第一次上kaggle来做实训,第一印象界面美观,向导友好,难怪有那么多人来推荐。数据集也很丰富,有关于欧洲足球的,美国总统竞选的,计算机语言使用调查的,人力资源分析,历史上的飞机事故统计,IMDB电影的数据分析,还有些脱敏的金融借贷信息。
找到了Titanics数据集,跟着向导第一次做任务,datacamp中的课程有任务说明,可以根据提示写代码,然后提交,错误还可以根据提示进行修正,直到教会你为止。感觉和以前打一个新游戏的任务向导很像。
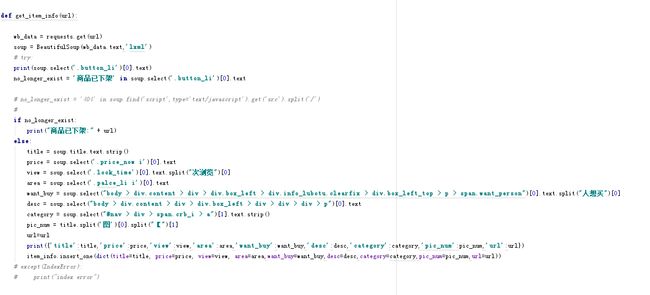 666.png
666.png
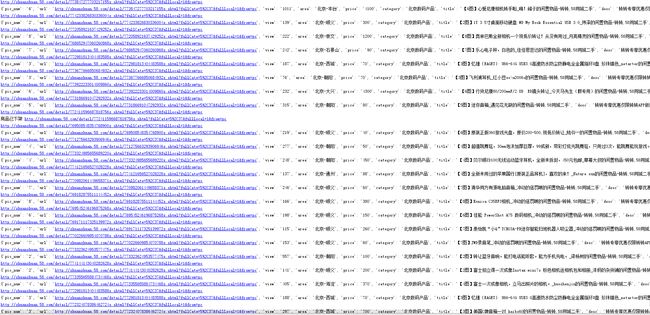 888.png
888.png 存储

3.展示
经验与难点:
- 爬取
a). 爬取过程中发现有些商品已经下架,造成信息无法正确提取,爬取中断。
为了解决这个问题需要判断一下页面上的一些提示信息,具体如下:
no_longer_exist = '商品已下架' in soup.select('.button_li')[0].text
if no_longer_exist:
print("商品已下架:" + url)
else:
codes to be executed
b). 爬取过程中发现其实这个网站经过改版,同时存在两种类型的详情页,一种是58转转的,一种是极个别的老的网页。当爬到老的网页时,由于元素位置和名称和转转结构不一致造成报错。
为了排除这些错误,在执行代码
加了try...except异常处理。
try:
codes to be executed
except(IndexError):
print("index error")
c). 当爬取中断的时候想断点续爬,比如想爬10万条,爬了5万条遇到错误中断,想避免之前的重复爬取,而是接着5万条继续爬取。
先访问数据库中的链接数据列表,得到所有的链接全集内容。
然后访问详情页中已经爬取的链接列表。然后分别把他们放到集合中,再将两个集合相减,由于集合相减做的是差运算,得到的结果就是那些还没有爬取的链接内容,然后进行爬取。
db_urls = [item["url"] for item in url_list.find()]
index_urls = [item["url"] for item in item_info.find()]
x = set(db_urls)
y = set(index_urls)
rest_of_urls = x - y
这边用了一个循环列表表达式,据说性能是原来for循环的10倍,所有的循环赋值语句都可以使用,是一个不错的提高性能的小技能。
d). 提高性能,使用多线程进行操作
首先创建一个线程池对象,并且把处理器参数设置成等于PC的CPU个数,注意过多或者过少设置处理器参数都不能最大化的优化处理速度。然后使用map函数或者process函数对链接和详细页分别进行爬取。
使用多线程技术以后,爬取速度是原来的200-300%,链接列表爬取每小时8万条,详情页大概每小时2万条。
如果还想进一步提升性能,可以在解析网页的时候不使用BeautifulSoup函数,而是直接用lxml来解析,速度可以提升8-10倍。但是考虑网站负载问题,速度和安全性相比,肯定还是需要更加安全小心的去爬取。
e). 由于这些二手发布网站的网站性能较好,没有刻意的对爬虫进行封锁,但是为了安全起见还是应该对Header,cookies以及agent进行伪装。或者可以进行随机更换proxy代理ip来访问网站。
headers = {'UserAgent':'Mozilla/5.0 (Windows NT 5.1; rv:37.0) Gecko/20100101 Firefox/37.0'}
proxy_list =
[
