
数据分析指北 - 实例示范( 泰坦尼克沉船数据分析之二)
决策树了解下?也许它应该是你熟练掌握的第一个机器学习算法。
前期回顾:
泰坦尼克沉船数据分析之一)
其余相关:
基础( KNIME 基础模块之一 )
附录二 KNIME 使用基本介绍

微信公众号:数据分析指北
- 机器学习模型
- 决策树
- KNIME 中的决策树模块
- 决策树
好,我们已经对泰坦尼克沉船数据有了一个基本的了解,下一步我们将使用机器学习中的一个简单算法建立模型。看看能否通过模型预测一个人是否最终存活下来,并与事实进行对比。
机器学习模型
决策树
Decision Tree,决策树是一种机器学习中很常见的算法。它的目的是从特征中学习得到一个树形规则,并根据最终规则来预测目标变量的值。
在维基百科决策树的词条中有这样一个例子,小王是一个高尔夫球场的老板,他被雇多少临时工这件事搞的很心烦。如果来高尔夫球场的客户多,他就会需要更多的员工来服务客户;但是如果他雇佣了很多的员工,那天来的客户却不够多,那么他又得给这些人付工资。他观察到来高尔夫球场的客户和天气关系很大,于是就记录了天气状况与球场客户的数量,并找了专业人员构建了一个决策树模型,来帮助他决策今天要不要雇佣更多的临时工。最终他得到的模型是这样的:
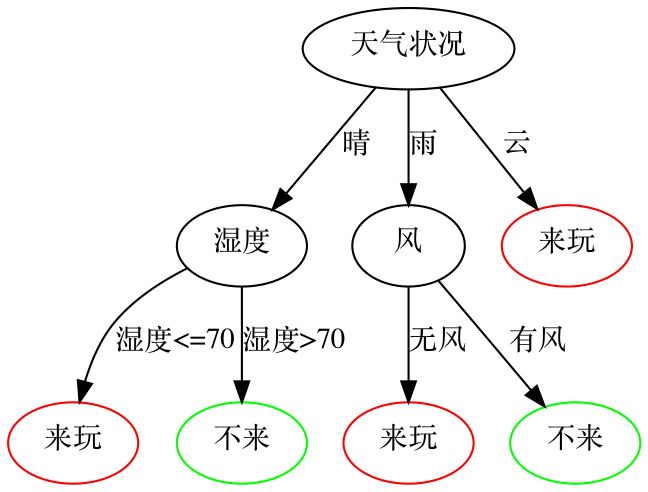
在这个模型的指导下,小王就可以在很多客人要来时,多雇佣一些临时工,反之亦然。
决策树模型有一些明显的优点和缺点,优点包括:
- 可解释性。可以看出上面的模型非常容易观察和解释,这是一个很大的优势,现今流行的深度学习模型在可解释性上就要比一些传统的模型差很多。
- 训练需要的数据少,等等。
缺点有: - 模型很可能会过拟合,导致泛化性能差。当然现今有一些剪枝算法已经可以在一定程度上解决这个问题了。
- 模型可能是不稳定的,原始数据稍微有变化就可能导致产生一棵完全不同的树模型。一般通过决策树的集成来缓解这个问题。
拟合、过拟合、以及泛化性能这些概念,是机器学习中重要而且基础的概念。在这里简单举例说明,假设我们有部分数据,想通过这些数据构建一个函数(模型),数据在下图中以橘黄色点表示,那么你可能会构造出多种多样的模型,比如,构造出左边的一次函数 \( y=ax+b \), 或是构造出中间的二次函数 \(y=ax^2+bx+c\) 或是构造出最右边的三次函数 \(y=ax3+bx2+cx+d\)。

那么究竟哪个函数更符合需求呢?这一般要看具体情况。在没有其他信息的情况下,单从上面的图来看,我们简单认为最左边的图是 underfitting(中文一般翻译为欠拟合的),中间是正好的情况,最右边的是 overfitting(过拟合)的情况。对比使用最左边图中的一次函数模型给所有的点建模的情况,中间的二次函数建立的模型误差要更小。但对于最右边的模型来说,虽然它的总体误差要比中间的模型更小(因为它的曲线离所有点的距离都要比中间模型离所有点的距离近),但一般假设我们手头只有一部分数据,且这部分数据可能含有噪声,所以这个模型在所有数据的集合(包括我们没有采集到的数据)上总体误差要差一些,这个只通过了每一个现有的点的模型是一个过拟合的模型。对现有可见数据拟合程度较高,但扩展到未知数据时,拟合误差较高,这种情况我们就称这个模型泛化能力不够。泛化能力的英文称为 Generalization, 泛化性能强不强从英文意译过来其实就是指这个模型的通用性强不强。
有可能聪明的你会问,为什么不能认为中间和左边的模型都是 underfitting, 而最右边的模型是 Balanced 的呢?
