一、异常概念
1、异常:有异于常态,和正常情况不一样,有错误出现,阻止当前方法或作用域。
2、异常处理:将出现的异常提示给编程人员与用户,使原本将要中断的程序继续运行或者退出。并且能够保存数据和释放资源。
二、异常体系结构
1、所有异常都继承于Throwable类,其下有两大子类:
(1)Error类:错误,一般编程人员不太接触,如虚拟机错误、线程死锁。硬伤:使程序崩溃
(2)Exception类:异常,编码、环境、用户输入等问题,其子类主要有:
- 非检查异常(运行时异常RuntimeException):【由java虚拟机自动捕获】如空指针NullPointer、越界ArrayIndexOutofBounds、错误类型转换ClassCast、算数异常Arithmetic等
- 检查异常CheckException:【需要手动添加捕获和处理语句】文件异常IO等

异常处理:
一、try-catch(多catch块)-finally
(1)try块:负责捕获异常,一旦try中发现异常,程序的控制权将被移交给catch块中的异常处理程序。【try语句块不可以独立存在,必须与 catch 或者 finally 块同存】
(2)catch块:如何处理?比如发出警告:提示、检查配置、网络连接,记录错误等。执行完catch块之后程序跳出catch块,继续执行后面的代码。
·编写catch块的注意事项:多个catch块处理的异常类,要按照先catch子类后catch父类的处理方式,因为会【就近处理】异常(由上自下)。
(3)finally:最终执行的代码,用于关闭和释放资源等
异常处理
try-catch以及try-catch-finally
try{
//一些会抛出的异常
}catch(Exception e){
//处理该异常的代码块
}finally{
//最终要执行的代码
}
终止执行,交由异常处理程序(抛出提醒或记录日志等),异常代码块外代码正常执行。
try会抛出很多种类型的异常,多个catch块捕获多钟错误。
多重异常处理代码块顺序问题:先子类再父类(顺序不对也会提醒错误),finally语句块处理最终将要执行的代码
return在try-catch-finally中:
1、不管有木有出现异常,finally块中代码都会执行;
2、当try和catch中有return时,finally仍然会执行;
3、finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,仍然是之前保存的值),所以函数返回值是在finally执行前确定的;
4、finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
1.e.printStackTrace()可以输出异常信息
2.-1为抛出异常的习惯写法
3.如果方法中try,catch,finally中没有返回语句,则会调用这三个语句块之外的return结果
4.finally块无论如何,不管前面是正常还是异常,都要执行。
5.finally 在try中的return之后 在返回主调函数之前执行。
两个重要的关键字:throw和throws
1.throws的异常列表可以是抛出一条异常,也可以是抛出多条异常,每个类型的异常中间用逗号隔开
2.方法体中调用会抛出异常的方法或者是先抛出一个异常:用throw new Exception()
throw写在方法体里,表示“抛出异常”这个动作
3.如果某个方法调用了抛出异常的方法,那么必须添加try catch语句去尝试捕获这种异常,
只有Error,Exception,RuntimeException提供了带cause参数的构造器,其他的所有异常类只能通过initCause()来设置cause。
所有Throwable的子类构造器中都可以接受一个cause对象作为参数。cause是异常原由,代表着原始异常。既可以在当前位置创建并抛出行的异常,也可以通过cause追踪到异常最初发生的位置。
异常链是一种面向对象编程技术,指将捕获的异常包装进一个新的异常中并重新抛出的异常处理方式。原异常被保存为新异常的一个属性(比如cause)。这个想法是指一个方法应该抛出定义在相同的抽象层次上的异常,但不会丢弃更低层次的信息。
把捕获的异常包装成新的异常,在新异常里添加原始的异常,并将新异常抛出,它们就像是链式反应一样,一个导致(cause)另一个
这个想法是指一个方法应该抛出定义在相同的抽象层次上的异常,(将所有捕获到的异常包装为新的异常类,即定义在相同的抽象层次上抛出)但不会丢弃更低层次的信息。
实现异常链功能的两种基本写法:
public class chainTest {
/**
* @param args
* Test1抛出喝大了异常
* Test2调用test1捕获了喝大了异常,并且包装成运行时异常,继续抛出
* main方法中调用test2尝试捕获test2方法抛出的异常
*/
public static void main(String[] args) {
try{ // TODO Auto-generated method stub
chainTest ct=new chainTest();
ct.Test2();}
catch(Exception e){
e.printStackTrace();
}
