协程是指一个过程,这个过程与调用方协作,产出由调用方提供的值。目前我的理解就是协程是定义了yield关键字的生成器函数。
1.yield
In [1]: def simple_coroutine():
...: print('->coroutine started')
...: x = yield
...: print('-> coroutine received:',x)
...:
In [2]: my_coro = simple_coroutine()
In [3]: my_coro
Out[3]:
In [4]: next(my_coro)
->coroutine started
In [5]: my_coro.send(42)
-> coroutine received: 42
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
in ()
----> 1 my_coro.send(42)
StopIteration:
常用的方法:
yield:产出值给调用方,并暂停生成器(函数)
.send(value):调用发把值传给生成器yield左边赋值的变量,并继续开始执行生成器(函数)
.throw():致使生成器在暂停的yield表达式处抛出指定的异常。
def gen():
yield 1
yield 2
yield 3
g = gen()
print(next(g))
g.throw(RuntimeError)
结果
Traceback (most recent call last):
1
File "/demo.py", line 69, in
g.throw(RuntimeError)
File "/demo.py", line 63, in gen
yield 1
RuntimeError
.close():致使生成器在暂停的yield表达式处抛出GeneratorExit异常
注意:仅当协程处于暂停状态时才能调用send方法,如果协程没有激活(即状态是GEN_CREATED),直接会出错。因此始终要调用next(my_coro)预激活协程——也可以调用my_coro.send(None),效果一样
如果你忘记预激协程,可以使用装饰器coroutine来装饰协程,该装饰器定义如下:
from functools import wraps
def coroutine(func):
@wraps(func)
def primer(*args,**kwargs):
gen = func(*args,**kwargs)
next(gen)
return gen
return primer
使用
@coroutine
def gen():
...
2.yield from
用法:yield from iterable[协程]
顾名思义,就是从iterable[协程]中产出值
def gen():
print('hhhh')
yield from [1, 2, 3, 4]
g = gen()
print(g.__next__()) # hhh,1
print(g.__next__()) # 2
yield from的作用:
- 如果生成器函数需要产出另一个生成器生成的值,传统的方式就是使用嵌套的for循环。使用yield from可以替代产出值的嵌套for循环。
-
打来双向通道,把最外层的调用方与最内层的子生成器连接起来,这样两者可以直接发送和产出值,还可以直接传入异常,而不用在位于中间的协程中添加大量处理异常的样板代码。有了这个结构,协程可以通过以前不可能的方式委托职责
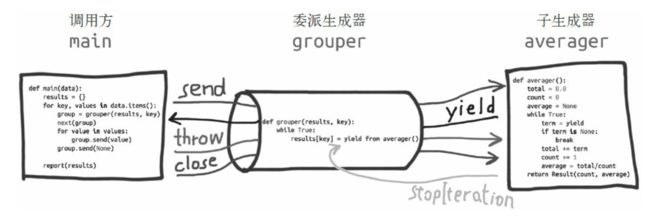 image.png
image.png
解释:委派生成器在yield from表达式处暂停时,调用方可以直接把数据发给子生成器,子生成器再把产出的值发给调用方。子生成器返回之后,解释器会抛出StopIteration异常,并把返回值附加到异常对象上,此时委派生成器会恢复(我们之所以看不到这些异常对象,是因为yield from帮我们做了这些工作)
from collections import namedtuple
Result = namedtuple('Result','count average')
# 子生成器
def averager(): # <1>
total = 0.0
count = 0
average = None
while True:
term = yield # <2>
if term is None: # <3>
break
total += term
count += 1
average = total/count
return Result(count, average) # <4>
# 委派生成器
def grouper(results, key): # <5>
while True: # <6>
results[key] = yield from averager() # <7>
# 客户端调用,即调用方
def main(data): # <8>
results = {}
for key, values in data.items():
group = grouper(results, key) # <9>
next(group) # <10>
for value in values:
group.send(value) # <11>
group.send(None) # important! <12>
# print(results) # uncomment to debug
report(results)
# 输出报告
def report(results):
for key, result in sorted(results.items()):
group, unit = key.split(';')
print('{:2} {:5} averaging {:.2f}{}'.format(
result.count, group, result.average, unit))
data = {
'girls;kg':
[40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m':
[1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg':
[39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m':
[1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46],
}
if __name__ == '__main__':
main(data)
结果:
9 boys averaging 40.42kg
9 boys averaging 1.39m
10 girls averaging 42.04kg
10 girls averaging 1.43m
部分解释:
7:grouper会在yield from表达式处暂停,等待averager实例处理客户端发来的值。averager实例运行完毕后,返回的值绑定到result[key]上。while循环会不断创建averager实例,处理更多的值。
11:把各个value传给grouper。传入的值最终到达averager函数中term=yield那一行;grouper永远不知道传入的值是什么。
12:把None传入grouper,导致当前的averager实例终止,也让grouper继续运行,在建一个averager实例,处理下一组值。
上面的例子表面的关键一点是:如果子生成器不终止,委派生成器会在yield from表达式永远暂停。