如果能想到这个问题,那么恭喜你,我觉得你有非常优秀的批判性思维。没错,上面本来就是一个糊里糊涂的解释,因为如果你要了解一个模型究竟是过拟合、欠拟合还是刚刚好,你不仅需要知道一些具体的情况以及数据来源方面的专业知识(domain knowledge),你还要把所有数据分割成训练集、测试集两组(甚至还会有开发集,三组),然后分别在训练集中构建模型,在测试集中验证模型,最后选出刚刚好的模型。
如果你没有问出这个问题,那么也没有关系,因为你经过学习、训练,这些概念迟早会成为你日常工作生活中的一部分 =P。
上面是一个简单拟合、过拟合举例。对于我们上面所讲的决策树这个模型来说,它非常容易过拟合,例如:
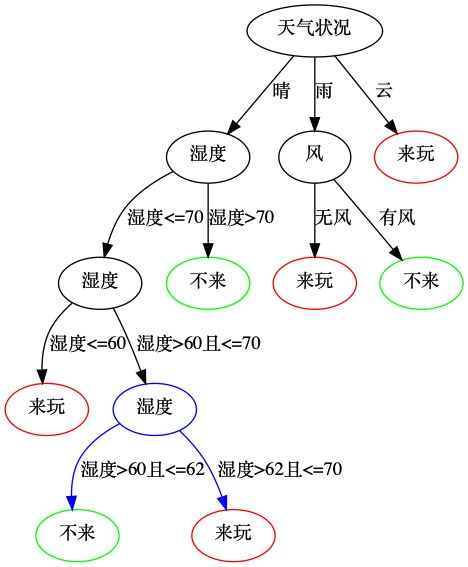
其中需要注意的点是,如果这天天气预报是晴,湿度是62,那么在前面的模型中,预测结果是有很多人会来玩;而在现在这个模型中,得到的预测结果是很少人来玩,后面这个模型在逻辑上可以认为是过拟合了。这个过拟合模型的产生有可能非常简单,比如,小王收集的数据里面,就有62,大家都没人来玩的情况,而这个数据,有可能只是因为这一天是春节,大家都在家和家人团聚这种特殊情况。当然,这种问题也许可以通过收集更多的数据来解决--发现只有偶尔几次湿度是62的情况没什么人来,在大多数情况下大家都是来的;有时这种问题是不能解决的--在某些情况下收集更多数据很困难。
在生活中,有时你会反思,对于一些事情,你想的过于复杂,这种情况就可以理解为 overfitting 了。孔子的学生子贡曾问孔子,子张和子夏哪个人更贤明?孔子回答,子张常常超过周礼的要求,而子夏常常达不到周礼的要求。子贡说,那是不是说超过周礼要求的子张更贤明一些呢?孔子答,过犹不及。其实也是同样的意思,underfiting 与 overfitting 都是效果一样,不合格的。
因为决策树模型非常容易过拟合,所以对于初步构建好的决策树来说,剪枝(意如其名)算法对于它是非常重要的步骤。咦,不对,我们不是还没说如何构建决策树吗?没错,主要原因是这部分知识相对比较简单,只需要搞清楚 基尼不纯度 或 information gain 信息增益就基本可以了。
至于剪枝(Pruning),有前剪枝和后剪枝两类。前剪枝就是在树的构建时设定一个阈值,比如树的深度,如果树的深度超过了某一个值,我们就不再对此节点进行划分;后剪枝中的MDL(minimum description length)是 KNIME 的 decision tree 模块中可以选择的方法。
KNIME 中的决策树模块
KNIME的机器学习模块一般都分为两个部分,一部分是 XXXX Learner,一部分是 XXXX Predictor,Learner 学习到模型之后,把模型和测试数据再塞给 Predictor 就完成了一次学习与预测的过程。我们先来看 Decision Tree Learner。
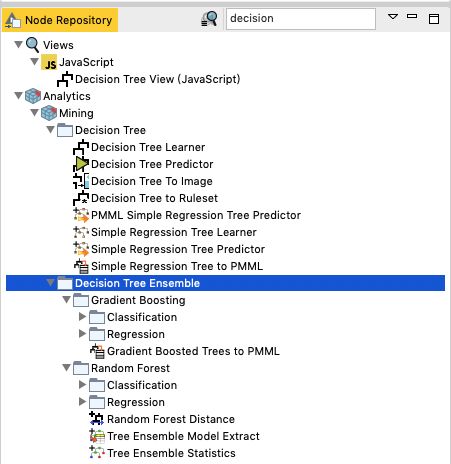
