优化页面访问速度(三)
——服务端优化
一、概述
服务端的优化,主要可以通过消息队列、减少数据库请求(缓存)、并发处理、页面静态化等方式处理。
二、消息队列
1、解决问题
消息队列(Message Queue,MQ)有许多不同的实现方式,可以用rabbitmq、activemq、rocketmq,也可以用任务分发系统gearman。
消息队列主要是解决消息的异步发送,即对于某个系统不需要关心的内容,只需要发布一个处理完毕的消息,带上一些参数,有需要的系统自行订阅。例如一些任务执行完成的回调函数,就可以用mq来实现异步回调。
2、处理方式
以rabbitmq为例。Rabbitmq的服务器,可以认为是消息的生产者和消费者的中转平台。生产者发布消息给rabbitmq服务器的交换机(exchange),发布的时候会定义一些路由规则(routing key)。Rabbitmq服务器根据路由规则,将消息从exchange转发到对应的队列(queue)中,再由消费者从queue中取消息,进行处理。如下图所示:
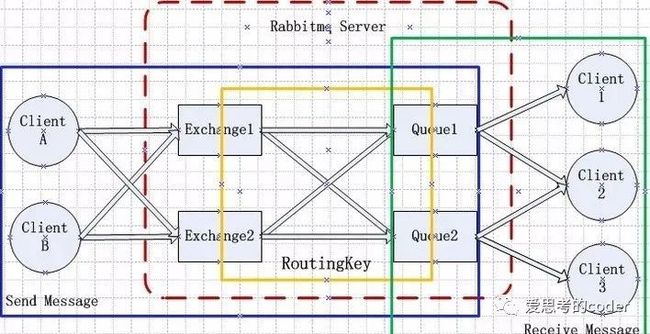
为了加快处理速度,防止队列的堆积,可以同时起多个消费者进程,用于消费队列的内容。
3、确保消费
Rabbitmq有重试机制,在没有发布成功时,会自动重试发送。当然,如果要确保消息被消费,可以设置类似TCP的三次握手方式,要求消费者完成消息的处理后,再发布一条消息,告知生产者。
生产者可以将发送的消息单独记录到数据库的一张表中,并且在接到消费者确认处理的消息后,把对应的数据置状态。
同时,可以编写一个crontab,定时来扫描这个表,将超过一定时间(如10分钟)未被置成功状态的记录,重新发布一次。
用单独的表来记录信息,好处在于,只要表中有数据,表明消息已经发布出去。这样当出现消息为被处理的问题的时候,易于确认是消息未发布还是消息接收处理存在问题。
当然,这要求消息接收方的处理方法是幂等的,即对同一条消息,无论接到多少次,只处理一次。
4、rabbitmq的routing key
Rabbitmq有好几种处理方式,如下:
1)广播
将消息发布到所有队列中,由消费者去接收感兴趣的消息,对于不感兴趣的消息直接丢弃。
2)direct
指定发送到某个队列中。
3)topic
采用正则的方式,将消息发布到某些队列中,例如a.*,发布到所有名为a.开头的队列。
三、缓存
1、解决问题
缓存的目的,主要在于减少对数据库的操作。数据库的请求,需要占用I/O资源,而缓存是存在内存中的,速度会快的多。
因此,对于频繁访问的数据,且实时性要求没那么高的,可以通过缓存来减少对数据库的压力。
另外,对于需要频繁修改数据的(如文章点击量)、短时间内大量访问的(秒杀系统),用缓存也是比较好的解决方案。
缓存常用的就是redis和memcache。
2、redis和memcache的区别
Memcache是纯粹的缓存,只有一种key-value形式的存储。
Redis功能更加强大,支持五种数据结构,包括string、list、hash、set、sorted-set,支持数据的持久化(AOF、快照),支持事务处理,支持哨兵监控,且可以临时突破内存限制(通过持久化的方式)。
3、key的设置方式
通常,用 方法名:id 的方式来作为key,这样比较方便来查找。
4、缓存会出现的问题
缓存会出现缓存穿透、缓存雪崩、缓存击穿。
1)缓存穿透
当大量查询不存在的key,由于正常情况下查询结果不存在的不会存到缓存中,这样会导致大量的查询绕过缓存直接查询数据库。
解决方案:对于数据库不存在的内容,也可以保存一小段时间随机的时间,如3分钟,这样可以避免绕过数据库的行为。
2)缓存雪崩
当所有的key都设置成同一个时间,会出现同一个时间所有key都过期,这样会发生一瞬间大量请求数据库的情况。
解决方案:对不同的key,设置一个随机的时间范围,比如4分58秒~5分3秒的过期时间,这样可以避免同一时间都过期。
3)缓存击穿
对于某个key,在一个很短的时间内并发大量访问,则所有的请求都绕过缓存去数据库取数据。
解决方案:可以设置互斥锁来解决问题。即请求缓存不存在的时候,先去访问互斥锁,redis的setnx、memcache的add 某个key。此时,请求数据库,并将请求结果存入缓存。
这样,下一个请求来的时候,由于存在互斥锁,key存在的时候无法添加,则表示数据被锁了,可以随机等待一个短暂的时间再请求锁,直到请求成功,再去访问一次缓存,通常此时缓存已经有内容了。如果还没有内容,可以再去请求数据库。
5、缓存过期策略——LRU
缓存内容太多,超过机器的内存时,需要一个策略剔除部分缓存内容,最常用的是LRU策略,即最近最少使用。
具体实现方式,是使用一个队列来维护缓存,当某个缓存被访问,则从队列底部去除,再添加到队列的头部,这样需要剔除的数据都是最久没有访问的数据。
存在问题:
当某个时间有大量的不同的key的访问,会把队列弄脏,造成需要的数据被剔除。
解决方案:
1)可以用两个队列,当数据访问一次放到第一个队列,再次访问挪到第二个队列去,然后LRU规则先清理第一个队列。
2)也可以用多个权重队列,把重要的内容、可能常访问的内容,都缓存到高级别的队列中去,把一些不怎么用的内容放到低级的队列中。
四、并发处理
PHP的并发处理,可以用swoole框架来解决,其可以控制并发消费内容。例如一个页面的展示,需要从几个不同的系统取数据,则可以异步取多个地方的数据,在最终汇总后一起处理。
Swoole框架我也不太熟,后面学习了再分享这部分内容。
五、页面静态化
Nginx没有处理PHP的能力,遇到PHP文件都要转发给php-fpm来处理,而遇到html、js、css等,可以直接处理返回给浏览器。
因此,在没有实现前后端完全分离的页面,可以使用静态化的方式,将不常变动的内容,在第一次访问php文件的时候,将其转存为html文件,并且设定一个过期时间。
后面访问的时候,根据Linux文件创建的时间,判断是否过期,当未到过期时间,可以由Nginx直接取对应的html文件进行返回。