python学习
dir()
这些方法不用全记,可以用dir查看所有的操作方法
print(dir(''))
#['__add__', '__class__', '__contains__', '__delattr__', '__dir__', ............
print(dir([]))
#['__add__', '__class__', '__contains__', '__delattr__'...........
字符串的操作
字符串是不可变的,操作实际上是创建新的字符串并引用
.replace()
用给定字符串替换字符串中的部分字符.find()
查找.如果包含子字符串返回开始的索引值,否则返回-1。.Index()
查找.如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。.count(x, __start, __end)
查找出现的次数
print("hello world".count('o'))
#2
print("hello world".count('o',2,6))
#1
- .split()
(字符串分割,切片) - .capitalize()
(字符串第一个字母大写) - .title()
字符串每一个单词首字母大写(按空格来划分单词) - .startswith()
是否以给定字符开头,返回布尔值 - .endswith()
是否以给定字符串结尾,(返回布尔值) - .upper()
把字符串所有变为大写 - .lower()
把字符串所有变为小写 - .rjust(width,fillchar)
返回一个字符串右对齐,长度变为width,并用fillchar(默认为空格)填充.fillchar必须是一个字符,否则会报错:TypeError: The fill character must be exactly one character long
name='hello world'
print(name.rjust(31,'o'))
print(name.rjust(31,'oo'))
#输出结果为
#oooooooooooooooooooohello world
#error
.ljust()
字符串左对齐,长度变为width,并用fillchar(默认为空格)填充.fillchar必须是一个字符,否则会报错:TypeError: The fill character must be exactly one character long.center()
字符串居中,长度为width,用fillchar填充.
print('hello world'.center(31,'o'))
#输出:oooooooooohello worldoooooooooo
- .lstrip(chars)
清楚字符串左边的chars(默认为空格)
print('oooooooohello o'.lstrip('o'))
#输出:hello o
- .rstrip(chars)
清楚字符串右边的chars(默认为空格) - .strip(chars)
清楚字符串两端的chars(默认为空格)
print(' hello '.lstrip())
#输出:hello
- .rfind()
- .lfind()
- .rindex()
- .lindex()
- .partition(sep)
从左边第一个sep,把字符串分割为三部分,返回元组.(sep前,sep,sep后)
print(' hello world ooo'.partition('o'))
#输出:(' hell', 'o', ' world ooo')
- .rpartition()
从右边第一个sep,把字符串分割为三部分,返回元组.(sep前,sep,sep后)
print(' hello world ooo'.rpartition('o'))
#输出:(' hello world oo', 'o', '')
- .splitlines()
按照行分割,返回一个包含各行作为元素的列表.
print(' hello wor\nld \nooo'.splitlines())
#输出:[' hello wor', 'ld ', 'ooo']
- .isalpha()
判断字符串是否都是由字符组成的(空格,数字,转义字符都不行)返回布尔值.
print('hellow\norlooo'.isalpha())
print('hellow orlooo'.isalpha())
print('hellow2orlooo'.isalpha())
#输出:False
#False
#False
- .isdigit()
判断是否只是数字
print('156156'.isdigit())
#True
- .isalnum()
判断是否只由数字或字母组成
print('hel low2orlooo'.isalnum())
#False
print('hellow2orlooo'.isalnum())
#True
- .isspace()
判断是否只由空格组成
print(' '.isspace())
#True
- .join()
链接为字符串.可以用给定字符分割.
list=['my','name','is','xtf']
print('/'.join(list))
#my/name/is/XTF
print(' '.join(list))
#my name is XTF
其他tips
- "'\t"是tab的转义字符,是四个空格
List 列表 增,删,改,查
列表可以储存不同类型的数据
- 列表访问不能越界,不论是正向还是反向
list=['a','b',2]
print(list[2])
#2
list=['a','b',2]
print(list[5])
#IndexError: list index out of range
list=['a','b',2]
print(list[-1])
#2
list=['a','b',2]
print(list[-5])
#IndexError: list index out of range
增
- .append()
在列表后插入 - .insert(index,object)
在指定位置index前入元素object
list=['a','b',2]
list.insert(2,10)
print(list)
#['a', 'b', 10, 2]
- extend(interale)
list=['a','b',2]
list2=['c','d']
print(list)
list.extend(list2)
print(list)
#['a', 'b', 10, 2]
#'a', 'b', 10, 2, 'c', 'd']
改
- 直接修改
list=['a','b',2]
list[2]='c'
print(list)
#['a', 'b', 'c']
查
- in 和 not in
查找是否存在列表里,返回布尔值
list=['a','b',2]
print('c' in list)
#False
print('c' not in list)
#True
- .index(object, start, stop)
查找object,并返回第一个object的位置.区域为start 到 stop,左闭右开.