在 Node Repository 中搜索 decision 之后,我们看到了一系列和 Decision Tree 相关的模块,有一些是一望可知的模块,比如 Decision Tree View(JavaScript),Decision Tree To Image用于输出 Decision Tree 图形,而带 Regression 字样的模块都是做回归的(上面演示的Decision Tree都是做分类的,也可以用它做回归);还有一些都是 Ensemble 类型的算法,所谓 Ensemble(集成)就是训练多个分类器,然后把这些分类器组合起来,达到更好的预测性能,简单来说就是,三个臭皮匠,顶一个诸葛亮。各种 Boosting 以及 Random Forest 都属于集成学习的范畴,集成学习因为是多个分类器的组合,不容易过拟合,所以泛化性能相对来说就强一些,但由于是多个分类器的组合,所以在模型的可解释性方面要稍微弱一些。我们今天的主角 Decision Tree Learner 的配置如下:
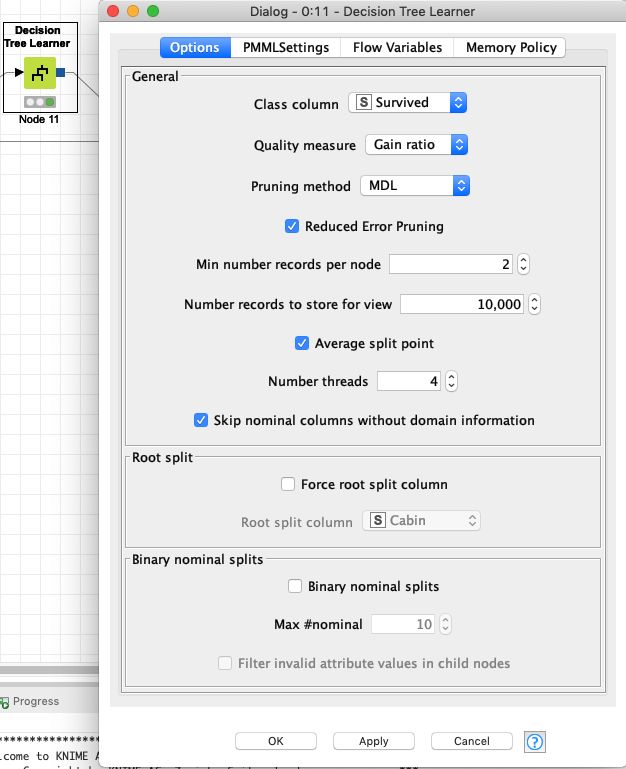
通过其中 Class column 选出模型需要预测的列,Quality Measure 选择 基尼不纯度 或是 熵 都可以,这两者可以近似替代,我倾向于使用度量信息量的熵,Pruning method选择剪枝算法,MDL或是No Pruning(不选剪枝,不推荐),其余的,默认选项即可。
配置完成之后,即可对测试集数据进行训练,右键节点选择View: Decision Tree View获得如下决策树。

对于泰坦尼克沉船数据来说,在我们的简单配置下,学习得到的 Decision Tree 结果和上面预测打高尔夫球的决策树并没有什么不同,只是多了一些更详细的说明。从第一个根节点往下,首先判断的是 Sex,如果是 male 男性,那么直接预测他死亡(0),如果是 female 女性,先预测她活着,然后根据 SibSp (同在船上的兄妹及配偶的数量)以及 Parch(同在船上的父母或子女的数量)来进一步预测这个人的生存情况。但从逻辑上来看,生存与否的确和性别以及亲属的数量相关,模块学习得到的结果是符合预期的,也没有观察到过拟合的 Decision Tree 节点,所以这个粗糙的模型我们是认可的,可以做为其他机器学习方法的一个基准。我们现在还没有在另外的数据集上验证这个模型,但却已经认可了这个基准模型,这种情况是不多见的,这是可解释性模型的一个优点。

让我们再仔细观察Decision Tree中的一个具体节点,来了解节点中的数据。其中0(320/397)代表了这个节点预测结果为0(死亡),落入这个节点的数据一共有397人,其中320人符合我们的模型预期。节点中部的 Table 部分描述了符合节点预测以及不符合节点预测的具体数据以及比例,节点下部的 Chart部分,以可视化的形式,描述了同样的数据。值得注意的是,因为在整个 workflow 中,在上游节点我们使用了 Color Manager 对数据进行标记(生存1标记为绿色,死亡0标记为红色),所以这里的可视化会非常的清晰明了。
