车机从WinCE逐步进化到Android,从不能通讯到带4G通讯,随之带来了一系列的新技术的应用。今天就来介绍当前车机必须技术之语音识别技术(全称是自动语音识别 Automatic Speech Recognition,简称ASR)。
发展历史
语音识别技术最早可以追溯到20世纪二、三十年代,如早期(1939年)贝尔实验室在纽约世博会上展示了他们的语音综合机器。
20世纪70年代中叶见证了在孤立字识别领域上许多里程碑式的进步。首先俄国的研究者们展示了在语音识别中运用模式识别(Pattern Recognition)的想法,日本的研究者成功运用到了动态编程编码(Dynamic Programming code),其次卡内基梅隆大学在1973向世人展示了Heresay I语音理解系统,能够在1011个单词的词汇表中以较好的准确性识别语音。
80年代起在连接词识别上获得了比较好的成效,特别是隐马尔可夫模型(Hidden Markov Model,下面简称HMM)的发展并被大范围的接受。同时语音识别最具转折性和建设性的发展即统计方法的引入也是该时期的成就,包括HMM、期望最大化(EM),最大互信息(MMI)等,还有信号表述技术的发展也是该时期出现,如梅尔频率倒谱系数(MFCC),感知线性预测常数(PLP)等。
时至今日,由于硬件的支持、GPU的发展使得深度学习不断发展,许多研究者从传统的高斯混合模型(GMM)和HMM结合转向深度神经网络(DNN)与HMM结合,并取得了不小的成效。另外还有两点可喜的发展:一是语料库的不断完善和数据集的不断增多(如TIMIT、TI46数据集等),二是面向大量音频数据处理的工具的出现和不断完善(如CMU的Sphinx,剑桥大学的HTK,国内的科大讯飞、云之声等)。
基础语音识别模型
一个标准的语音识别模型首先假定有一串输入序列O = {O1, O2, .., On},以及符号词典 W = {W1, W2, .., W_n},求解对于该输入序列解码出符号串(输出语句)W = {W1, W2, .., Wk}。通过数学转化成求解以下概率的最大值:
W = argmax(P(O|W)P(W))
其中P(O|W)被称之为声学模型,P(W)被称为语言模型。 该模型的求解过程如下图所示,其中的搜索,就是依据对公式中的声学模型打分和语言模型打分,寻找一个词模型序列以描述输入语音信号,从而得到词解码序列。
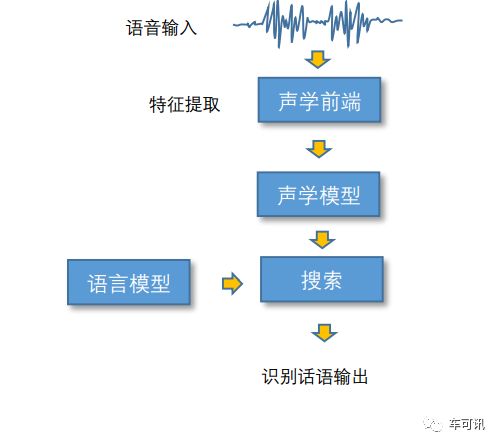
大规模连续语音识别模型
大规模连续语音识别(Large Vocabulary Continuous Speech Recognition,LVCSR)不同于一般的模式识别,它需要解决一些棘手的特殊问题。比如说,在连续语音流中,每个发音都没有一个清晰的边界,难于进行一般的模式匹配,而且不同人之间的语音语速千差万别,甚至同一个人不同时间的发音也有相当大的变化,这就给模型的建立提出了巨大的挑战。另外,语言的规律千变万化,使得实现高效智能的语音识别就更加困难。下图为连续语音识别系统示意图:

语音识别的工作流程
一般来说,一套完整的语音识别系统其工作过程分为7步:
