作为一名应用系统开发人员,为什么要关注数据内部的存储和检索呢?首先,你不太可能从头开始实现一套自己的存储引擎,往往需要从众多现有的存储引擎中选择一个适合自己应用的存储引擎。因此,为了针对你特定的工作负载而对数据库调优时,最好对存储引擎的底层机制有一个大概的了解。
今天我们就先来了解下关系型数据库MySQL和NoSQL存储引擎HBase的底层存储机制。对于一个数据库的性能来说,其数据的组织方式至关重要。众所周知,数据库的数据大多存储在磁盘上,而磁盘的访问相对内存的访问来说是一项很耗时的操作,对比如下。因此,提高数据库数据的查找速度的关键点之一便是尽量减少磁盘的访问次数。

磁盘与内存的访问速度对比
为了加速数据库数据的访问,大多传统的关系型数据库都会使用特殊的数据结构来帮助查找数据,这种数据结构叫作索引( Index)。对于传统的关系型数据库,考虑到经常需要范围查找某一批数据,因此其索引一般不使用 Hash算法,而使用树( Tree)结构。然而,树结构的种类很多,却不一定都适合用于做数据库索引。
二叉查找树与平衡二叉树
最常见的树结构是二叉查找树( Binary Search Tree),它就是一棵二叉有序树:保证左子树上所有节点的值都小于根节点的值,而右子树上所有节点的值都大于根节点的值。其优点在于实现简单,并且树在平衡的状态下查找效率能达到 O(log n);缺点是在极端非平衡情况下查找效率会退化到 O(n),因此很难保证索引的效率。
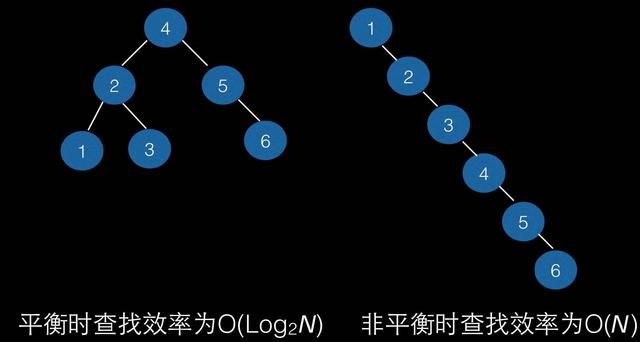
二叉查找树的查找效率
针对上述二叉查找树的缺点,人们很自然就想到是否能用平衡二叉树( Balanced Binary Tree)来解决这个问题。但是平衡二叉树依然有个比较大的问题:它的树高为 log n——对于索引树来说,树的高度越高,意味着查找所要花费的访问次数越多,查询效率越低。
况且,主存从磁盘读数据一般以页为单位,因此每次访问磁盘都会读取多个扇区的数据(比如 4KB大小的数据),远大于单个二叉树节点的值(字节级别),这也是造成二叉树相对索引树效率低下的原因。正因如此,人们就想到了通过增加每个树节点的度来提高访问效率,而 B+树(B+-tree)便受到了更多的关注。
B+树
在传统的关系型数据库里, B+树( B+-tree)及其衍生树是被用得比较多的索引树。

B+树
B+树的主要特点如下。
每个树节点只存放键值,不存放数值,而由叶子节点存放数值。这样会使树节点的度比较大,而树的高度就比较低,从而有利于提高查询效率。
叶子节点存放数值,并按照值大小顺序排序,且带指向相邻节点的指针,以便高效地进行区间数据查询;并且所有叶子节点与根节点的距离相同,因此任何查询的效率都很相似。
与二叉树不同, B+树的数据更新操作不从根节点开始,而从叶子节点开始,并且在更新过程中树能以比较小的代价实现自平衡。
正是由于 B+树的上述优点,它成了传统关系型数据库的宠儿。当然,它也并非无懈可击,它的主要缺点在于随着数据插入的不断发生,叶子节点会慢慢分裂——这可能会导致逻辑上原本连续的数据实际上存放在不同的物理磁盘块位置上,在做范围查询的时候会导致较高的磁盘 IO,以致严重影响到性能。
日志结构合并树
众所周知,数据库的数据大多存储在磁盘上,而无论是传统的机械硬盘( HardDiskDrive, HDD)还是固态硬盘( Solid State Drive, SSD),对磁盘数据的顺序读写速度都远高于随机读写。