list=['a','b',2]
print(list.index(2,0,2))
#ValueError: '2' is not in list
list=['a','b',2]
print(list.index(2,0,3))
#2
删
- del
根据下标进行删除
list=['a','b',2]
del list[2]
print(list)
#['a', 'b']
- .pop()
删除最后一个元素
list=['a','b',2]
print(type(list.pop()))
print(list.pop())
print(list)
#
#b
#['a']
- .remove()
根据元素的值进行删除
list=['a','b',2]
list.remove('b')
print(list)
#['a', 2]
随机数
- randint() 左闭右闭的
随机整数
from random import randint
num=randint(-10,10)
print(num)
- 增强可读性
for 循环中的变量用 _ 来写,表示在循环中没有用到这个变量.
num_list=[]
for _ in range(10):
num_list.append(randint(1,20))
print(num_list)
- .sort()
对原列表进行排序
num_list=[]
for _ in range(10):
num_list.append(randint(1,20))
num_list.sort()
print(num_list)
num_list.sort(reverse=True)
print(num_list)
#[1, 1, 3, 6, 9, 11, 11, 13, 14, 17]
#[17, 14, 13, 11, 11, 9, 6, 3, 1, 1]
- sorted()
排序
和.sort()的区别:- 返回新的列表,原来的没有改变.
- .sort()属于列表的的内置函数,而sorted()可以对所有可迭代对象进行排序
- .sort()是方法,sorted()不是
num_list=[]
for _ in range(10):
num_list.append(randint(1,20))
print(sorted(num_list))
#[4, 6, 6, 9, 12, 13, 14, 16, 20, 20]
- 列表的嵌套(二维数组)
list=[['a','b'],['c','d']]
print(list)
print(list[0])
print(list[0][0])
#[['a', 'b'], ['c', 'd']]
#['a', 'b']
#a
#print(list[0,1]) 不能这样写,numpy才这样写
- 列表推导式 重要
所谓的列表推导式,就是指轻量级的循环创建列表.列表推导式效率高.
list1=[]
for i in range(10):
list1.append(i)
print(list1)
#列表推导式
list2=[i for i in range(10)]
print(list2)
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
生成相同的内容
list1=[]
for _ in range(3):
list1.append('不给鲁班我就送')
print(list1)
#列表推导式
list2=['不给鲁班我就送' for _ in range(3)]
print(list2)
#['不给鲁班我就送', '不给鲁班我就送', '不给鲁班我就送']
#['不给鲁班我就送', '不给鲁班我就送', '不给鲁班我就送']
列表推导式解析:
from random import randint
list=[randint(-10,10) for _ in range(10)]
print(list)
#选出大于0的数据
res=[]
for x in list:
if x>=0:
res.append(x)
print("用for循环筛选>=0:",res)
print('使用列表解析筛选:',[x for x in list if x>=0])
#用for循环筛选>=0: [3, 8, 4, 5, 0]
#使用列表解析筛选: [3, 8, 4, 5, 0]
number=[i for i in range(11)]
print(number)
print([x for x in number if x%2==0])
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
#[0, 2, 4, 6, 8, 10]
- 列表转化为字符串
my_list=['Welcom','to','ML','World']
print(' '.join(my_list))
print('/'.join(my_list))
#Welcom to ML World
#Welcom/to/ML/World
- 列表的乘法
获得一个列表,里面内容重复
list=['a','b','c',1,2,3]
print(list*3)
#['a', 'b', 'c', 1, 2, 3, 'a', 'b', 'c', 1, 2, 3, 'a', 'b', 'c', 1, 2, 3]
元组 tuple
不能修改,不能删除
- .index()
查找给定元素,返回下标值
a=(1,2,3,4,5)
print(a.index(3))
#2
- .count()
返回出现的次数
a=(1,2,3,4,5)
print(a.count(3))
#1
- 单个元素的元组是(222111,)
(2221122)不是元组,是数字
print(type((121222)),type((21212121,)))
#
- 改变元组
元组里边如果有list,实际上存的是list的地址,这个地址是没法改变的,但是list内容可以改变
a=(1,[2,3],9,0)
print(a)
a[1].append(4)
print(a)
#(1, [2, 3], 9, 0)
#(1, [2, 3, 4], 9, 0)
- zip()
将可迭代对象作为参数,将对象中对应的元素一一对应,转化为一些元组,然后返回这些元组对象的内存位置,如要显示可用list()转化.如果长度不一致,则长度与最短的相同
a=(1,2,3,4,5)
b=('a','b','c')
print(list(zip(a,b)))
#[(1, 'a'), (2, 'b'), (3, 'c')]
a=[1,2,3,4,5]
b=['a','b','c']
print(list(zip(a,b)))
#[(1, 'a'), (2, 'b'), (3, 'c')]
- 同时迭代多个对象
a=[1,2,3]
b=[1,2,3]
c=[1,2,3]
for i,j,k in a,b,c:
print(i+j+k)
#6
#6
#6
a=[1,2,3,4]
b=[1,2,3]
c=[1,2,3]
for i,j,k in a,b,c:
print(i+j+k)
#ValueError: too many values to unpack (expected 3)
字典
*** key和value的键值对***
- 获取key对应的值
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
print(info["name"])
#刘强东
- .get()
当不确定字典中是否存在某个key时,可以用.get().不存在的时候返回None或给定的默认值.