我们接下来看一下这个模型在测试集上的效果。接入 Decision Tree Predictor 与 Scorer 模块,如下图所示:
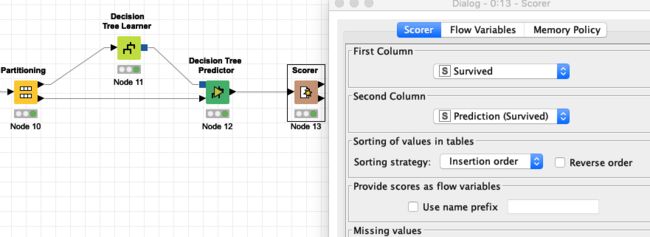
在数据进入 Decision Tree Learner 和 Decision Tree Predictor 之前,有一个叫做 Partitioning 的模块,这个模块是用来分割原始数据集的,我们把其中的一部分数据(通常称为训练集,大约占总数据百分之七十)送给 Learner 模块,把另外的一部分数据(通常称为测试集,大约占总数据百分之三十)送给 Predictor 模块,最后接入 Scorer 模块来考察模型在测试集上的表现。图中最右边是 Scorer 节点的模块配置。
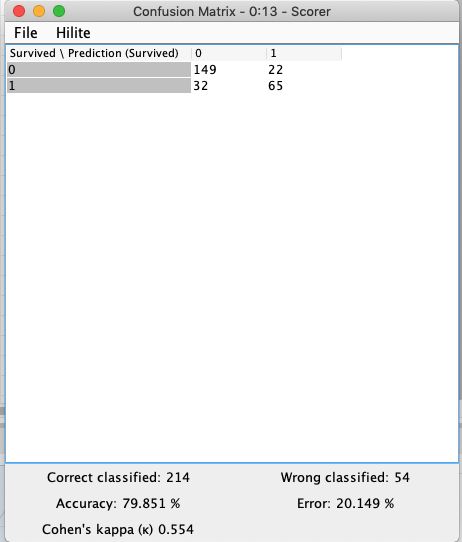
当运行完整个 Workflow 之后,我们右键 Scorer 模块,选择 View: Confusion Matrix,得到上面的评价结果。因为这是一个分类问题的模型,所以有实际为1预测为1、实际为1预测为0、实际为0预测为1、实际为0预测为0,这四种情况,将四种情况的数据按照矩阵列写就称为 Confusion Matrix。对于泰坦尼克这个具体问题来说,1和0的地位是平等的,所以只看左下角的 Accuracy (准确率)结果就可以。但对于某些问题来说,1和0的地位是不平等的,比如在癌症预测时,预测为癌症(假设为1)与没有癌症(假设为0)这两种预测结果来说,人的承受能力是不一样的,如果实际这个人没有癌症,但预测为有癌症,那么这个误诊不是那么严重,但如果实际这个人有癌症,但预测为没有癌症,耽误了最佳诊疗时间,那么这个误诊就比较严重了。在这种时候,看这个模型的准确率是没有太大意义的,需要另外设计其他指标进行模型评价。
我们没有做任何事情,只是把 Decision Tree 这么一摆,在自己划分的测试集上就获得了 79.8% 的准确率,如果原始问题是一个值得深入的问题,那么这个准确率就是我们接下来工作的 Baseline。要么用更高级的算法,要么收集数据,要么调整现有模型参数,这就是另外的话题了。
对于之前所说的 Kaggle 入门比赛来说,你需要把真正的测试集(而不是我们在这里划分的测试集)下载下来,然后将预测结果输出成 CSV,并上传到 Kaggle 网站上看你的最终结果。这部分作业,有兴趣的话,自己做咯。
至此,我们通过泰坦尼克沉船数据,已经从分析到预测走了一整个流程,也希望你能够静下心来自己做做看。
另外,虽然我们在整个过程中用的机器学习算法不是很 fancy, 也不够 state-of-the-art,但决策树这个模型,绝对值得成为你机器学习工具箱中的第一把有力工具。
如果想要实验一下泰坦尼克沉船数据的决策树例子,请关注公众号"数据分析指北",回复"作业"获取下载链接。
回头聊
给赞是支持,转发是更大的支持
