环境
- 操作系统:Ubuntu 14.04
- Hadoop版本:Hadoop 2.6.5
- JDK版本:OpenJDK 1.7
创建Hadoop用户
创建用户
sudo useradd -m hadoop
为新用户设置密码
sudo passwd hadoop
为新用户添加权限
sudo adduser hadoop sudo
如果失败,则切换到root用户下,修改/etc/sudoers文件,将hadoop用户添加进去。
安装SSH Server、配置SSH免密钥登录
Ubuntu默认安装了SSH client,还需要安装SSH server。集群、单节点模式都需要用到SSH无密码登陆。
sudo apt-get install openssh-server
设置登录到本机
运行命令:
ssh localhost

会有如下提示,输入yes。
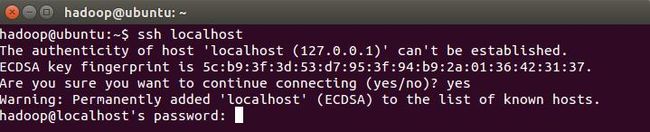
SSH首次登陆提示。然后按提示输入密码hadoop,这样就登陆到本机了。但这样的登陆是需要密码的,需要配置成无密码登陆。
配置免密钥登录
运行命令:
cd ~/.ssh
ssh-keyen
连按三次回车。

再运行命令(将公钥拷贝到本地):
ssh-copy-id -i ~/.ssh/id_rsa.pub localhost

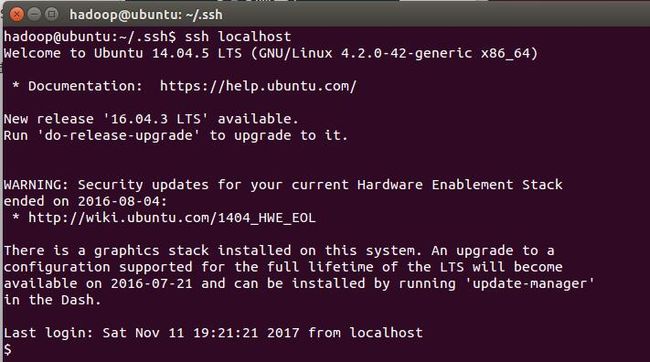
此时再执行 ssh localhost 命令,就可以直接登陆了,如下图所示。
配置Java环境
下载JDK
根据 Hadoop Java Versions 中的罗列的 Tested JDK 项可知,Hadoop 支持 openjdk 1.7,因此下载 openjdk 1.7。运行如下命令,下载 openjdk 1.7:
sudo apt-get install openjdk-7-jre openjdk-7-jdk
JDK默认安装在 /usr/lib/jvm/java-7-openjdk-amd64,运行java -version
出现下图,表示 jdk 安装成功。

配置JDK环境变量
运行如下命令,来编辑全局环境变量文件
sudo vim /etc/environment
在文件末尾添加一行:
JAVA_HOME="/usr/lib/jvm/java-7-openjdk-amd64"
注销或重启后,在终端执行echo $JAVA_HOME即可查看环境变量是否生效,生效后的效果如下图。

安装、配置 Hadoop 2.6.5
下载 Hadoop
从 Hadoop官网 上下载 Hadoop二进制压缩包 hadoop-2.6.5.tar.gz 到本地目录中。下载完成后解压缩:
cd ~/software/
sudo tar -zxvf hadoop-2.6.5.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local
sudo mv hadoop-2.6.5 hadoop # 将文件名改为hadoop
sudo chown -R hadoop:hadoop /usr/local/hadoop # 修改文件权限
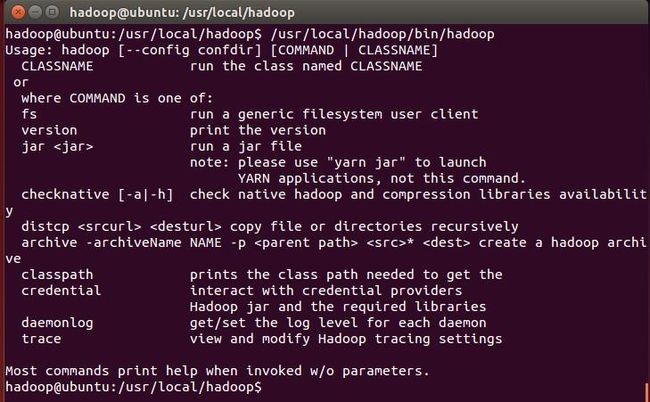
Hadoop解压后即可使用,输入如下命令Hadoop检查是否可用:
/usr/local/hadoop/bin/hadoop
可用则会显示命令行的用法:
Hadoop单机配置
Hadoop默认配置是以非分布式模式运行,即单Java进程,方便进行调试。可以执行附带的例子WordCount来查看Hadoop的运行。例子将Hadoop的配置文件作为输入文件,统计符合正则表达式dfs[a-z.]+的单词的出现次数。
cd /usr/local/hadoop
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep input output 'dfs[a-z.]+'
cat ./output/*
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词dfsadmin,出现了1次。

