- Python 之禅
- 参数传递是值传递还是引用传递
- 深拷贝与浅拷贝
- 垃圾回收机制
- del
- 元类 (metaclass)
- 新式类和旧式类
- type与object
- 全局解释器锁
- Python的编码
- with(上下文管理)
- lambda(匿名函数)
- 高阶函数
- yield
- 装饰器
- @property
- 函数参数传递
- 参数默认值的继承性
- 闭包与延迟锁定
- Pythonic
- Python的自省
- Timsort
- 练习
Python 进阶 & 面试知识整理
Python 之禅
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Python之禅 by Tim Peters
优美胜于丑陋(Python 以编写优美的代码为目标)
明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)
简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)
复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)
扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)
间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)
可读性很重要(优美的代码是可读的)
即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上)
不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)
当存在多种可能,不要尝试去猜测
而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)
虽然这并不容易,因为你不是 Python 之父(这里的 Dutch 是指 Guido )
做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量)
如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准)
命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)
参数传递是值传递还是引用传递
引用传递
都是引用,对于不可改变的数据类型来说,不能改变,如果修改了,事实上是新建一个对象来对待。
或者说
Python中有可变对象(比如列表List)和不可变对象(比如字符串),在参数传递时分为两种情况:
- 对于不可变对象作为函数参数,相当于C系语言的值传递;
- 对于可变对象作为函数参数,相当于C系语言的引用传递。
再或者
传值方式等价于python赋值号(=),但不应该说是浅拷贝。
以list为例,浅拷贝可变对象时(如list),会创建一个新的list对象,并让新对象内部的每一个元素指向原对象每个元素指向的元素;而赋值号将不会创建新对象,而是直接创建一个引用连接到原对象。函数传值是后者,可以写一个函数,在函数里面打印传入参数的id(),与原值的id()是一样的,因此是直接赋值而不是浅拷贝。
深拷贝与浅拷贝
- Python中对象的赋值都是进行对象引用(内存地址)传递
- 使用copy.copy(),可以进行对象的浅拷贝,它复制了对象,但对于对象中的元素,依然使用原始的引用.
- 如果需要复制一个容器对象,以及它里面的所有元素(包含元素的子元素),可以使用copy.deepcopy()进行深拷贝
- 对于非容器类型(如数字、字符串、和其他'原子'类型的对象)没有被拷贝一说
- 如果元祖变量只包含原子类型对象,则不能深拷贝
引用
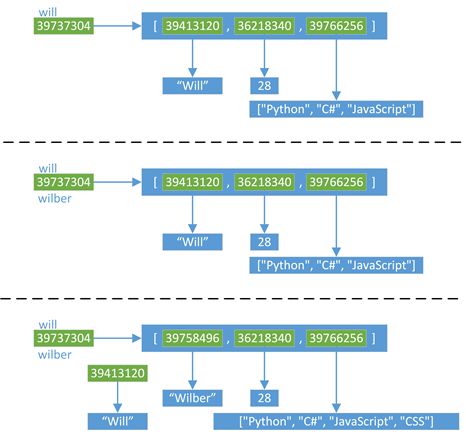
浅拷贝
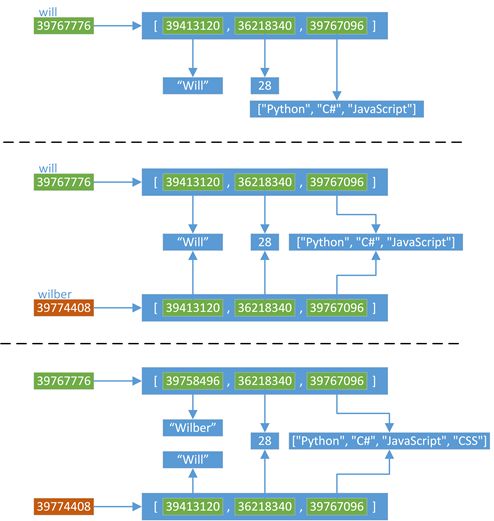
深拷贝
垃圾回收机制
引用计数
python里每一个东西都是对象,它们的核心就是一个结构体:PyObject
typedef struct_object
{
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少
#define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数
#define Py_DECREF(op) //减少计数
if (--(op)->ob_refcnt != 0) ;
else __Py_Dealloc((PyObject *)(op))
当引用计数为0时,该对象生命就结束了。
引用计数机制的优点:
- 简单
- 实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
引用计数机制的缺点:
- 维护引用计数消耗资源
- 循环引用
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
list1与list2相互引用,如果不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收,这将是致命的。
对于如今的强大硬件,缺点1尚可接受,但是循环引用导致内存泄露,注定python还将引入新的回收机制。
(标记清除和分代收集)
基于零代算法的循环引用检测及垃圾回收机制
Python中的循环数据结构以及引用计数
我们知道在Python中,每个对象都保存了一个称为引用计数的整数值,来追踪到底有多少引用指向了这个对象。无论何时,如果我们程序中的一个变量或其他对象引用了目标对象,Python将会增加这个计数值,而当程序停止使用这个对象,则Python会减少这个计数值。一旦计数值被减到零,Python将会释放这个对象以及回收相关内存空间。
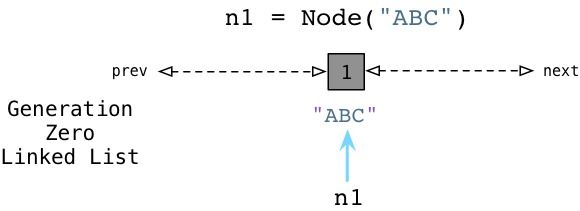
从六十年代开始,计算机科学界就面临了一个严重的理论问题,那就是针对引用计数这种算法来说,如果一个数据结构引用了它自身,即如果这个数据结构是一个循环数据结构,那么某些引用计数值是肯定无法变成零的。为了更好地理解这个问题,让我们举个例子。下面的代码展示了一些上周我们所用到的节点类:

我们有一个构造器(在Python中叫做 init ),在一个实例变量中存储一个单独的属性。在类定义之后我们创建两个节点,ABC以及DEF,在图中为左边的矩形框。两个节点的引用计数都被初始化为1,因为各有两个引用指向各个节点(n1和n2)。
现在,让我们在节点中定义两个附加的属性,next以及prev:

跟Ruby不同的是,Python中你可以在代码运行的时候动态定义实例变量或对象属性。这看起来似乎有点像Ruby缺失了某些有趣的魔法。(声明下我不是一个Python程序员,所以可能会存在一些命名方面的错误)。我们设置 n1.next 指向 n2,同时设置 n2.prev 指回 n1。现在,我们的两个节点使用循环引用的方式构成了一个双端链表。同时请注意到 ABC 以及 DEF 的引用计数值已经增加到了2。这里有两个指针指向了每个节点:首先是 n1 以及 n2,其次就是 next 以及 prev。
现在,假定我们的程序不再使用这两个节点了,我们将 n1 和 n2 都设置为null(Python中是None)。

好了,Python会像往常一样将每个节点的引用计数减少到1。
在Python中的零代(Generation Zero)
请注意在以上刚刚说到的例子中,我们以一个不是很常见的情况结尾:我们有一个“孤岛”或是一组未使用的、互相指向的对象,但是谁都没有外部引用。换句话说,我们的程序不再使用这些节点对象了,所以我们希望Python的垃圾回收机制能够足够智能去释放这些对象并回收它们占用的内存空间。但是这不可能,因为所有的引用计数都是1而不是0。Python的引用计数算法不能够处理互相指向自己的对象。
当然,上边举的是一个故意设计的例子,但是你的代码也许会在不经意间包含循环引用并且你并未意识到。事实上,当你的Python程序运行的时候它将会建立一定数量的“浮点数垃圾”,Python的GC不能够处理未使用的对象因为应用计数值不会到零。
这就是为什么Python要引入Generational GC算法的原因!正如Ruby使用一个链表(free list)来持续追踪未使用的、自由的对象一样,Python使用一种不同的链表来持续追踪活跃的对象。而不将其称之为“活跃列表”,Python的内部C代码将其称为零代(Generation Zero)。每次当你创建一个对象或其他什么值的时候,Python会将其加入零代链表:
从上边可以看到当我们创建ABC节点的时候,Python将其加入零代链表。请注意到这并不是一个真正的列表,并不能直接在你的代码中访问,事实上这个链表是一个完全内部的Python运行时。
相似的,当我们创建DEF节点的时候,Python将其加入同样的链表:

现在零代包含了两个节点对象。(他还将包含Python创建的每个其他值,与一些Python自己使用的内部值。)
检测循环引用
随后,Python会循环遍历零代列表上的每个对象,检查列表中每个互相引用的对象,根据规则减掉其引用计数。在这个过程中,Python会一个接一个的统计内部引用的数量以防过早地释放对象。
为了便于理解,来看一个例子:

从上面可以看到 ABC 和 DEF 节点包含的引用数为1.有三个其他的对象同时存在于零代链表中,蓝色的箭头指示了有一些对象正在被零代链表之外的其他对象所引用。(接下来我们会看到,Python中同时存在另外两个分别被称为一代和二代的链表)。这些对象有着更高的引用计数因为它们正在被其他指针所指向着。
接下来你会看到Python的GC是如何处理零代链表的。

通过识别内部引用,Python能够减少许多零代链表对象的引用计数。在上图的第一行中你能够看见ABC和DEF的引用计数已经变为零了,这意味着收集器可以释放它们并回收内存空间了。剩下的活跃的对象则被移动到一个新的链表:一代链表。
从某种意义上说,Python的GC算法类似于Ruby所用的标记回收算法。周期性地从一个对象到另一个对象追踪引用以确定对象是否还是活跃的,正在被程序所使用的,这正类似于Ruby的标记过程。
Python中的GC阈值
Python什么时候会进行这个标记过程?随着你的程序运行,Python解释器保持对新创建的对象,以及因为引用计数为零而被释放掉的对象的追踪。从理论上说,这两个值应该保持一致,因为程序新建的每个对象都应该最终被释放掉。