}public void Test1()throws DrunkException{
throw new DrunkException("喝车别开酒");
}
public void Test2(){
try{
Test1();
}catch( DrunkException e){
RuntimeException rte=new RuntimeException(e);
//rte.initCause(e);
e.printStackTrace();
throw rte;
}
}
}
关于异常的经验总结总结:
1、处理运行时异常时,采用逻辑去合理规避同时辅助try-catch处理
2、在多重catch块后面,可以加一个catch(Exception)来处理可能会被遗漏的异常
3、对于不确定的代码,也可以加上try-catch,处理潜在的异常
4、尽量去处理异常,切记只是简单的调用printStackTrace()去打印
5、具体如何处理异常,要根据不同的业务需求和异常类型去决定
6、尽量添加finally语句块去释放占用的资源
Java 中的字符串
在 Java 中,字符串被作为 String 类型的对象处理。 String 类位于 java.lang 包中。默认情况下,该包被自动导入所有的程序。
String 对象创建后则不能被修改,是不可变的,所谓的修改其实是创建了新的对象,所指向的内存空间不同。
1、 通过 String s1="爱慕课"; 声明了一个字符串对象, s1 存放了到字符串对象的引用,常量字符串存储在堆内存中,s1只是对存放了到字符串的引用,通过 s1="欢迎来到:"+s1; 改变了字符串 s1 ,其实质是创建了新的字符串对象,变量 s1 指向了新创建的字符串对象,即使s1指向了另一块堆内存。
2、 一旦一个字符串在内存中创建,则这个字符串将不可改变。如果需要一个可以改变的字符串,我们可以使用StringBuffer或者StringBuilder(后面章节中会讲到)。
3、 每次 new 一个字符串就是产生一个新的对象,即便两个字符串的内容相同,使用 ”==” 比较时也为 ”false” ,如果只需比较内容是否相同,应使用 ”equals()” 方法(前面条件运算符章节讲过哦~~)
String常用方法
int length() 返回当前字符串的长度
int indexOf(int ch) 查找ch字符在该字符串中第一次出现的位置
int indexOf(String str) 查找str子字符串在该字符串中第一次出现的位置
int lastIndexOf(int ch) 查找ch字符在该字符串中最后一次出现的位置
int lastIndexOf(String str) 查找str子字符串在该字符串中最后一次出现的位置
String substring(int beginIndex) 获取从beginIndex位置开始到结束的子字符串
String substring(int beginIndex, int endIndex) 获取从beginIndex位置开始到endIndex位置的子字符串
String trim() 返回去除了前后空格的字符串
boolean equals(Object obj) 将该字符串与制定对象比较,返回true或false
String toLowerCase() 将字符串转换为小写
String toUpperCase() 将字符串转换为大写
char charAt(int index) 获取字符串中指定位置的字符
String[] split(String regex, int limit) 将字符串分割为子字符串,返回字符串数组
byte[] getBytes() 将该字符串转换为byte数组
在Java中,除了可以使用 String 类来存储字符串,还可以使用 StringBuilder 类或 StringBuffer 类存储字符串,其中:
(1)String 类具有是不可变性:多个字符串进行拼接了以后产生一个新的临时变量并指向一个新的对象或新的地址。
(2)StringBuffer 是线程安全的,而 StringBuilder 则没有实现线程安全功能,所以性能略高。
如果需要创建一个内容可变的字符串对象,应优先考虑使用 StringBuilder 类。
StringBuilder 对象,用来存储字符串,并对其做了追加和插入操作。这些操作修改了 str 对象的值,而没有创建新的对象,这就是 StringBuilder 和 String 最大的区别。
// 创建一个空的StringBuilder对象
StringBuilder str=new StringBuilder();
// 追加字符串
str.append("jaewkjldfxmopzdm");
// 从后往前每隔三位插入逗号
for(int i=str.length()-3;i>0;i=i-3)
str.insert(i,",");
// 将StringBuilder对象转换为String对象并输出
System.out.print(str.toString());
包装类(自动导入,让基本数据类型具有对象的特性)主要提供了两大类方法:(String,包装类都可以直接String或者Integer,Double,Float一个对象,包装类,系统自动导入)
1. 将本类型和其他基本类型进行转换的方法 对象.类型Value();