'http://117.177.250.151:8081',
'http://111.85.219.250:3129',
'http://122.70.183.138:8118',
]
proxy_ip = random.choice(proxy_list)
proxies = {'http':proxy_ip}
f). 还有些细节,比如爬取访问量和购买数量的时候会带一些中文字符,而不是纯数字,比如“201次浏览”,"【9图】"等。
为了提取数字,可以使用
view = soup.select('.look_time')[0].text.split("次浏览")[0]
pic_num = title.split('图')[0].split("【")[1]
这样在爬取端就解决了数据格式的问题,比在后期在数据库端解决相对容易。
- 存储
a). 由于担心误操作,把辛辛苦苦哭花了10几个小时爬取的数据给更新错误,所以做任何数据库操作之前需要对数据库进行备份。
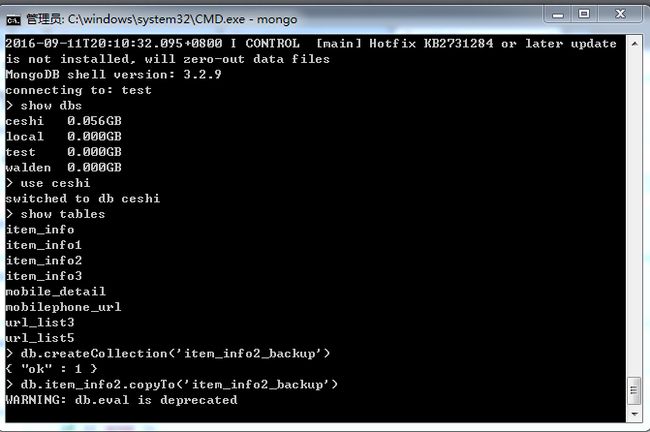
b). Mongodb数据库不是基于SQL语言进行查询的,而是面向对象的操作,所有的操作都需要重新学习。
http://www.runoob.com/mongodb/mongodb-tutorial.html
详情参见上述网页
- 展示
a). 首先是需要安装charts库和安装网页编辑器jupyter库(这个东东可以代替pycharm进行IDE开发),然后要去配置jupyter服务器,并且登录上。
http://localhost:8888/tree#
在命令行里输入:jupyter notebook,自动运行网页编辑器,然后新建一个python3文件。
shift+enter是执行
然后在网页上可以直接生成图表
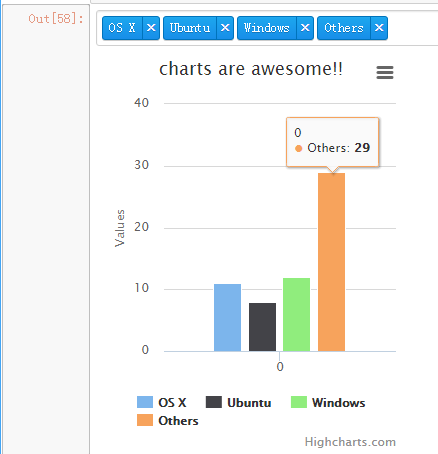
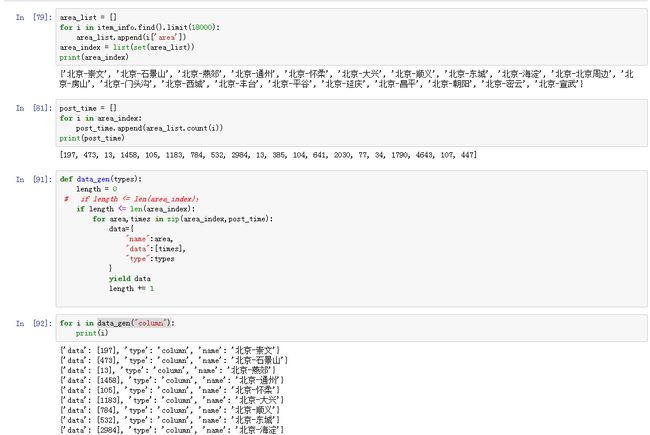
b). 由于highcharts是用jquery开发,所以有一定的格式需要遵循,意味着要进行格式转换。
读取数据库文件然后用程序来自动生成。
def data_gen(types):
length = 0
if length <= len(area_index):
if length <= len(area_index):
for area,times in zip(area_index,post_time):
data={
"name":area,
"data":[times],
"type":types
}
yield data
length += 1
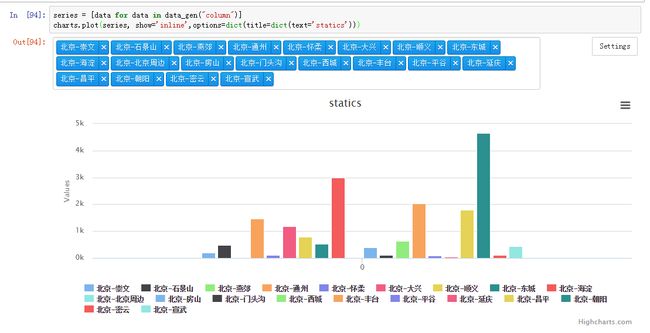
series = [data for data in data_gen("column")]
charts.plot(series, show='inline',options=dict(title=dict(text='statics')))
这里的难点是yield函数,就是生成器函数,这个是python比较中特殊的机制。
http://www.cnblogs.com/tqsummer/archive/2010/12/27/1917927.html
“生成器函数在Python中与迭代器协议的概念联系在一起。简而言之,包含yield语句的函数会被特地编译成生成器。当函数被调用时,他们返回一个生成器对象,这个对象支持迭代器接口。函数也许会有个return语句,但它的作用是用来yield产生值的。
不像一般的函数会生成值后退出,生成器函数在生成值后会自动挂起并暂停他们的执行和状态,他的本地变量将保存状态信息,这些信息在函数恢复时将再度有效”
简而言之作用就是减少python的内存开销,更加高效快速地执行运算操作。