对语音信号进行分析和处理,除去冗余信息。
提取影响语音识别的关键信息和表达语言含义的特征信息。
紧扣特征信息,用最小单元识别字词。
按照不同语言的各自语法,依照先后次序识别字词。
把前后意思当作辅助识别条件,有利于分析和识别。
按照语义分析,给关键信息划分段落,取出所识别出的字词并连接起来,同时根据语句意思调整句子构成。
结合语义,仔细分析上下文的相互联系,对当前正在处理的语句进行适当修正。
前端参数化或特征提取
在语音识别中,特征抽取的主要目的是在给定一个紧凑的输入信号表示计算出特征向量的简约序列。主要分成三个步骤:语音分析(语音前端声学处理);编译成包含动静态的扩展特征向量;将这些扩展后的特征向量转化成影响因子更大的向量,然后提供给识别器,还包括预加重、分帧加窗及端点检测等。
现在主要有下面的一些模型:
主元成分分析(PCA);
线性判别式分析(LDA);
独立成分分析(ICA);
线性预测编码(Perceptual Linear Predictive,PLP);
倒谱分析;
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFFC)
滤波器分析;
基于核函数的特征抽取等。
特别说明中文声学特征
一般将一个字的发音切割成两个部分,分别是声母(initials)与韵母(finals)。而在发音的过程之中,声母转变至韵母是一个渐进而非瞬间的改变,因此使用右文相关声韵母模式(Right-Context-Dependent Initial Final, RCDIF)作为分析方法,可以更精准的辨识出正确的音节(syllable)。 而根据声母的不同特征,又可以将声母分为下面四类:爆破音(Plosive)、摩擦音(Fricative)、爆擦音(Affricate)、鼻音(Nasal)。
而韵母又有双元音、单元音之分,要视再发生时是否有音调的改变。而根据声带振动与否,又分为清音(unvoiced:声带不震动)、浊音等差异,以上发音时不同的方式,在时频图上大多可以找到相对应的特征,透过处理二维的时频图,借由传统影像处理的方式,达到语音辨识的目的。
声学模型
声学模型是语音识别系统中最为关键的一部分。声学模型的目标是提供一种有效的方法,计算语音的特征矢量序列和每个发音模板之间的距离。声学模型的设计和语言发音特点密切相关。模型识别单元大小(词发音模型、字发音模型、 半音节模型或音素模型)对语音训练数据量大小、 语音识别率,以及灵活性有较大的影响。对中等词汇量以上的语音识别系统来说,识别单元小,则计算量也小,所需的模型存储量也小,要求的训练数据量相对也小,所需的模型存储量也小,要求的训练数据量相对也少,但带来的问题是对应语音段的定位和分割困难,以及更复杂的识别模型规则。通常大的识别单元易于包括协同发音在模型中,这有利于提高系统的识别率,但要求的训练数据相对增加,当然,对于现在大数据处理技术来说,训练数据的增多问题不大。
以直接对词进行建模是最直接的,也是最简单的。但是这就需要在训练数据中,每个词都有足够多的训练样本。这往往难以做到,尤其是对于大词汇量语音识别。因此,现在普遍采用的是对音素(Phone,多个音素组成一个词) 这样的子词单元进行建 模,随着大数据处理技术和神经网络的发展,也有按照词为单位来建模的方式在研究。