装箱:把基本类型转换成包装类,使其具有对象的性质,又可分为手动装箱和自动装箱。
int i=10; Integer x=new Integer(i);//手动装箱 Integer y=i;//自动装箱
拆箱:把包装类对象转换成基本类型的值,又可分手动拆箱和自动拆箱。
Integer j=new Integer(8); int m=j.intValue();//手动拆箱 int n=j;//自动拆箱。
2 将字符串和本类型及包装类互相转换的方法
装箱之后 基本数据类型就变成了类 而类具有很多属性和方法 比如 int 装箱成Integer后 Integer.MAX_VALUE 就代表了
int类型的最大值 Integer.toHexString可以将int类型的数值转变为字符串,而这些 int都做不到...
基本类型转换为字符串有三种方法:
1.包装类的toString()方法
2.String的valueOf()方法
3.用一个空字符串加上基本类型,得到的就是基本数据类型对应的字符串
eg:int c=10;
String str1=Integer.toString(c);
String str2=String.valueOf(c);
String str3=c+" ";
将字符串转换成基本类型有两种方法:
1.包装类的parseXxx静态方法
2.调用包装类的valueOf()方法转换为基本数据类型的包装类,会自动拆箱
String str="8";
int a=Integer.parseInt(str);
int b=Integer.valueOf(str);
ps:其它基本数据类型与字符串的相互转换方法都类似。
使用 Date 和 SimpleDateFormat 类表示时间
SimpleDateFormat 可以对日期时间进行格式化,(由于Date默认输出的时间格式不友好因此需要转换)如可以将日期转换为指
定格式的文本,也可将文本转换为日期。
1. 使用format()方法将日期转换为指定格式的文本
Date d = new Date();
SimpleDateFormat s = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//指定转换的目标格式,"yyyy-MM-dd HH:mm:ss"为预定义字符串。
String today = s.format(d);//结果如:2014-06-11 09:55:48
2. 使用parse()方法将文本转换为日期
String day = "2014年02月14日 10:30:20";
SimpleDateFormat s = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");//“yyyy年MM月dd日 HH:mm:ss” 指定了字
符串的日期格式,调用 parse() 方法将文本转换为日期。
Date date = s.parse(day);//结果如:Fri Feb 14 10:30:20 CST 2014
注意:
1、调用SimpleDateFormat对象的parse()方法时可能会出现转换异常,即ParseException,因此需要进行异常处理。
2、指定日期格式中的月MM和小时HH必须大写,小写结果会不同的。
3、使用Date 类时需要导入java.util包,使用SimpleDateFormat时需要导入java.text包。
Calendar 类的应用
Calendar 类
1.通过调用 getInstance() 静态方法获取一个 Calendar 对象---对象已初始化
Calendar c = Calendar.getInstance();
2.通过调用 get() 方法获取日期时间信息
int month=c.get(Calendar.MONTH)+1;----0表示1月份
3.提供 getTime() 方法,用来获取 Date 对象
Date date=c.getTime();----将Calender对象转换为Date对象
4.通过 getTimeInMillis() 方法,获取此 Calendar 的时间值
long time=c.getTimeInMillis();----获取当前毫秒
使用 Math 类操作数据
Math 类位于 java.lang 包中,包含用于执行基本数学运算的方法, Math 类的所有方法都是静态方法,所以使用该类中的方法时,可以直接使用类名.方法名,如: Math.round();
集合框架
1.常用容器继承关系图
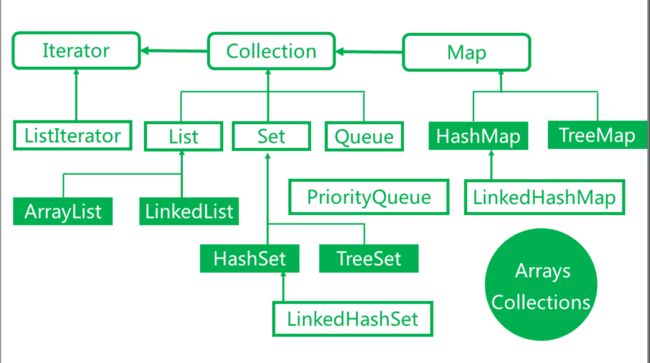
Iterator不是容器,只是一个操作遍历集合的方法
2.Collection和Map
在Java容器中一共定义了2种集合, 顶层接口分别是Collection和Map。但是这2个接口都不能直接被实现使用,分别代表两种不同类型的容器。
Collection:是容器继承关系中的顶层接口。是一组对象元素组。有些容器允许重复元素有的不允许,有些有序有些无序。 JDK不直接提供对于这个接口的实现,但是提供继承与该接口的子接口比如 List Set。
接口定义:
public interface Collection
...
}
泛型
几个重要的接口方法:
add(E e)确保此 collection 包含指定的元素(可选操作)。
clear()移除此 collection 中的所有元素(可选操作)。
contains(Object o)如果此 collection 包含指定的元素,则返回 true。
isEmpty()如果此 collection 不包含元素,则返回 true。
iterator()返回在此 collection 的元素上进行迭代的迭代器。
remove(Object o)从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。
retainAll(Collection c)仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。
size()返回此 collection 中的元素数
toArray()返回包含此 collection 中所有元素的数组
toArray(T[] a)返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同
Map:一个保存键值映射的对象。 映射Map中不能包含重复的key,每一个key最多对应一个value。
Map集合提供3种遍历访问方法:
1.获得所有key的集合然后通过key访问value。
2.获得value的集合。
3.获得key-value键值对的集合(key-value键值对其实是一个对象,里面分别有key和value)。
Map的访问顺序取决于Map的遍历访问方法的遍历顺序。 有的Map,比如TreeMap可以保证访问顺序,但是有的比如HashMap,无法保证访问顺序。
接口定义如下:
public interface Map {
...
interface Entry {
K getKey();
V getValue();
...
}
}
泛型分别代表key和value的类型。这时候注意到还定义了一个内部接口Entry,其实每一个键值对都是一个Entry的实例关系对象,所以Map实际其实就是Entry的一个Collection,
然后Entry里面包含key,value。再设定key不重复的规则,自然就演化成了Map。(个人理解)
几个重要的接口方法:
clear()从此映射中移除所有映射关系
containsKey(Object key)如果此映射包含指定键的映射关系,则返回 true。
containsValue(Object value)如果此映射将一个或多个键映射到指定值,则返回 true。
entrySet()返回此映射中包含的映射关系的 Set 视图。
equals(Object o) 比较指定的对象与此映射是否相等。
get(Object key)返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。
isEmpty()如果此映射未包含键-值映射关系,则返回 true。
keySet()返回此映射中包含的键的 Set 视图。
put(K key, V value)将指定的值与此映射中的指定键关联(可选操作)。
putAll(Map m)从指定映射中将所有映射关系复制到此映射中(可选操作)。
remove(Object key)如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。
size()返回此映射中的键-值映射关系数。
values()返回此映射中包含的值的 Collection 视图。
3个遍历Map的方法:
1.Set keySet():会返回所有key的Set集合,因为key不可以重复,所以返回的是Set格式,而不是List格式。
获取到所有key的Set集合后,由于Set是Collection类型的,所以可以通过Iterator去遍历所有的key,然后再通过get方法获取value
如下:
Map map = new HashMap();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Set keySet = map.keySet();//先获取map集合的所有键的Set集合
Iterator it = keySet.iterator();//有了Set集合,就可以获取其迭代器。
while(it.hasNext()) {
String key = it.next();
String value = map.get(key);//有了键可以通过map集合的get方法获取其对应的值。
System.out.println("key: "+key+"-->value: "+value);//获得key和value值
}
2.Collection values():直接获取values的集合,无法再获取到key。所以如果只需要value的场景可以用这个方法。获取到后使用Iterator去遍历所有的value。
如下:
Map map = new HashMap();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Collection collection = map.values();//返回值是个值的Collection集合
System.out.println(collection);