Hadoop伪分布式配置
Hadoop可以在单节点上以伪分布式的方式运行,此时Hadoop进程以分离的Java进程来运行,节点既是NameNode也是DataNode。这种情况下,需要修改etc/hadoop/目录下core-site.xml和hdfs-site.xml。Hadoop的配置文件是xml格式,声明property的name和value。
修改配置文件 etc/hadoop/core-site.xml
将 etc/hadoop/core-site.xml 文件中的
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
some description
fs.defaultFS
hdfs://localhost:9000

修改配置文件etc/hadoop/hdfs-site.xml
将 etc/hadoop/hdfs-site.xml 文件中的
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data

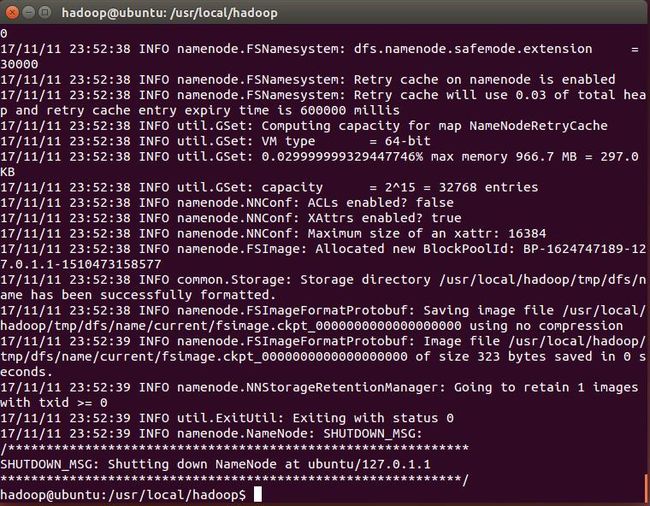
配置完成后,初始化Hadoop文件系统 hdfs:
./bin/hdfs namenode -format
运行成功效果如图:
启动 NameNode 和 DataNode:
./sbin/start-dfs.sh
运行成功效果如下图,可以通过 jps 命令查看 NameNode、DataNode 和 SecondNameNode 进程信息:

还可以通过 Web 方式查看 Hadoop 相关信息:
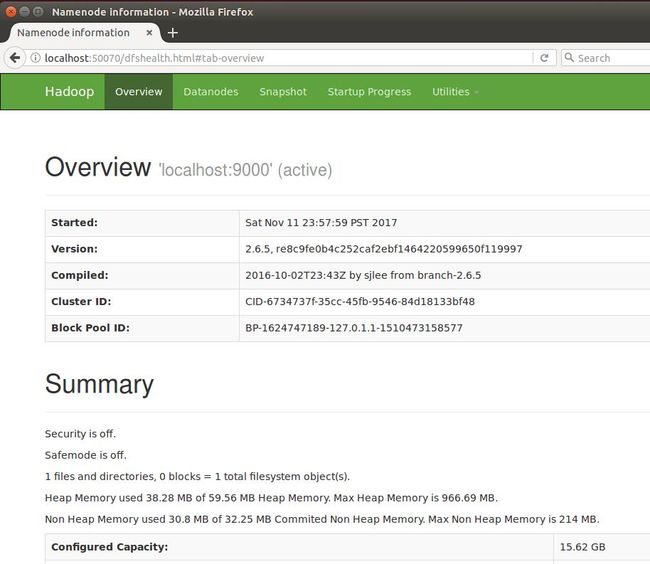
Hadoop伪分布式实例-WordCount
首先创建所需的目录,并把 /etc/hadoop 下文件上传到 input 目录下:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hadoop
bin/hdfs dfs -put etc/hadoop input

通过 web 方式可以看到文件已经上传成功:

同单机模式一样,运行 MapReduce 程序:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep input output 'dfs[a-z.]+'
注意:运行前若 output 目录已存在则会报错,可执行
bin/hdfs dfs -rm -R /user/hadoop/output删除该目录再重新运行
程序运行结束后再执行 bin/hdfs dfs -cat output/* 查看上述程序的输出结果,效果如图:

使用中可以体会到 bin/hdfs dfs -linux命令 就是分布式文件系统的命令,类似于在linux本机上操作,只不过前面加了 bin/hdfs dfs,比如还有:
bin/hdfs dfs -ls /user/hadoop # 查看 /user/hadoop 中的文件
bin/hdfs dfs -rm -R /user/hadoop/input/* # 删除 input 中的文件
bin/hdfs dfs -rm -R /user/hadoop/output # 删除 output 文件夹
停止 Hadoop
执行如下命令即可停止 Hadoop:
sbin/stop-dfs.sh
注意:下次再启动 Hadoop,无须再进行 hdfs 的初始化,只需要运行
sbin/start-dfs.sh即可