当然,事实并非如此。因为循环引用的原因,并且因为你的程序使用了一些比其他对象存在时间更长的对象,从而被分配对象的计数值与被释放对象的计数值之间的差异在逐渐增长。一旦这个差异累计超过某个阈值,则Python的收集机制就启动了,并且触发上边所说到的零代算法,释放“浮动的垃圾”,并且将剩下的对象移动到一代列表。
随着时间的推移,程序所使用的对象逐渐从零代列表移动到一代列表。而Python对于一代列表中对象的处理遵循同样的方法,一旦被分配计数值与被释放计数值累计到达一定阈值,Python会将剩下的活跃对象移动到二代列表。
通过这种方法,你的代码所长期使用的对象,那些你的代码持续访问的活跃对象,会从零代链表转移到一代再转移到二代。通过不同的阈值设置,Python可以在不同的时间间隔处理这些对象。Python处理零代最为频繁,其次是一代然后才是二代。
弱代假说
来看看代垃圾回收算法的核心行为:垃圾回收器会更频繁的处理新对象。一个新的对象即是你的程序刚刚创建的,而一个来的对象则是经过了几个时间周期之后仍然存在的对象。Python会在当一个对象从零代移动到一代,或是从一代移动到二代的过程中提升(promote)这个对象。
为什么要这么做?这种算法的根源来自于弱代假说(weak generational hypothesis)。这个假说由两个观点构成:首先是年轻的对象通常死得也快,而老对象则很有可能存活更长的时间。
假定现在我用Python或是Ruby创建一个新对象:
根据假说,我的代码很可能仅仅会使用ABC很短的时间。这个对象也许仅仅只是一个方法中的中间结果,并且随着方法的返回这个对象就将变成垃圾了。大部分的新对象都是如此般地很快变成垃圾。然而,偶尔程序会创建一些很重要的,存活时间比较长的对象-例如web应用中的session变量或是配置项。
通过频繁的处理零代链表中的新对象,Python的垃圾收集器将把时间花在更有意义的地方:它处理那些很快就可能变成垃圾的新对象。同时只在很少的时候,当满足阈值的条件,收集器才回去处理那些老变量。
del
删除元素
>>> a = [1, "two", 3, "four"]
>>> del a[0] #删除列表a中,下标为0的元素
>>> a
['two', 3, 'four']
>>> a.append("five")
>>> a.append(6)
>>> a
['two', 3, 'four', 'five', 6]
>>> del a[2:4] #删除a从下标为2到4的元素,含头不含尾
>>> a
删除引用
>>> x = 1
>>> del x
>>> x
Traceback (most recent call last):
File "", line 1, in
x
NameError: name 'x' is not defined
>>> x = ['Hello','world']
>>> y = x
>>> y
['Hello', 'world']
>>> x
['Hello', 'world']
>>> del x
>>> x
Traceback (most recent call last):
File "", line 1, in
x
NameError: name 'x' is not defined
>>> y
['Hello', 'world']
>>>
可以看到x和y指向同一个列表,但是删除x后,y并没有受到影响。del的是引用,而不是对象
元类 (metaclass)
类也是对象
在理解元类之前,你需要先掌握Python中的类。Python中类的概念借鉴于Smalltalk,这显得有些奇特。在大多数编程语言中,类就是一组用来描述如何生成一个对象的代码段。在Python中这一点仍然成立:
>>> class ObjectCreator(object):
… pass
…
>>> my_object = ObjectCreator()
>>> print my_object
<__main__.ObjectCreator object at 0x8974f2c>
但是,Python中的类还远不止如此。类同样也是一种对象。是的,没错,就是对象。只要你使用关键字class,Python解释器在执行的时候就会创建一个对象。下面的代码段:
>>> class ObjectCreator(object):
… pass
…
将在内存中创建一个对象,名字就是ObjectCreator。这个对象(类)自身拥有创建对象(类实例)的能力,而这就是为什么它是一个类的原因。但是,它的本质仍然是一个对象,于是乎你可以对它做如下的操作:
- 你可以将它赋值给一个变量
- 你可以拷贝它
- 你可以为它增加属性
- 你可以将它作为函数参数进行传递
下面是示例:
# 你可以打印一个类,因为它其实也是一个对象
>>> print ObjectCreator
# 你可以将类做为参数传给函数
>>> def echo(o):
… print o
…
>>> echo(ObjectCreator)
# 你可以为类增加属性
>>> print hasattr(ObjectCreator, 'new_attribute')
Fasle
>>> ObjectCreator.new_attribute = 'foo'
>>> print hasattr(ObjectCreator, 'new_attribute')
True
>>> print ObjectCreator.new_attribute
foo
# 你可以将类赋值给一个变量
>>> ObjectCreatorMirror = ObjectCreator
>>> print ObjectCreatorMirror()
<__main__.ObjectCreator object at 0x8997b4c>
动态地创建类
因为类也是对象,你可以在运行时动态的创建它们,就像其他任何对象一样。首先,你可以在函数中创建类,使用class关键字即可。
>>> def choose_class(name):
… if name == 'foo':
… class Foo(object):
… pass
… return Foo # 返回的是类,不是类的实例
… else:
… class Bar(object):
… pass
… return Bar
…
>>> MyClass = choose_class('foo')
>>> print MyClass # 函数返回的是类,不是类的实例
>>> print MyClass() # 你可以通过这个类创建类实例,也就是对象
<__main__.Foo object at 0x89c6d4c>
但这还不够动态,因为你仍然需要自己编写整个类的代码。由于类也是对象,所以它们必须是通过什么东西来生成的才对。当你使用class关键字时,Python解释器自动创建这个对象。但就和Python中的大多数事情一样,Python仍然提供给你手动处理的方法。还记得内建函数type吗?这个古老但强大的函数能够让你知道一个对象的类型是什么,就像这样:
>>> print type(1)
>>> print type("1")
>>> print type(ObjectCreator)
>>> print type(ObjectCreator())
这里,type有一种完全不同的能力,它也能动态的创建类。
type可以接受一个类的描述作为参数,然后返回一个类。(我知道,根据传入参数的不同,同一个函数拥有两种完全不同的用法是一件很傻的事情,但这在Python中是为了保持向后兼容性)
type可以像这样工作:
type(类名, 父类的元组(针对继承的情况,可以为空),包含属性的字典(名称和值))
比如下面的代码:
>>> class MyShinyClass(object):
… pass
可以手动像这样创建:
>>> MyShinyClass = type('MyShinyClass', (), {}) # 返回一个类对象
>>> print MyShinyClass
>>> print MyShinyClass() # 创建一个该类的实例
<__main__.MyShinyClass object at 0x8997cec>
你会发现我们使用“MyShinyClass”作为类名,并且也可以把它当做一个变量来作为类的引用。类和变量是不同的,这里没有任何理由把事情弄的复杂。
type 接受一个字典来为类定义属性,因此:
>>> class Foo(object):
… bar = True
可以翻译为:
>>> Foo = type('Foo', (), {'bar':True})
并且可以将Foo当成一个普通的类一样使用:
>>> print Foo
>>> print Foo.bar
True
>>> f = Foo()
>>> print f
<__main__.Foo object at 0x8a9b84c>
>>> print f.bar
True
当然,你可以向这个类继承,所以,如下的代码:
>>> class FooChild(Foo):
… pass
就可以写成:
>>> FooChild = type('FooChild', (Foo,),{})
>>> print FooChild
>>> print FooChild.bar # bar属性是由Foo继承而来
True
最终你会希望为你的类增加方法。只需要定义一个有着恰当签名的函数并将其作为属性赋值就可以了。
>>> def echo_bar(self):
… print self.bar
…
>>> FooChild = type('FooChild', (Foo,), {'echo_bar': echo_bar})
>>> hasattr(Foo, 'echo_bar')
False
>>> hasattr(FooChild, 'echo_bar')
True
>>> my_foo = FooChild()
>>> my_foo.echo_bar()
True
你可以看到,在Python中,类也是对象,你可以动态的创建类。这就是当你使用关键字class时Python在幕后做的事情,而这就是通过元类来实现的。
到底什么是元类
元类就是用来创建类的“东西”。你创建类就是为了创建类的实例对象,不是吗?但是我们已经学习到了Python中的类也是对象。好吧,元类就是用来创建这些类(对象)的,元类就是类的类,你可以这样理解 为:
MyClass = MetaClass()
MyObject = MyClass()
你已经看到了type可以让你像这样做:
MyClass = type('MyClass', (), {})