3.Set< Map.Entry< K, V>> entrySet():是将整个Entry对象作为元素返回所有的数据。然后遍历Entry,分别再通过getKey和getValue获取key和value。
如下:
Map map = new HashMap();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
//通过entrySet()方法将map集合中的映射关系取出(这个关系就是Map.Entry类型)
Set> entrySet = map.entrySet();
//将关系集合entrySet进行迭代,存放到迭代器中
Iterator> it = entrySet.iterator();
while(it.hasNext()) {
Map.Entry me = it.next();//获取Map.Entry关系对象me
String key = me.getKey();//通过关系对象获取key
String value = me.getValue();//通过关系对象获取value
}
通过以上3种遍历方式我们可以知道,如果你只想获取key,建议使用keySet。如果只想获取value,建议使用values。如果key value希望遍历,建议使用entrySet。
(虽然通过keySet可以获得key再间接获得value,但是效率没entrySet高,不建议使用这种方法)
3.List、Set和Queue
List和Set。他们2个是继承Collection的子接口,就是说他们也都是负责存储单个元素的容器。
最大的区别如下:
1.List是存储的元素容器是有个有序的可以索引到元素的容器,并且里面的元素可以重复。
2.Set里面和List最大的区别是Set里面的元素对象不可重复。
List:一个有序的Collection(或者叫做序列)。使用这个接口可以精确掌控元素的插入,还可以根据index获取相应位置的元素。
不像Set,list允许重复元素的插入。有人希望自己实现一个list,禁止重复元素,并且在重复元素插入的时候抛出异常,但是我们不建议这么做。
List提供了一种特殊的iterator遍历器,叫做ListIterator。这种遍历器允许遍历时插入,替换,删除,双向访问。 并且还有一个重载方法允许从一个指定位置开始遍历。
List接口新增的接口,会发现add,get这些都多了index参数,说明在原来Collection的基础上,List是一个可以指定索引,有序的容器。
在这注意以下添加的2个新Iteractor方法:
ListIterator listIterator();
ListIterator listIterator(int index);
ListIterator的代码:
public interface ListIterator extends Iterator {
// Query Operations
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
一个集合在遍历过程中进行插入删除操作很容易造成错误,特别是无序队列,是无法在遍历过程中进行这些操作的。
但是List是一个有序集合,所以在这实现了一个ListIteractor,可以在遍历过程中进行元素操作,并且可以双向访问。
List的实现类,ArrayList和LinkedList.
1.ArrayList
ArrayList是一个实现了List接口的可变数组
可以插入null
它的size, isEmpty, get, set, iterator,add这些方法的时间复杂度是O(1),如果add n个数据则时间复杂度是O(n).
ArrayList不是synchronized的。
然后我们来简单看下ArrayList源码实现。这里只写部分源码分析。
所有元素都是保存在一个Object数组中,然后通过size控制长度。
transient Object[] elementData;
private int size;
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
其实在每次add的时候会判断数据长度,如果不够的话会调用Arrays.copyOf,复制一份更长的数组,并把前面的数据放进去。
我们再看下remove的代码是如何实现的。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
其实就是直接使用System.arraycopy把需要删除index后面的都往前移一位然后再把最后一个去掉。
2.LinkedList
LinkedList是一个链表维护的序列容器。和ArrayList都是序列容器,一个使用数组存储,一个使用链表存储。
数组和链表2种数据结构的对比:
1.查找方面。数组的效率更高,可以直接索引出查找,而链表必须从头查找。
2.插入删除方面。特别是在中间进行插入删除,这时候链表体现出了极大的便利性,只需要在插入或者删除的地方断掉链然后插入或者移除元素,然后再将前后链重新组装,但是数组必须重新复制一份将所有数据后移或者前移。
3.在内存申请方面,当数组达到初始的申请长度后,需要重新申请一个更大的数组然后把数据迁移过去才行。而链表只需要动态创建即可。
如上LinkedList和ArrayList的区别也就在此.
