi))
5741 {
5742 ulong event_len;
... ...
5750 event_len= read_event(mysql, mi, &suppress_warnings);
... ...
5813 /* XXX: 'synced' should be updated by queue_event to indicate
5814 whether event has been synced to disk */
5815 bool synced= 0;
5816 if (queue_event(mi, event_buf, event_len))
5817 {
5818 mi->report(ERROR_LEVEL, ER_SLAVE_RELAY_LOG_WRITE_FAILURE,
5819 ER(ER_SLAVE_RELAY_LOG_WRITE_FAILURE),
5820 "could not queue event from master");
5821 goto err;
5822 }
... ...
} 8534 /*
8535 If this event is originating from this server, don't queue it.
8536 We don't check this for 3.23 events because it's simpler like this; 3.23
8537 will be filtered anyway by the SQL slave thread which also tests the
8538 server id (we must also keep this test in the SQL thread, in case somebody
8539 upgrades a 4.0 slave which has a not-filtered relay log).
8540
8541 ANY event coming from ourselves can be ignored: it is obvious for queries;
8542 for STOP_EVENT/ROTATE_EVENT/START_EVENT: these cannot come from ourselves
8543 (--log-slave-updates would not log that) unless this slave is also its
8544 direct master (an unsupported, useless setup!).
8545 */
... ...
8560 if ((s_id == ::server_id && !mi->rli->replicate_same_server_id) ||
8561 /*
8562 the following conjunction deals with IGNORE_SERVER_IDS, if set
8563 If the master is on the ignore list, execution of
8564 format description log events and rotate events is necessary.
8565 */
8566 (mi->ignore_server_ids->dynamic_ids.size() > 0 &&
8567 mi->shall_ignore_server_id(s_id) &&
8568 /* everything is filtered out from non-master */
8569 (s_id != mi->master_id ||
8570 /* for the master meta information is necessary */
8571 (event_type != binary_log::FORMAT_DESCRIPTION_EVENT &&
8572 event_type != binary_log::ROTATE_EVENT))))
8573 {
8574 /*
8575 Do not write it to the relay log.
8576 a) We still want to increment mi->get_master_log_pos(), so that we won't
8577 re-read this event from the master if the slave IO thread is now
8578 stopped/restarted (more efficient if the events we are ignoring are big
8579 LOAD DATA INFILE).
8580 b) We want to record that we are skipping events, for the information of
8581 the slave SQL thread, otherwise that thread may let
8582 rli->group_relay_log_pos stay too small if the last binlog's event is
8583 ignored.
8584 But events which were generated by this slave and which do not exist in
8585 the master's binlog (i.e. Format_desc, Rotate & Stop) should not increment
8586 mi->get_master_log_pos().
8587 If the event is originated remotely and is being filtered out by
8588 IGNORE_SERVER_IDS it increments mi->get_master_log_pos()
8589 as well as rli->group_relay_log_pos.
8590 */
8591 if (!(s_id == ::server_id && !mi->rli->replicate_same_server_id) ||
8592 (event_type != binary_log::FORMAT_DESCRIPTION_EVENT &&
8593 event_type != binary_log::ROTATE_EVENT &&
8594 event_type != binary_log::STOP_EVENT))
8595 {
8596 mi->set_master_log_pos(mi->get_master_log_pos() + inc_pos);
8597 memcpy(rli->ign_master_log_name_end, mi->get_master_log_name(), FN_REFLEN);
8598 DBUG_ASSERT(rli->ign_master_log_name_end[0]);
8599 rli->ign_master_log_pos_end= mi->get_master_log_pos();
8600 }
8601 rli->relay_log.signal_update(); // the slave SQL thread needs to re-check
8602 DBUG_PRINT("info", ("master_log_pos: %lu, event originating from %u server, ignored",
8603 (ulong) mi->get_master_log_pos(), uint4korr(buf + SERVER_ID_OFFSET)));
8604 }
queue_event: info: master_log_pos: 219, event originating from 236 server, ignored
queue_event: info: error: 03.2.2 sql thread 处理与本实例serverid一致的binlog
9175 if (!rli->is_parallel_exec())
9176 rli->last_master_timestamp= 0;next_event: info: seeing an ignored end segment
handle_slave_io: info: IO thread received event of type Query
exec_relay_log_event: info: ================================before rli->last_master_timestamp = 0
exec_relay_log_event: info: ================================before rli->is_parallel_exec() = 0
apply_event_and_update_pos: info: thd->options: ; rli->last_event_start_time: 0
Log_event::shall_skip: info: ev->server_id=0, ::server_id=236, rli->replicate_same_server_id=0, rli->slave_skip_counter=0
Log_event::shall_skip: info: skip reason=0=NOT
LOG_EVENT:apply_event: info: event_type=Rotate
... ...