这是因为函数type实际上是一个元类。type就是Python在背后用来创建所有类的元类。现在你想知道那为什么type会全部采用小写形式而不是Type呢?好吧,我猜这是为了和str保持一致性,str是用来创建字符串对象的类,而int是用来创建整数对象的类。type就是创建类对象的类。你可以通过检查__class__属性来看到这一点。Python中所有的东西,注意,我是指所有的东西——都是对象。这包括整数、字符串、函数以及类。它们全部都是对象,而且它们都是从一个类创建而来。
>>> age = 35
>>> age.__class__
>>> name = 'bob'
>>> name.__class__
>>> def foo(): pass
>>>foo.__class__
>>> class Bar(object): pass
>>> b = Bar()
>>> b.__class__
现在,对于任何一个__class__的__class__属性又是什么呢?
>>> a.__class__.__class__
>>> age.__class__.__class__
>>> foo.__class__.__class__
>>> b.__class__.__class__
因此,元类就是创建类这种对象的东西。如果你喜欢的话,可以把元类称为“类工厂”(不要和工厂类搞混了:D) type就是Python的内建元类,当然了,你也可以创建自己的元类。
__metaclass__ 属性
你可以在写一个类的时候为其添加__metaclass__属性。
class Foo():
__metaclass__ = something…
[…]
这里要额外注意(原文翻译有问题):
自定义元类不能从'object'继承,metaclass是类的模板,所以必须从type类型派生。可以这么定义一个元类
class foo(type),然后这么用 class myfoo(metaclass=foo)
全局__metaclass__ 只对旧式类有效。加上object作为参数就不对了。
如果你这么做了,Python就会用元类来创建类Foo。小心点,这里面有些技巧。你首先写下class Foo(object),但是类对象Foo还没有在内存中创建。Python会在类的定义中寻找__metaclass__属性,如果找到了,Python就会用它来创建类Foo,如果没有找到,就会用内建的type来创建这个类。把下面这段话反复读几次。当你写如下代码时 :
class Foo(Bar):
pass
Python做了如下的操作:
Foo中有__metaclass__这个属性吗?如果是,Python会在内存中通过__metaclass__创建一个名字为Foo的类对象(我说的是类对象,请紧跟我的思路)。如果Python没有找到__metaclass__,它会继续在Bar(父类)中寻找__metaclass__属性,并尝试做和前面同样的操作。如果Python在任何父类中都找不到__metaclass__,它就会在模块层次中去寻找__metaclass__,并尝试做同样的操作。如果还是找不到__metaclass__,Python就会用内置的type来创建这个类对象。
现在的问题就是,你可以在__metaclass__中放置些什么代码呢?答案就是:可以创建一个类的东西。那么什么可以用来创建一个类呢?type,或者任何使用到type或者子类化type的东东都可以。
自定义元类
元类的主要目的就是为了当创建类时能够自动地改变类。通常,你会为API做这样的事情,你希望可以创建符合当前上下文的类。假想一个很傻的例子,你决定在你的模块里所有的类的属性都应该是大写形式。有好几种方法可以办到,但其中一种就是通过在模块级别设定__metaclass__。采用这种方法,这个模块中的所有类都会通过这个元类来创建,我们只需要告诉元类把所有的属性都改成大写形式就万事大吉了。
幸运的是,__metaclass__实际上可以被任意调用,它并不需要是一个正式的类(我知道,某些名字里带有‘class’的东西并不需要是一个class,画画图理解下,这很有帮助)。所以,我们这里就先以一个简单的函数作为例子开始。
# 元类会自动将你通常传给‘type’的参数作为自己的参数传入
def upper_attr(future_class_name, future_class_parents, future_class_attr):
'''返回一个类对象,将属性都转为大写形式'''
# 选择所有不以'__'开头的属性
attrs = ((name, value) for name, value in future_class_attr.items() if not name.startswith('__'))
# 将它们转为大写形式
uppercase_attr = dict((name.upper(), value) for name, value in attrs)
# 通过'type'来做类对象的创建
return type(future_class_name, future_class_parents, uppercase_attr)
__metaclass__ = upper_attr # 这会作用到这个模块中的所有类
class Foo(object):
# 我们也可以只在这里定义__metaclass__,这样就只会作用于这个类中
bar = 'bip'
print hasattr(Foo, 'bar')
# 输出: False
print hasattr(Foo, 'BAR')
# 输出:True
f = Foo()
print f.BAR
# 输出:'bip'
现在让我们再做一次,这一次用一个真正的class来当做元类。
# 请记住,'type'实际上是一个类,就像'str'和'int'一样
# 所以,你可以从type继承
class UpperAttrMetaClass(type):
# __new__ 是在__init__之前被调用的特殊方法
# __new__是用来创建对象并返回之的方法
# 而__init__只是用来将传入的参数初始化给对象
# 你很少用到__new__,除非你希望能够控制对象的创建
# 这里,创建的对象是类,我们希望能够自定义它,所以我们这里改写__new__
# 如果你希望的话,你也可以在__init__中做些事情
# 还有一些高级的用法会涉及到改写__call__特殊方法,但是我们这里不用
def __new__(upperattr_metaclass, future_class_name, future_class_parents, future_class_attr):
attrs = ((name, value) for name, value in future_class_attr.items() if not name.startswith('__'))
uppercase_attr = dict((name.upper(), value) for name, value in attrs)
return type(future_class_name, future_class_parents, uppercase_attr)
但是,这种方式其实不是OOP。我们直接调用了type,而且我们没有改写父类的__new__方法。现在让我们这样去处理:
class UpperAttrMetaclass(type):
def __new__(upperattr_metaclass, future_class_name, future_class_parents, future_class_attr):
attrs = ((name, value) for name, value in future_class_attr.items() if not name.startswith('__'))
uppercase_attr = dict((name.upper(), value) for name, value in attrs)
# 复用type.__new__方法
# 这就是基本的OOP编程,没什么魔法
return type.__new__(upperattr_metaclass, future_class_name, future_class_parents, uppercase_attr)
你可能已经注意到了有个额外的参数upperattr_metaclass,这并没有什么特别的。类方法的第一个参数总是表示当前的实例,就像在普通的类方法中的self参数一样。当然了,为了清晰起见,这里的名字我起的比较长。但是就像self一样,所有的参数都有它们的传统名称。因此,在真实的产品代码中一个元类应该是像这样的:
class UpperAttrMetaclass(type):
def __new__(cls, name, bases, dct):
attrs = ((name, value) for name, value in dct.items() if not name.startswith('__')
uppercase_attr = dict((name.upper(), value) for name, value in attrs)
return type.__new__(cls, name, bases, uppercase_attr)
如果使用super方法的话,我们还可以使它变得更清晰一些,这会缓解继承(是的,你可以拥有元类,从元类继承,从type继承)
class UpperAttrMetaclass(type):
def __new__(cls, name, bases, dct):
attrs = ((name, value) for name, value in dct.items() if not name.startswith('__'))
uppercase_attr = dict((name.upper(), value) for name, value in attrs)
return super(UpperAttrMetaclass, cls).__new__(cls, name, bases, uppercase_attr)
就是这样,除此之外,关于元类真的没有别的可说的了。使用到元类的代码比较复杂,这背后的原因倒并不是因为元类本身,而是因为你通常会使用元类去做一些晦涩的事情,依赖于自省,控制继承等等。确实,用元类来搞些“黑暗魔法”是特别有用的,因而会搞出些复杂的东西来。但就元类本身而言,它们其实是很简单的:
- 拦截类的创建
- 修改类
- 返回修改之后的类
为什么要用metaclass类而不是函数?