磁盘顺序与随机访问吞吐对比
然而,基于 B+树的索引结构是违背上述磁盘基本特点的——它会需要较多的磁盘随机读写,于是, 1992年,名为日志结构( Log-Structured)的新型索引结构方法便应运而生。日志结构方法的主要思想是将磁盘看作一个大的日志,每次都将新的数据及其索引结构添加到日志的最末端,以实现对磁盘的顺序操作,从而提高索引性能。不过,日志结构方法也有明显的缺点,随机读取数据时效率很低。
1996年,一篇名为 Thelog-structured merge-tree(LSM-tree)的论文创造性地提出了日志结构合并树( Log-Structured Merge-Tree)的概念,该方法既吸收了日志结构方法的优点,又通过将数据文件预排序克服了日志结构方法随机读性能较差的问题。尽管当时 LSM-tree新颖且优势鲜明,但它真正声名鹊起却是在 10年之后的 2006年,那年谷歌的一篇使用了 LSM-tree技术的论文 Bigtable: A Distributed Storage System for Structured Data横空出世,在分布式数据处理领域掀起了一阵旋风,随后两个声名赫赫的大数据开源组件( 2007年的 HBase与 2008年的 Cassandra,目前两者同为 Apache顶级项目)直接在其思想基础上破茧而出,彻底改变了大数据基础组件的格局,同时也极大地推广了 LSM-tree技术。
LSM-tree最大的特点是同时使用了两部分类树的数据结构来存储数据,并同时提供查询。其中一部分数据结构( C0树)存在于内存缓存(通常叫作 memtable)中,负责接受新的数据插入更新以及读请求,并直接在内存中对数据进行排序;另一部分数据结构( C1树)存在于硬盘上 (这部分通常叫作 sstable),它们是由存在于内存缓存中的 C0树冲写到磁盘而成的,主要负责提供读操作,特点是有序且不可被更改。

LSM-tree的 C0与 C1部分
LSM-tree的另一大特点是除了使用两部分类树的数据结构外,还会使用日志文件(通常叫作 commit log)来为数据恢复做保障。这三类数据结构的协作顺序一般是:所有的新插入与更新操作都首先被记录到 commit log中——该操作叫作 WAL(Write Ahead Log),然后再写到 memtable,最后当达到一定条件时数据会从 memtable冲写到 sstable,并抛弃相关的 log数据; memtable与 sstable可同时供查询;当 memtable出问题时,可从 commit log与 sstable中将 memtable的数据恢复。
我们可以参考 HBase的架构来体会其架构中基于 LSM-tree的部分特点。按照 WAL的原则,数据首先会写到 HBase的 HLog(相当于 commit log)里,然后再写到 MemStore(相当于 memtable)里,最后会冲写到磁盘 StoreFile(相当于 sstable)中。这样 HBase的 HRegionServer就通过 LSM-tree实现了数据文件的生成。HBase LSM-tree架构示意图如下图。

HBase LSM-tree架构示意图
LSM-tree的这种结构非常有利于数据的快速写入(理论上可以接近磁盘顺序写速度),但是不利于读——因为理论上读的时候可能需要同时从 memtable和所有硬盘上的 sstable中查询数据,这样显然会对性能造成较大的影响。为了解决这个问题, LSM-tree采取了以下主要的相关措施。
- 定期将硬盘上小的 sstable合并(通常叫作 Merge或 Compaction操作)成大的 sstable,以减少 sstable的数量。而且,平时的数据更新删除操作并不会更新原有的数据文件,只会将更新删除操作加到当前的数据文件末端,只有在 sstable合并的时候才会真正将重复的操作或更新去重、合并。
- 对每个 sstable使用布隆过滤器( Bloom Filter),以加速对数据在该 sstable的存在性进行判定,从而减少数据的总查询时间。
总结
LSM树和B+树的差异主要在于读性能和写性能进行权衡,在牺牲的同时寻找其余补救方案。
B+树存储引擎,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库。但随着写入操作增多,为了维护B+树结构,节点分裂,读磁盘的随机读写概率会变大,性能会逐渐减弱。LSM树(Log-Structured MergeTree)存储引擎和B+树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
订阅关注微信公众号《大数据技术进阶》,及时获取更多大数据架构和应用相关技术文章!