... ...
exec_relay_log_event: info: ================================before rli->last_master_timestamp = 0
exec_relay_log_event: info: ================================before rli->is_parallel_exec() = 0
apply_event_and_update_pos: info: thd->options: ; rli->last_event_start_time: 0
Log_event::shall_skip: info: ev->server_id=0, ::server_id=236, rli->replicate_same_server_id=0, rli->slave_skip_counter=0
Log_event::shall_skip: info: skip reason=0=NOT
LOG_EVENT:apply_event: info: event_type=Rotate
apply_event_and_update_pos: info: apply_event error = 0
apply_event_and_update_pos: info: OPTION_BEGIN: 0; IN_STMT: 0
Rotate_log_event::do_update_pos: info: server_id=0; ::server_id=236
Rotate_log_event::do_update_pos: info: new_log_ident: dp-bin.000069
Rotate_log_event::do_update_pos: info: pos: 282
MYSQL_BIN_LOG::signal_update: info: signal_cnt : 13
queue_event: info: master_log_pos: 326, event originating from 236 server, ignored
queue_event: info: error: 0 9181 if (rli->ign_master_log_name_end[0])
9182 {
9183 /* We generate and return a Rotate, to make our positions advance */
9184 DBUG_PRINT("info",("seeing an ignored end segment"));
9185 ev= new Rotate_log_event(rli->ign_master_log_name_end,
9186 0, rli->ign_master_log_pos_end,
9187 Rotate_log_event::DUP_NAME);
9188 rli->ign_master_log_name_end[0]= 0;
9189 mysql_mutex_unlock(log_lock);
9190 if (unlikely(!ev))
9191 {
9192 errmsg= "Slave SQL thread failed to create a Rotate event "
9193 "(out of memory?), SHOW SLAVE STATUS may be inaccurate";
9194 goto err;
9195 }
9196 ev->server_id= 0; // don't be ignored by slave SQL thread
9197 DBUG_RETURN(ev);
9198 } 6649 if (rli->is_parallel_exec())
6650 {
6651 bool real_event= server_id && !is_artificial_event();
6652 rli->reset_notified_checkpoint(0,
6653 real_event ?
6654 common_header->when.tv_sec +
6655 (time_t) exec_time : 0,
6656 true/*need_data_lock=true*/,
6657 real_event? true : false);
6658 } 262 /**
263 This method is called in mts_checkpoint_routine() to mark that each
264 worker is required to adapt to a new checkpoint data whose coordinates
265 are passed to it through GAQ index.
266
267 Worker notices the new checkpoint value at the group commit to reset
268 the current bitmap and starts using the clean bitmap indexed from zero
269 of being reset checkpoint_seqno.
270
271 New seconds_behind_master timestamp is installed.
272
273 @param shift number of bits to shift by Worker due to the
274 current checkpoint change.
275 @param new_ts new seconds_behind_master timestamp value
276 unless zero. Zero could be due to FD event
277 or fake rotate event.
278 @param need_data_lock False if caller has locked @c data_lock
279 @param update_timestamp if true, this function will update the
280 rli->last_master_timestamp.
281 */
282 void Relay_log_info::reset_notified_checkpoint(ulong shift, time_t new_ts,
283 bool need_data_lock,
284 bool update_timestamp)
285 {
... ...
330 if (update_timestamp)
331 {
332 if (need_data_lock)
333 mysql_mutex_lock(&data_lock);
334 else
335 mysql_mutex_assert_owner(&data_lock);
336 last_master_timestamp= new_ts;
337 if (need_data_lock)
338 mysql_mutex_unlock(&data_lock);
339 }
340 }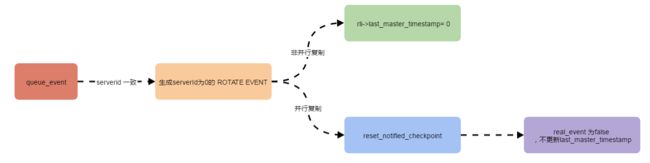
3.3 小结
4. 总结