由于__metaclass__可以接受任何可调用的对象,那为何还要使用类呢,因为很显然使用类会更加复杂啊?这里有好几个原因:
- 意图会更加清晰。当你读到UpperAttrMetaclass(type)时,你知道接下来要发生什么。
- 你可以使用OOP编程。元类可以从元类中继承而来,改写父类的方法。元类甚至还可以使用元类。
- 你可以把代码组织的更好。当你使用元类的时候肯定不会是像我上面举的这种简单场景,通常都是针对比较复杂的问题。将多个方法归总到一个类中会很有帮助,也会使得代码更容易阅读。
- 你可以使用__new__, __init__以及__call__这样的特殊方法。它们能帮你处理不同的任务。就算通常你可以把所有的东西都在__new__里处理掉,有些人还是觉得用__init__更舒服些。
- 哇哦,这东西的名字是metaclass,肯定非善类,我要小心!
究竟为什么要使用元类?
现在回到我们的大主题上来,究竟是为什么你会去使用这样一种容易出错且晦涩的特性?好吧,一般来说,你根本就用不上它:
“元类就是深度的魔法,99%的用户应该根本不必为此操心。如果你想搞清楚究竟是否需要用到元类,那么你就不需要它。那些实际用到元类的人都非常清楚地知道他们需要做什么,而且根本不需要解释为什么要用元类。” —— Python界的领袖 Tim Peters
元类的主要用途是创建API。一个典型的例子是Django ORM。它允许你像这样定义:
class Person(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField()
但是如果你像这样做的话:
guy = Person(name='bob', age='35')
print guy.age
这并不会返回一个IntegerField对象,而是会返回一个int,甚至可以直接从数据库中取出数据。这是有可能的,因为models.Model定义了__metaclass__, 并且使用了一些魔法能够将你刚刚定义的简单的Person类转变成对数据库的一个复杂hook。Django框架将这些看起来很复杂的东西通过暴露出一个简单的使用元类的API将其化简,通过这个API重新创建代码,在背后完成真正的工作。
结语
首先,你知道了类其实是能够创建出类实例的对象。好吧,事实上,类本身也是实例,当然,它们是元类的实例。
>>>class Foo(object): pass
>>> id(Foo)
142630324
Python中的一切都是对象,它们要么是类的实例,要么是元类的实例,除了type。type实际上是它自己的元类,在纯Python环境中这可不是你能够做到的,这是通过在实现层面耍一些小手段做到的。其次,元类是很复杂的。对于非常简单的类,你可能不希望通过使用元类来对类做修改。你可以通过其他两种技术来修改类:
- 猴子补丁 (Monkey patching)
class Foo(object):
def bar(self):
print 'Foo.bar'
def bar(self):
print 'Modified bar' Foo().bar()
Foo.bar = bar
Foo().bar()
- 类装饰器(class decorators)
新式类和旧式类
在Python 2及以前的版本中,由任意内置类型派生出的类(只要一个内置类型位于类树的某个位置),都属于“新式类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类,则称之为“经典类”。
class A:
pass
class B(object):
pass
Python 2.x中默认都是经典类,只有显式继承了object才是新式类
Python 3.x中默认都是新式类,不必显式的继承object
“新式类”和“经典类”的区分在Python 3之后就已经不存在,在Python 3.x之后的版本,因为所有的类都派生自内置类型object(即使没有显示的继承object类型),即所有的类都是“新式类”。
继承顺序的区别
以钻石继承为例,经典类的钻石继承是深度优先,即从下往上搜索;新式类的继承顺序是采用C3算法(非广度优先)。
class ClassicClassA():
var = 'Classic Class A'
class ClassicClassB(ClassicClassA):
pass
class ClassicClassC():
var = 'Classic Class C'
class SubClassicClass(ClassicClassB, ClassicClassC):
pass
if __name__ == '__main__':
print(SubClassicClass.var)
>>> Classic Class A
在SubClassicClass对var属性进行搜索的过程中,根据从下到上的原则,会优先搜索ClassicClassB,而ClassicClassB没有var属性,会继续往上搜索ClassicClassB的超类ClassicClassA(深度优先),在ClassicClassA中发现var属性后停止搜索,var的值为ClassicClassA中var的值;而ClassicClassC的var属性从始至终都未被搜索到。
从运行结果可以看出,输出的是Classic Class A,可见类继承的搜索是深度优先,由下至上进行搜索。
新式类的继承顺序并非是广度优先,而是C3算法,只是在部分情况下,C3算法的结果恰巧与广度优先的结果相同。
对新式类的继承搜索顺序进行代码验证,新式类中,可以使用mro函数来查看类的搜索顺序(这也算是一个区别),如SubNewStyleClass.mro()。
统一了python中的类型机制,保持class与type的统一
对新式类的实例执行a.__class__与type(a)的结果是一致的,对于旧式类来说就不一样了。
经典类的实例是instance类型,而内置类的实例却不是,无法统一
class A():pass
class B():pass
a = A()
b = B()
if __name__ == '__main__':
print(type(a))
print(type(b))
print(type(a) == type(b))
print(a.__class__)
print(b.__class__)
print(a.__class__ == b.__class__)
Python 2.6.9 及 2.7.10 的运行结果:
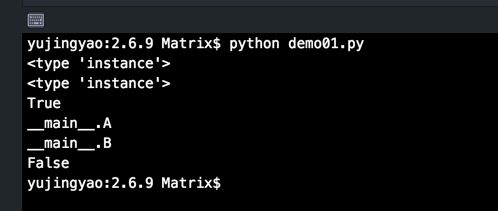
在Python 2.x及以前的版本,所有经典类的实例都是“instance”(实例类型)。所以比较经典类实例的类型(type)毫无意义,因为所有的经典类实例都是instance类型,比较的结果通常为True。更多情况下需要比较经典类实例的__class__属性来获得我们想要的结果(或使用isinstance函数)。
Python 3.5.1 运行结果
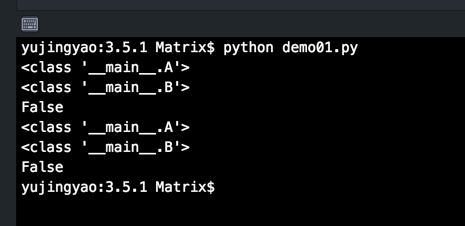
在Python 3.x及之后的版本,类和类型已经合并。类实例的类型是这个实例所创建自的类(通常是和类实例的__class__相同),而不再是Python 2.x版本中的“instance”实例类型。
需要注意的是,在Python 2.x版本中,“经典类的实例都是instance类型”,这个结论只适用于经典类。对新式类和内置类型的实例,它们的类型要更加明确。
所有的类型都是type类。从另一个角度理解,类就是type类的实例,所有的新式类,都是由type类实例化创建而来,并且显式或隐式继承自object。
在Python 3.x 中,所有的类都显式或隐式的派生自object类,type类也不例外。类型自身派生自object类,而object类派生自type,二者组成了一个循环的关系。
type与object
引言
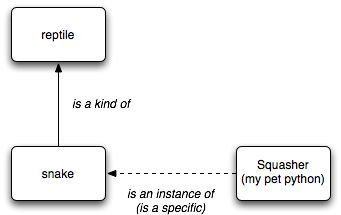
父子关系,即继承关系,表现为子类继承于父类,如『蛇』类继承自『爬行动物』类,我们说『蛇是一种爬行动物』,英文说『snake is a kind of reptile』。在python里要查看一个类型的父类,使用它的__bases__属性可以查看。