总结:
List实现 使用场景 数据结构
ArrayList 数组形式访问List链式集合数据,元素可重复,访问元素较快 数组
LinkedList 链表方式的List链式集合,元素可重复,元素的插入删除较快 双向链表
Vector: 底层是数组数据结构。线程同步。被ArrayList替代了。因为效率低。
4.Set
Set的核心概念就是集合内所有元素不重复。在Set这个子接口中没有在Collection特别实现什么额外的方法,应该只是定义了一个Set概念。下面我们来看Set的几个常用的实现HashSet、LinkedHashSet、TreeSet
HashSet:
HashSet实现了Set接口,基于HashMap进行存储。遍历时不保证顺序,并且不保证下次遍历的顺序和之前一样。HashSet中允许null元素。
进入到HashSet源码中我们发现,所有数据存储在:
private transient HashMap map;
private static final Object PRESENT = new Object();
意思就是HashSet的集合其实就是HashMap的key的集合,然后HashMap的val默认都是PRESENT。HashMap的定义即是key不重复的集合。使用HashMap实现,这样HashSet就不需要再实现一遍。
所以所有的add,remove等操作其实都是HashMap的add、remove操作。遍历操作其实就是HashMap的keySet的遍历,举例如下
...
public Iterator iterator() {
return map.keySet().iterator();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public void clear() {
map.clear();
}
...
LinkedHashSet:
LinkedHashSet的核心概念相对于HashSet来说就是一个可以保持顺序的Set集合。HashSet是无序的,LinkedHashSet会根据add,remove这些操作的顺序在遍历时返回固定的集合顺序。这个顺序不是元素的大小顺序,而是可以保证2次遍历的顺序是一样的。
类似HashSet基于HashMap的源码实现,LinkedHashSet的数据结构是基于LinkedHashMap。过多的就不说了。
TreeSet:
TreeSet即是一组有次序的集合,如果没有指定排序规则Comparator,则会按照自然排序。(自然排序即e1.compareTo(e2) == 0作为比较)
注意:TreeSet内的元素必须实现Comparable接口。
TreeSet源码的算法即基于TreeMap,具体算法在说明TreeMap的时候进行解释。
总结:
Set实现 使用场景 数据结构
HashSet 无序的、无重复的数据集合 基于HashMap
LinkedSet 维护次序的HashSet 基于LinkedHashMap
TreeSet 保持元素大小次序的集合,元素需要实现Comparable接口 基于TreeMap
4.HashMap、LinkedHashMap、TreeMap和WeakHashMap
HashMap就是最基础最常用的一种Map,它无序,以散列表的方式进行存储。之前提到过,HashSet就是基于HashMap,只使用了HashMap的key作为单个元素存储。
HashMap的访问方式就是继承于Map的最基础的3种方式,详细见上。在这里我具体分析一下HashMap的底层数据结构的实现。
在看HashMap源码前,先理解一下他的存储方式-散列表(哈希表)。像之前提到过的用数组存储,用链表存储。哈希表是使用数组和链表的组合的方式进行存储。(具体哈希表的概念自行搜索)如下图就是HashMap采用的存储方法。
详细:http://www.jianshu.com/p/047e33fdefd2
总结
Map实现 使用场景 数据结构
HashMap 哈希表存储键值对,key不重复,无序 哈希散列表
LinkedHashMap 是一个可以记录插入顺序和访问顺序的HashMap 存储方式是哈希散列表,但是维护了头尾指针用来记录顺序
TreeMap 具有元素排序功能 红黑树
WeakHashMap 弱键映射,映射之外无引用的键,可以被垃圾回收 哈希散列表