下图为基于隐式马尔科夫模型HMM的音素模型:
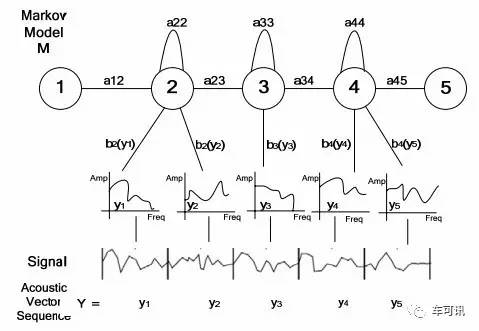
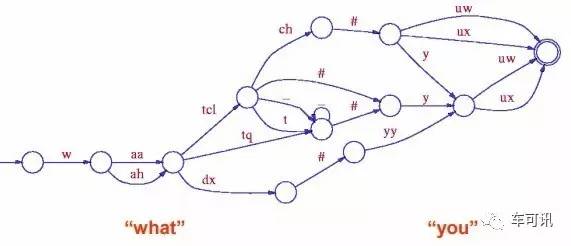
具体识别链的例子:
语言模型
语言模型(Language Model,LM)是为了在语音识别的过程中有效地结合语法和语义的知识,提 高识别率,减少搜索的范围。由于很难准确地确定词的边界,以及声学模型描述语音变异性的能力有限,识别时将产生很多概率得分相似的词的序列。 因此,在实用的语音识别系统中通常使用语言模型 P(W)从诸多候选结果中选择最有可能的词序列来弥补声学模型的不足。
语言模型可以分为基于规则的语言模型和基于统计的语言模型。基于规则的语言模型是总结出语法规则乃至语义规则,然后用这些规则排除声学识别中不合语法规则或语义规则的结果。统计语言模 型通过统计概率描述词与词之间的依赖关系,间接地对语法或语义规则进行编码。基于规则的语言模型在特定任务系统中获得很好的应用,可较大幅度提高系统的识别率。由于日常口语对话无法用严格的规则描述,在大词汇量语音识别系统中主要采用 基于统计的语言模型。
识别方法或搜索模型
对于连续语音识别来讲,识别的最终目的是从各种可能的音素模型状态序列形成的网络中找出最优的词序列(即最优路径)。这实质上属于解码算法或搜索算法的范畴。 语音识别算法的具体识别搜索算法的实现要根据语言的特点、模型的整体结构进行设计。
语音识别的搜索算法可以分为几类:
深度优先(Depth-first),通常包括堆栈解码器、A*解码算法;
宽度优先 (Breadth-first)。包括维特比 (Viterbi)解码算法;
人工智能方式:基于知识的专家系统;
神经网络方式:多隐藏层的深度神经网络(DNN),深度循环网络(RNN)等。
一个完整例子:
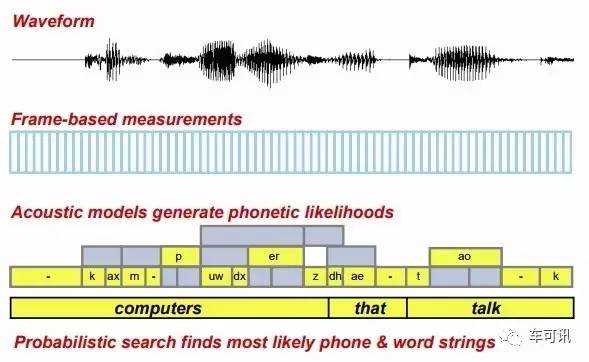
对识别结果的评测
语音识别中的评测一般分为正确率 (Correctness)和准确率(Accuracy):

其中 , “NREF” 表示待识别词的总数, “SUB”表示替换错误的次数,“DEL”表示删除错 误的次数,“INS”表示插入错误的次数。
语音识别的挑战
处理环境噪声和缺失信息的处理,未来的语音识别系统还是要更优化地解决它。
各种变量对于语音处理的挑战。比如说话风格,演说人的生理因素,年龄,情绪等。
对于语音系统可行度的评估分析。
对于数据中一些不能被词典所包括的超纲词汇以及生僻字对于语音识别的影响研究。
展望
当前简单的语音识别技术已经比较成熟,进入了实用阶段,训练后的识别率普遍能达到95%以上。
但是针对诸如电话交谈语音、微信交流语音,以及多方会议等复杂环境下的语音识别效果然仍需要有大的提升空间。
而对于联系上下文对语义进行充分的识别,则还是处于初始起步阶段,目前没有很好的方式来实现,后续随着人工智能、深度学习的发展,看在这个方面是否能有所突破。