类型实例关系,表现为某个类型的实例化,例如『萌萌是一条蛇』,英文说『萌萌 is an instance of snake』。在python里要查看一个实例的类型,使用它的__class__属性可以查看,或者使用type()函数查看。
这两种关系使用下面这张图简单示意,继承关系使用实线从子到父连接,类型实例关系使用虚线从实例到类型连接:
我们将使用一块白板来描述一下Python里面对象的关系,白板划分成三列:

先来看看type和object
>>> object
>>> type
它们都是type的一个实例,表示它们都是类型对象。
在Python的世界中,object是父子关系的顶端,所有的数据类型的父类都是它;
type是类型实例关系的顶端,所有对象都是它的实例的。它们两个的关系可以这样描述:
- object是一个type,object is and instance of type。即Object是type的一个实例。
>>> object.__class__
>>> object.__bases__ # object 无父类,因为它是链条顶端。
()
- type是一种object, type is kind of object。即Type是object的子类。
>>> type.__bases__(,)
>>> type.__class__ # type的类型是自己
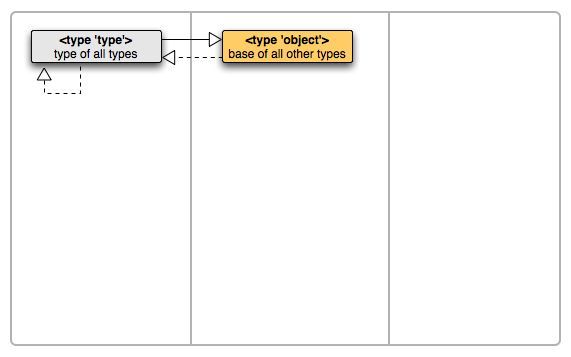
我们再引入list, dict, tuple 这些内置数据类型来看看
>>> list.__bases__(,)
>>> list.__class__
>>> dict.__bases__(,)
>>> dict.__class__
>>> tuple.__class__
>>> tuple.__bases__(,)
它们的父类都是object,类型都是type。
再实例化一个list看看
>>> mylist = [1,2,3]
>>> mylist.__class__
>>> mylist.__bases__
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'list' object has no attribute '__bases__'
实例化的list的类型是

白板上的虚线表示源是目标的实例,实线表示源是目标的子类。即,左边的是右边的类型,而上面的是下面的父亲。
虚线是跨列产生关系,而实线只能在一列内产生关系。除了type和object两者外。
当我们自己去定个一个类及实例化它的时候,和上面的对象们又是什么关系呢?试一下
>>> class C(object):
... pass
...
>>> C.__class__
>>> C.__bases__(,)
# 实例化
>>> c = C()
>>> c.__class__
>>> c.__bases__
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'C' object has no attribute '__bases__'
这个实例化的C类对象也是没有父类的属性的。
再更新一下白板:
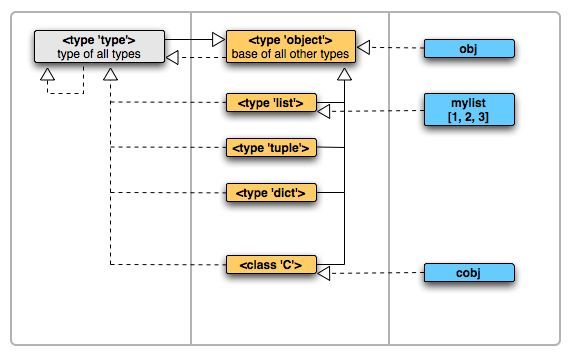
第一列,元类列,type是所有元类的父亲。我们可以通过继承type来创建元类。
第二列,TypeObject列,也称类列,object是所有类的父亲,大部份我们直接使用的数据类型都存在这个列的。
第三列,实例列,实例是对象关系链的末端,不能再被子类化和实例化。
object是父子关系的顶端,所有的数据类型的父类都是它;
type是类型实例关系的顶端,所有对象都是它的实例的
即object是type的一个实例。
type是object的子类。
全局解释器锁
全局解释器锁 GIL(Global Interpreter Lock)
简介
- 设置GIL
- 切换到一个线程去运行
- 运行:
a. 指定数量的字节码指令,或者
b. 线程主动让出控制(I/O或者可以调用time.sleep(0)) - 把线程设置为睡眠状态
- 解锁GIL
- 再次重复以上所有步骤
引言
GIL是什么
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
那么CPython实现中的GIL又是什么呢?GIL全称Global Interpreter Lock为了避免误导,我们还是来看一下官方给出的解释:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
好吧,是不是看上去很糟糕?一个防止多线程并发执行机器码的一个Mutex,乍一看就是个BUG般存在的全局锁嘛!别急,我们下面慢慢的分析
为什么会有GIL
由于物理上得限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,就出现了多线程的编程方式,而随之带来的就是线程间数据一致性和状态同步的困难。即使在CPU内部的Cache也不例外,为了有效解决多份缓存之间的数据同步时各厂商花费了不少心思,也不可避免的带来了一定的性能损失。
Python当然也逃不开,为了利用多核,Python开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。
慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
所以简单的说GIL的存在更多的是历史原因。如果推到重来,多线程的问题依然还是要面对,但是至少会比目前GIL这种方式会更优雅。
GIL的影响
从上文的介绍和官方的定义来看,GIL无疑就是一把全局排他锁。毫无疑问全局锁的存在会对多线程的效率有不小影响。甚至就几乎等于Python是个单线程的程序。 那么读者就会说了,全局锁只要释放的勤快效率也不会差啊。只要在进行耗时的IO操作的时候,能释放GIL,这样也还是可以提升运行效率的嘛。或者说再差也不会比单线程的效率差吧。理论上是这样,而实际上呢?Python比你想的更糟。
下面我们就对比下Python在多线程和单线程下得效率对比。测试方法很简单,一个循环1亿次的计数器函数。一个通过单线程执行两次,一个多线程执行。最后比较执行总时间。测试环境为双核的Mac pro。注:为了减少线程库本身性能损耗对测试结果带来的影响,这里单线程的代码同样使用了线程。只是顺序的执行两次,模拟单线程。
顺序执行的单线程(single_thread.py)
#! /usr/bin/python
from threading import Thread
import time
def my_counter():
i = 0
for _ in range(100000000):
i = i + 1
return True
def main():
thread_array = {}
start_time = time.time()
for tid in range(2):
t = Thread(target=my_counter)
t.start()
t.join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
同时执行的两个并发线程(multi_thread.py)
#! /usr/bin/python
from threading import Thread
import time
def my_counter():
i = 0
for _ in range(100000000):
i = i + 1
return True
def main():
thread_array = {}
start_time = time.time()
for tid in range(2):
t = Thread(target=my_counter)
t.start()
thread_array[tid] = t
for i in range(2):
thread_array[i].join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
下图就是测试结果
可以看到python在多线程的情况下居然比单线程整整慢了45%。按照之前的分析,即使是有GIL全局锁的存在,串行化的多线程也应该和单线程有一样的效率才对。那么怎么会有这么糟糕的结果呢?