不存在的话返回None
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
print(info.get("mail"))
#None
可以给定默认值,若key不存在,返回默认值
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
print(info.get("mail","jingdong.com"))
#jingdong.com
print(info.get("age",25))
#25
- 值的更改
直接赋值就可以
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
info['name']="马云"
print(info["name"])
#马云
- 添加
直接赋值就可以
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
info['sex']="male"
print(info,'\n',info["sex"])
#{'name': '刘强东', 'age': 45, 'id': 123456789, 'addr': '北京', 'sex': 'male'}
# male
- 删除
- del
根据键值删除
- del
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
del info["name"]
print(info)
#{'age': 45, 'id': 123456789, 'addr': '北京'}
- 清除
删除整个字典
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
del info
print(info)
#NameError: name 'info' is not defined
- clear()
删除字典内部数据,留下空字典
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
info.clear()
print(info)
#{}
clear此方法返回None
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
print(info.clear())
#None
- len()
字典的长度(键值对的个数)
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
print(len(info))
#4
- .keys()
返回所有的key
返回的不是list,但可迭代,可用list()转换
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
print(info.keys())
#dict_keys(['name', 'age', 'id', 'addr'])
print(type(info.keys()))
#
print((list(info.keys())))
#['name', 'age', 'id', 'addr']
- .values()
返回所有的value
返回的不是list,但可迭代,可用list()转换
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
print(info.values())
#dict_values(['刘强东', 45, 123456789, '北京'])
- .items()
返回(key,value)
返回的不是list,但可迭代,可用list()转换
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
print(info.items())
#dict_items([('name', '刘强东'), ('age', 45), ('id', 123456789), ('addr', '北京')])
- 遍历整个字典
遍历整个字典的key和value
info={'name': "刘强东",'age': 45,'id':123456789,'addr':'北京'}
for key,value in info.items():
print(key,"=====>",value)
#name =====> 刘强东
#age =====> 45
#id =====> 123456789
#addr =====> 北京
把字典转化为list
转化为list时会将key和value变为元组,然后变为list字典的解析
#创建一个班级的分数
from random import randint
grades={'student{}'.format(i): randint(50,100) for i in range(1,5)}
print(grades)
#筛选出高于90分的人
d={k:v for k,v in grades.items() if v>=90}
print(d)
#{'student1': 56, 'student2': 60, 'student3': 97, 'student4': 73}
#{'student3': 97}
集合
无序,元素是唯一的
里面不能放list或set或dic等
显示时为有序,实际为无序
常用于去重
- set 集合
set1={1,4,2,7,5,1}
print(type(set1))
#
添加
- .add()
添加元素
set1={1,4,2,7,5}
set1.add(8)
print(set1)
#{1, 2, 4, 5, 7, 8}
删除
- .remove()
删除给定,不存在的话报错
set1={1,4,2,7,5,1}
set1.remove(1)
print(set1)
#{2, 4, 5, 7}
- .pop()
随机删除元素,若集合为空,则报错
set1={1,4,2,7,5,1}
set1.pop()
print(set1)
#{2, 4, 5, 7}
- .discard()
如果存在给定值,则删除,若不存在,则不做任何操作.
set1={1,4,2,7,5,1}
set1.discard(2)
print(set1)
set1.discard(3)
print(set1)
#{1, 4, 5, 7}
#{1, 4, 5, 7}
- .update()
- 集合的解析
set1={randint(0,20) for _ in range(10)}
print(set1)
res={ x for x in set1 if x%3==0}
print(res)
函数
- 格式
def 函数名(参数):
pass
def sumNum(start,end):
res=0
for i in range(start,end+1):
res+=i
return res
res=sumNum(1,100)
print(res)
#5050
- 函数解释
在定义函数后输入三个引号,会自动生成参数和结果让我来解释.在后面用到函数的时候按ctrl并鼠标放在函数上,会显示函数的说明.
def sumNum(start,end):
"""
计算start到end的累加和
:param start: 开始值
:param end: 结束值
:return: 累加和
"""
res=0
for i in range(start,end+1):
res+=i
return res
res=sumNum(1,100)
print(res)
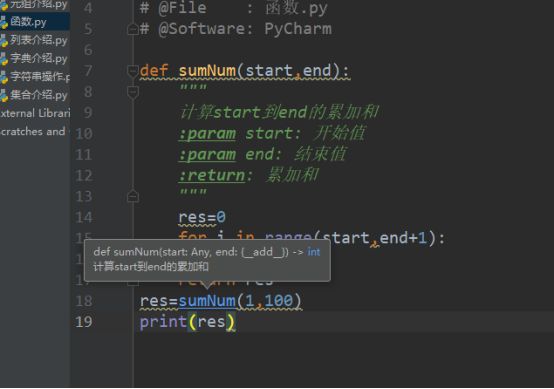
image.png
- doc 是函数的注释
def ff(a):
"""
打印test
:param a: 随意
:return: 5
"""
a=3
return 5
print(ff.__doc__)
# 打印test
# :param a: 随意
# :return: 5