让我们通过GIL的实现原理来分析这其中的原因。
当前GIL设计的缺陷
基于pcode数量的调度方式
按照Python社区的想法,操作系统本身的线程调度已经非常成熟稳定了,没有必要自己搞一套。所以Python的线程就是C语言的一个pthread,并通过操作系统调度算法进行调度(例如linux是CFS)。为了让各个线程能够平均利用CPU时间,python会计算当前已执行的微代码数量,达到一定阈值后就强制释放GIL。而这时也会触发一次操作系统的线程调度(当然是否真正进行上下文切换由操作系统自主决定)。
伪代码
while True:
acquire GIL
for i in 1000:
do something
release GIL
/* Give Operating System a chance to do thread scheduling */
这种模式在只有一个CPU核心的情况下毫无问题。任何一个线程被唤起时都能成功获得到GIL(因为只有释放了GIL才会引发线程调度)。但当CPU有多个核心的时候,问题就来了。从伪代码可以看到,从release GIL到acquire GIL之间几乎是没有间隙的。所以当其他在其他核心上的线程被唤醒时,大部分情况下主线程已经又再一次获取到GIL了。这个时候被唤醒执行的线程只能白白的浪费CPU时间,看着另一个线程拿着GIL欢快的执行着。然后达到切换时间后进入待调度状态,再被唤醒,再等待,以此往复恶性循环。
PS:当然这种实现方式是原始而丑陋的,Python的每个版本中也在逐渐改进GIL和线程调度之间的互动关系。例如先尝试持有GIL在做线程上下文切换,在IO等待时释放GIL等尝试。但是无法改变的是GIL的存在使得操作系统线程调度的这个本来就昂贵的操作变得更奢侈了。 关于GIL影响的扩展阅读
为了直观的理解GIL对于多线程带来的性能影响,这里直接借用的一张测试结果图(见下图)。图中表示的是两个线程在双核CPU上得执行情况。两个线程均为CPU密集型运算线程。绿色部分表示该线程在运行,且在执行有用的计算,红色部分为线程被调度唤醒,但是无法获取GIL导致无法进行有效运算等待的时间。
由图可见,GIL的存在导致多线程无法很好的立即多核CPU的并发处理能力。
那么Python的IO密集型线程能否从多线程中受益呢?我们来看下面这张测试结果。颜色代表的含义和上图一致。白色部分表示IO线程处于等待。可见,当IO线程收到数据包引起终端切换后,仍然由于一个CPU密集型线程的存在,导致无法获取GIL锁,从而进行无尽的循环等待。
简单的总结下就是:Python的多线程在多核CPU上,只对于IO密集型计算产生正面效果;而当有至少有一个CPU密集型线程存在,那么多线程效率会由于GIL而大幅下降。
如何避免受到GIL的影响
说了那么多,如果不说解决方案就仅仅是个科普帖,然并卵。GIL这么烂,有没有办法绕过呢?我们来看看有哪些现成的方案。
用multiprocessing替代Thread
multiprocessing库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。它完整的复制了一套thread所提供的接口方便迁移。唯一的不同就是它使用了多进程而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。
当然multiprocessing也不是万能良药。它的引入会增加程序实现时线程间数据通讯和同步的困难。就拿计数器来举例子,如果我们要多个线程累加同一个变量,对于thread来说,申明一个global变量,用thread.Lock的context包裹住三行就搞定了。而multiprocessing由于进程之间无法看到对方的数据,只能通过在主线程申明一个Queue,put再get或者用share memory的方法。 这个额外的实现成本使得本来就非常痛苦的多线程程序编码,变得更加痛苦了。具体难点在哪有兴趣的读者可以扩展阅读这篇文章
用其他解析器
之前也提到了既然GIL只是CPython的产物,那么其他解析器是不是更好呢?没错,像JPython和IronPython这样的解析器由于实现语言的特性,他们不需要GIL的帮助。然而由于用了Java/C#用于解析器实现,他们也失去了利用社区众多C语言模块有用特性的机会。所以这些解析器也因此一直都比较小众。毕竟功能和性能大家在初期都会选择前者,Done is better than perfect。
所以没救了么?
当然Python社区也在非常努力的不断改进GIL,甚至是尝试去除GIL。并在各个小版本中有了不少的进步。有兴趣的读者可以扩展阅读这个Slide 另一个改进Reworking the GIL
- 将切换颗粒度从基于opcode计数改成基于时间片计数
- 避免最近一次释放GIL锁的线程再次被立即调度
- 新增线程优先级功能(高优先级线程可以迫使其他线程释放所持有的GIL锁)
Python的编码
在Python2.x中,有两种字符串类型:str和unicode类型。str存bytes数据,unicode类型存unicode数据
在Python3.x中,也只有两种字符串类型:str和bytes类型。str类型存unicode数据,bytse类型存bytes数据,
python2的encode和decode
我们把从Unicode到字节码(byte string)称之为encode
encode : Unicode -> byte string
把从字节码(byte string)到Unicode码称之为decode
decode: byte string-> Unicode
unicode是离用户更近的数据,bytes是离计算机更近的数据。
with
上下文
处理程序代码的前后语境
简而言之,有一个特殊的语句块,在执行这个语句块之前需要先执行一些准备动作;当语句块执行完成后,需要继续执行一些收尾动作。
用法
上下文管理常用于读写文件及短暂的操作数据库中
with open(r'somefileName') as somefile:
for line in somefile:
print line
# ...more code
这里使用了 with 语句,不管在处理文件过程中是否发生异常,都能保证 with 语句执行完毕后已经关闭了打开的文件句柄。如果使用传统的 try/finally 范式
实现
通过实现两个魔法方法 __enter__和__exit__ 来实现,just show the code
class Contextor:
def __enter__(self):
pass
def __exit__(self, exc_type, exc_val, exc_tb):
"""
exc_type : 错误类型
exc_val : 错误值
exc_tb : Traceback
"""
pass
contextor = Contextor()
with contextor [as var]:
with_body
lambda
lambda x,y : x + y
# lambda 表达式当然也是对象
t = lambda x,y : x + y
print t # at 0x7f7c3d02a668>
t(1,2) # 3
常用与被Python 其他高级函数调用,map(),filter() etc...
高阶函数
map()函数
python内置的一个高阶函数,它接收一个函数f和一个list,并且把list的元素以此传递给函数f,然后返回一个函数f处理完所有list元素的列表,如下:
map(lambda x:x**2,[1,2,3,4,5])
# [1, 4, 9, 16, 25]
reduce()函数
reduce()函数也是python的内置高阶函数,reduce()函数接收的的参数和map()类似,一个函数f,一个list,但行为和map()不同,reduce()传入的参数f必须接受2个参数,reduce() 函数还接收第三个参数,作为返回结果的初始值,
第一次调用是把list的前两个元素传递给f,第二次调用时,就是把前两个list元素的计算结果当成第一个参数,list的第三个元素当成第二个参数,传入f进行操作,以此类推,并最终返回结果;
reduce(lambda x,y:x+y,[1,2,3,4,5],10)
# 25
filter()函数
filter()函数接收一个函数f和一个list,这个函数f的作用是对每个元素进行判断,返回true或false,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件的元素组成的list;例
filter(lambda x:x%2==1,[1,2,3,4,5]) # 留下列表里的所有奇数
# [1, 3, 5]
zip()函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
# 遍历两个list
for i,j in zip([1,2,3],['x','y','z']):
print i,j
# 1 x
# 2 y
# 3 z
# 将两个list合成一个dict
t = dict(zip([1,2,3],['x','y','z']))
{1: 'x', 2: 'y', 3: 'z'}
sort()函数
排序函数,
基本形式 sorted(iterable[, cmp[, key[, reverse]]])
sorted([1,2,-3,-4,5]) # 默认升序
# [-4, -3, 1, 2, 5]
sorted([1,2,-3,-4,5],key=abs) # 返回一个以数值的绝对值为排序关键词的升序列表
# [1, 2, -3, -4, 5]
sorted([1,2,-3,-4,5],reverse=True) # 降序
# [5, 2, 1, -3, -4]
# 对字符串和其他复杂数据结构的排序
sorted(['bob', 'about', 'Zoo', 'Credit'] # 对字符串以asc ii 码为关键词排序
# ['Credit', 'Zoo', 'about', 'bob']
sorted(['bob', 'about', 'Zoo', 'Credit',key = str.lower] # 忽略大小写以字母顺序为关键词排序
# 'about', 'bob', 'Credit', 'Zoo'
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)] # 以每个排序对象的第二个元素为关键词,降序排列
sorted(L,key = lambda x:x[1],reverse=True)
# [('Adam', 92), ('Lisa', 88), ('Bob', 75), ('Bart', 66)]
yield
带有 yield 的函数在 Python 中被称之为 generator(生成器),是一个可以迭代的对象。
# 这是一个产生斐波那契数列的迭代器
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b
# print b
a, b = b, a + b
n = n + 1
>>> for n in fab(5):
... print n
...
1
1
2
3
5
简单地讲,yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,调用 fab(5) 不会执行 fab 函数,而是返回一个 iterable 对象!在 for 循环执行时,每次循环都会执行 fab 函数内部的代码,执行到 yield b 时,fab 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。
这里的概念就是协程。有关协程
python中 greenlet 和 gevent 也可以很好的协程,这里就不展开了
也可以手动调用 fab(5) 的 next() 方法(因为 fab(5) 是一个 generator 对象,该对象具有 next() 方法),这样我们就可以更清楚地看到 fab 的执行流程
装饰器
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。
于是,你就可以在编写一个控制程序,接收某个特定函数作为参数输入,并在这个特定函数运行的前后在做一些你想做的事情,这就是装饰器。
def log(func):
def wrapper(*args, **kw):
print 'call %s():' % func.__name__
result = func(*args, **kw)
print 'done'
return result
return wrapper
@log
def hello():
print 'hello, world'
hello()
# call hello():
# hello, world
# done
以上的代码非常清楚的展示了装饰器的作用,值得一提的是 *args, **kw 这是python的可变参数的接收方式,
这里一定要将接收到的参数传递给装饰器所装饰的函数,即func(*args, **kw)
类装饰器
还记得元类吗?
元类的主要目的就是为了当创建类时能够自动地改变类
当然,不光是元类能完成这个功能,类装饰器也可以。
装饰器不光能接收函数作为输入,类也是一样
以下是用类实现一个单例模式的方法
def singleton(cls, *args, **kw):
instances = {}
def _singleton():
if cls not in instances:
instances[cls] = cls(*args, **kw) # 以类名作为实例化的标准,每个类名只能被实例化一次
return instances[cls]
return _singleton
@singleton
class MyClass(object):
def __init__(self, x=0):
self.x = x
装饰器与AOP(面向切面编程)
装饰器是一个很著名的设计模式,经常被用于有切面需求的场景,较为经典的有插入日志、性能测试、事务处理等。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量函数中与函数功能本身无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能
AOP就是写代码的时候 把各个模块中需要重复写的抽取出来,弄成一个切面。例如日志,权限。
切面的具体表现就是实现公共方法的类

property
property 可以视作python的一个专门针对类属性的装饰器
在绑定属性时,如果我们直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以把成绩随便改:
s = Student()
s.score = 9999
这显然不合逻辑。为了限制score的范围,可以通过一个set_score()方法来设置成绩,再通过一个get_score()来获取成绩,这样,在set_score()方法里,就可以检查参数:
class Student(object):
def get_score(self):
return self._score
def set_score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
现在,对任意的Student实例进行操作,就不能随心所欲地设置score了:
>>> s = Student()
>>> s.set_score(60) # ok!
>>> s.get_score()
60
>>> s.set_score(9999)
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
但是,上面的调用方法又略显复杂,没有直接用属性这么直接简单。
有没有既能检查参数,又可以用类似属性这样简单的方式来访问类的变量呢?对于追求完美的Python程序员来说,这是必须要做到的!
还记得装饰器(decorator)可以给函数动态加上功能吗?对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法变成属性调用的:
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
@property的实现比较复杂,我们先考察如何使用。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
>>> s = Student()
>>> s.score = 60 # OK,实际转化为s.set_score(60)
>>> s.score # OK,实际转化为s.get_score()
60
>>> s.score = 9999
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
注意到这个神奇的@property,我们在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过getter和setter方法来实现的。
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性:
class Student(object):
@property
def birth(self):
return self._birth
@birth.setter
def birth(self, value):
self._birth = value
@property
def age(self):
return 2014 - self._birth
上面的birth是可读写属性,而age就是一个只读属性,因为age可以根据birth和当前时间计算出来。
property小结
@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
函数参数传递
- 位置传递实例:
def fun(a,b,c)
return a+b+c
print(f(1,2,3))
- 关键字传递
关键字(keyword)传递是根据每个参数的名字传递参数。关键字并不用遵守位置的对应关系。
def fun(a,b,c)
return a+b+c
print(f(1,c=3,b=2))
- 参数默认值
在定义函数的时候,使用形如c=10的方式,可以给参数赋予默认值(default)。如果该参数最终没有被传递值,将使用该默认值。
def f(a,b,c=10):
return a+b+c
print(f(3,2))
print(f(3,2,1))
在第一次调用函数f时, 我们并没有足够的值,c没有被赋值,c将使用默认值10.第二次调用函数的时候,c被赋值为1,不再使用默认值。
- 包裹传递
在定义函数时,我们有时候并不知道调用的时候会传递多少个参数。这时候,包裹(packing)位置参数,或者包裹关键字参数,来进行参数传递,会非常有用。
下面是包裹位置传递的例子:
def func(*name):
print type(name)
print name
func(1,4,6)
#
# (1, 4, 6)
func(5,6,7,1,2,3)
#
# (5, 6, 7, 1, 2, 3)
两次调用,尽管参数个数不同,都基于同一个func定义。在func的参数表中,所有的参数被name收集,根据位置合并成一个元组(tuple),这就是包裹位置传递。
为了提醒Python参数,name是包裹位置传递所用的元组名,在定义func时,在name前加*号。
下面是包裹关键字传递的第二个例子:
def func(**dict):
print type(dict)
print dict
func((1,9))
func("a":2,"b":1,"c":11)
与上面一个例子类似,dict是一个字典,收集所有的关键字,传递给函数func。为了提醒Python,参数dict是包裹关键字传递所用的字典,在dict前加**。
包裹传递的关键在于定义函数时,在相应元组或字典前加*或**。
- 解包裹
*和**,也可以在调用的时候使用,即解包裹(unpacking), 下面为例:
def func(a,b,c):
print a,b,c
args = (1,3,4)
func(*args)
dict = {'a':1,'b':2,'c':3}
func(**dict)
在这个例子中,所谓的解包裹,就是在传递tuple时,让tuple的每一个元素对应一个位置参数。在调用func时使用*,是为了提醒Python:我想要把args拆成分散的三个元素,分别传递给a,b,c。(设想一下在调用func时,args前面没有*会是什么后果?)
相应的,也存在对词典的解包裹,使用相同的func定义,然后:在传递词典dict时,让词典的每个键值对作为一个关键字传递给func。
参数默认值的继承性
def extendList(val, list=[]):
list.append(val)
return list
list1 = extendList(10)
list2 = extendList(123,[])
list3 = extendList('a')
print "list1 = %s" % list1
print "list2 = %s" % list2
print "list3 = %s" % list3
结果为:
list1 = [10, 'a']
list2 = [123]
list3 = [10, 'a']
很多人都会误认为list1=[10],list3=[‘a’],因为他们以为每次extendList被调用时,列表参数的默认值都将被设置为[].但实际上的情况是,新的默认列表只在函数被定义的那一刻创建一次。
当extendList被没有指定特定参数list调用时,这组list的值随后将被使用。这是因为带有默认参数的表达式在函数被定义的时候被计算,不是在调用的时候被计算。因此list1和list3是在同一个默认列表上进行操作(计算)的。而list2是在一个分离的列表上进行操作(计算)的。(通过传递一个自有的空列表作为列表参数的数值)
闭包与延迟锁定


Pythonic
交换变量
a,b = b,a
翻转
a = 'hello, world!'
a[::-1] # !dlrow ,olleh
拼接字符串
a = ['hello', 'world']
" ".join(a) # hello world
列表去重
a = [1, 1, 1, 2, 3 ,4 ,4, 5]
a = list(set(a)) # [1, 2, 3, 4, 5]
复制列表
import copy
a = [1,'a',['x']]
# 浅复制
b = copy.copy(a)
b = a[:]
b = list(a) # 使用工厂函数
# 深复制
b = copy.deepcopy(a)
列表推导
ood_list = [i for i in xrange(1,101) if i % 2 == 1]
当你把推导式的 [] 替换为 () 时,就变为了一个生成器,即一个可迭代的对象。而且这样做可以解决列表推导与lambda结合时产生的延迟锁定问题。
字典推导式
# 快速更换k,v
mcase = {'a': 10, 'b': 34}
mcase_frequency = {v: k for k, v in mcase.items()}
读写文件
with open('/path/to/file', 'r') as f:
do something...
Python的自省
自省就是面向对象的语言所写的程序在运行时,所能知道对象的类型.简单一句就是运行时能够获得对象的类型.比如type(),dir(),getattr(),hasattr(),isinstance().
Timsort
Timsort是python list 和sorted() 内部所使用的排序类型,具有非常好的性能
Timsort是结合了合并排序(merge sort)和插入排序(insertion sort)而得出的排序算法,它在现实中有很好的效率。Tim Peters在2002年设计了该算法并在Python中使用(TimSort 是 Python 中 list.sort 的默认实现)。该算法找到数据中已经排好序的块-分区,每一个分区叫一个run,然后按规则合并这些run。Pyhton自从2.3版以来一直采用Timsort算法排序,现在Java SE7和Android也采用Timsort算法对数组排序。
Timsort的核心过程
TimSort 算法为了减少对升序部分的回溯和对降序部分的性能倒退,将输入按其升序和降序特点进行了分区。排序的输入的单位不是一个个单独的数字,而是一个个的块-分区。其中每一个分区叫一个run。针对这些 run 序列,每次拿一个 run 出来按规则进行合并。每次合并会将两个 run合并成一个 run。合并的结果保存到栈中。合并直到消耗掉所有的 run,这时将栈上剩余的 run合并到只剩一个 run 为止。这时这个仅剩的 run 便是排好序的结果。
综上述过程,Timsort算法的过程包括
- 如何数组长度小于某个值,直接用二分插入排序算法
- 找到各个run,并入栈
- 按规则合并run
1 操作
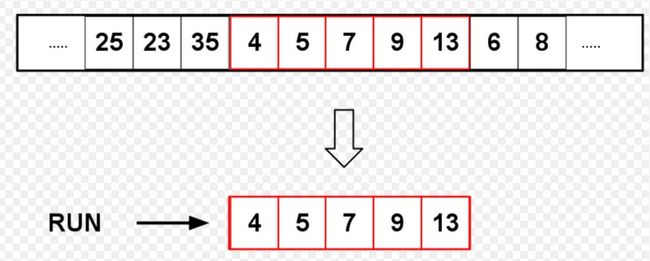
现实中的大多数据通常是有部分已经排好序的,Timsort利用了这一特点。Timsort排序的输入的单位不是一个个单独的数字,而是一个个的分区。其中每一个分区叫一个“run“(图1)。针对这个 run 序列,每次拿一个 run 出来进行归并。每次归并会将两个 run 合并成一个 run。每个run最少要有2个元素。Timesor按照升序和降序划分出各个run:run如果是是升序的,那么run中的后一元素要大于或等于前一元素(a[lo] <= a[lo + 1] <= a[lo + 2] <= ...);如果run是严格降序的,即run中的前一元素大于后一元素(a[lo] > a[lo + 1] > a[lo + 2] > ...),需要将run 中的元素翻转(这里注意降序的部分必须是“严格”降序才能进行翻转。因为TimSort 的一个重要目标是保持稳定性stability。如果在 >= 的情况下进行翻转这个算法就不再是 stable)。
1.1 run的最小长度
run是已经排好序的一块分区。run可能会有不同的长度,Timesort根据run的长度来选择排序的策略。例如如果run的长度小于某一个值,则会选择插入排序算法来排序。run的最小长度(minrun)取决于数组的大小。当数组元素少于64个时,那么run的最小长度便是数组的长度,这是Timsort用插入排序算法来排序。当数组元素大于等于63时,对于较大的数组,从32到65范围内选择一个称为min run的数字,使得数组的大小除以minrun的大小等于或略小于2的幂。最后的算法只需要数组大小的六个最重要的位,如果其余位被设置,则添加一个,并将该结果用作minrun。 此算法适用于所有情况,包括数组大小小于64的情况。
1.2 优化run的长度
优化run的长度是指当run的长度小于minrun时,为了使这样的run的长度达到minrun的长度,会从数组中选择合适的元素插入run中。这样做使大部分的run的长度达到均衡,有助于后面run的合并操作。
1.3 合并run
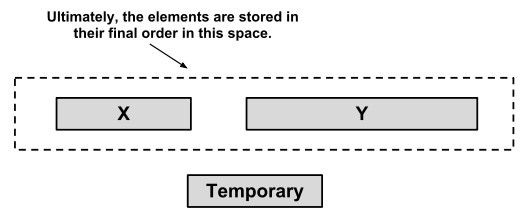
划分run和优化run长度以后,然后就是对各个run进行合并。合并run的原则是 run合并的技术要保证有最高的效率。当Timsort算法找到一个run时,会将该run在数组中的起始位置和run的长度放入栈中,然后根据先前放入栈中的run决定是否该合并run。Timsort不会合并在栈中不连续的run(Timsort does not merge non-consecutive runs because doing this would cause the element common to all three runs to become out of order with respect to the middle run.)
Timsort会合并在栈中2个连续的run。X、Y、Z代表栈最上方的3个run的长度(图2),当同时不满足下面2个条件是,X、Y这两个run会被合并,直到同时满足下面2个条件,则合并结束:
- X>Y+Z
- Y>Z
例如:如果X 合并2个相邻的run需要临时存储空闲,临时存储空间的大小是2个run中较小的run的大小。Timsort算法先将较小的run复制到这个临时存储空间,然后用原先存储这2个run的空间来存储合并后的run(图3)。 简单的合并算法是用简单插入算法,依次从左到右或从右到左比较,然后合并2个run。为了提高效率,Timsort用 二分插入算法 (binary merge sort) 先用二分查找算法/折半查找算法(binary search)找到插入的位置,然后在插入。 例如,我们要将A和B这2个run 合并,且A是较小的run。因为A和B已经分别是排好序的,二分查找会找到B的第一个元素在A中何处插入(图4)。同样,A的最后一个元素找到在B的何处插入,找到以后,B在这个元素之后的元素就不需要比较了(图5)。 这种查找可能在随机数中效率不会很高,但是在其他情况下有很高的效率。 1.5 Galloping 模型 根据信息学理论,在平均情况下,比较排序不会比O(n log n)更快。由于Timsort算法利用了现实中大多数数据中会有一些排好序的区,所以Timsort会比 空间复杂度(space complexities)比较 说明: JSE 7对对象进行排序,没有采用快速排序,是因为快速排序是不稳定的,而Timsort是稳定的。 A stable, adaptive, iterative mergesort that requires far fewer than n lg(n) comparisons when running on partially sorted arrays, while offering performance comparable to a traditional mergesort when run on random arrays. Like all proper mergesorts, this sort is stable and runs O(n log n) time (worst case). In the worst case, this sort requires temporary storage space for n/2 object references; in the best case, it requires only a small constant amount of space. 大体是说,Timsort是稳定的算法,当待排序的数组中已经有排序好的数,它的时间复杂度会小于n logn。与其他合并排序一样,Timesrot是稳定的排序算法,最坏时间复杂度是O(n log n)。在最坏情况下,Timsort算法需要的临时空间是n/2,在最好情况下,它只需要一个很小的临时存储空间
1.4 合并run步骤


介绍的是类似上述run的合并过程,参见维基百科 Galloping Model性能
O(n log n)快些。对于随机数没有可以利用的排好序的区,Timsort时间复杂度会是log(n!)。下表是Timsort与其他比较排序算法时间复杂度(time complexity)的比较。

下面是JSE7 中Timsort实现代码中的一段话,可以很好的说明Timsort的优势:
练习
8个面试题
单例模式的几种实现
InterviewKeyOfPython