本次实践方案:通过分析朝阳医院2016年销售数据,并通过R语言的处理,最终输出朝阳医院“月均消费次数”、“月均消费金额”、“客单价”、“消费趋势”等结果和可视化图形。
第一步、读取数据
导入 Excel 数据。使用函数read.xlsx() 导入一个工作表到一个数据框中。一般格式为 read.xlsx(file, n)。具体代码如下:
library(xlsx)
readFilepPath<-"E:/猴子大数据分析课程/朝阳医院2016年销售数据.xlsx"
excelData<-read.xlsx(readFilepPath,"Sheet1",encoding="UTF-8")
excelData
又或者
library(openxlsx)
readFilepPath<-"E:/猴子大数据分析课程/朝阳医院2016年销售数据.xlsx"
excelData<-read.xlsx(readFilepPath,"Sheet1")
excelData
注意事项:一是确保安装了最新的java,并且进行了必要的配置。
[win10环境下如何配置java环境变量]( http://jingyan.baidu.com/article/02027811629b941bcc9ce521.html)
二是确保已经安装了“xlsx”包或者“openxlsx”包。使用第一种方式时,若是没有encoding="UTF-8"可能会出现乱码。"Sheet1"也可以用1代替。
三是确保读取路径的正确,并且是使用正斜杠“/”,而不是反斜杠“\”。
第二步,对数据进行预处理
删除所有含有缺失数据的行。
第四章4.5.2中讲到如何在分析中排除缺失值的方法。使用na.omit()函数可以删除所有含有缺失数据的行。本例采用的是!is.na来进行保留未缺失数据的行。代码如下:
excelData<-excelData[!is.na(excelData$购药时间),] #保留未缺失时间的数据
excelData #输出结果

第三步、进行列名重命名工作
使用fix(excelData)调出交互式编辑器进行修改名称即可。

或者使用names()函数来重命名变量。
names(excelData)<-c("time","carNo","drugID","drugName","saleNmuber",
"virtualMoney","actualMoney") #对原数据标题行进行重命名
excelData #输出重命名后的数据

第四步、处理日期列
- 1.目的是把年月日和星期分开,并删除星期,只保留日期即可,便于进行样本分析。
采用R语言中的字符串处理包stringr中的str_split_fixed()来实现。
library(stringr) #载入字符串处理包
timeSplit<-str_split_fixed(excelData$time," ",n=2) #将time列分成两列日期和星期
excelData$time<-timeSplit[,1] #time列选取第一列即日期列
excelData #输出最新的数据

- 2.然后将time数据从字符类型转换为时间格式数据。
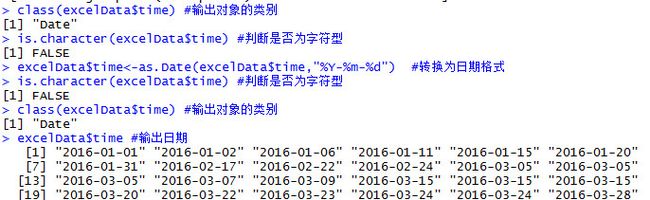
class(excelData$time) #输出对象的类别
is.character(excelData$time) #判断是否为字符型
excelData$time<-as.Date(excelData$time,"%Y-%m-%d") #转换为日期格式
is.character(excelData$time) #判断是否为字符型
class(excelData$time) #输出对象的类别
excelData$time #输出日期
第五步、对saleNumber、virtualMoney、actualMoney进行类型转换。
# 销售数量
excelData$saleNmuber<-as.numeric(excelData$saleNmuber)
# 应收金额
excelData$virtualMoney<-as.numeric(excelData$virtualMoney)
# 实收金额
excelData$actualMoney<-as.numeric(excelData$actualMoney)
第六步、排序
可以使用order()函数对一个数据框进行排序,按照销售时间对数据进行降序排序。
# 按照销售时间降序进行排序
excelData<-excelData[order(excelData$time,decreasing = FALSE),]
excelData

或者这样处理也是可以的
attach(excelData)#excelData作为一个数据框进行处理,先进行绑定
excelData<-excelData[order(excelData$time,decreasing = FALSE),]#按照时间进行降序排列
detach(excelData)#解除绑定
excelData#输出降序排序后的数据
第七步、计算消费次数和月份数
同一天内同一个人发生的所有消费计算为一次消费行为,剔除重复的日期和医保卡号。
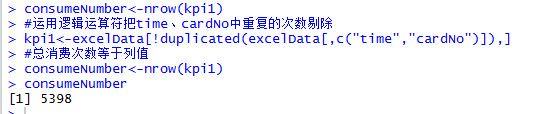
#运用逻辑运算符把time、cardNo中重复的次数剔除
kpi1<-excelData[!duplicated(excelData[,c("time","cardNo")]),]
#总消费次数等于列值
consumeNumber<-nrow(kpi1)
duplicated()函数作用是返回重复的元素和向量。
# 最小的时间值
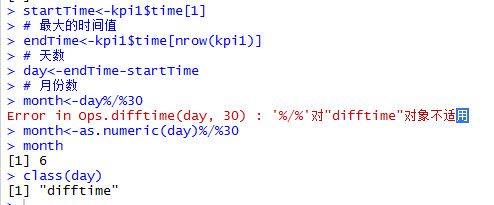
startTime<-kpi1$time[1]
# 最大的时间值
endTime<-kpi1$time[nrow(kpi1)]
# 天数
day<-endTime-startTime
# 月份数
month<-as.numeric(day)%/%30 #注意的是把day的格式转换为数字格式才可以进行整数除法。
X%/%Y表示X除以Y取整。
month #输出月份数
第八步、数据目标处理
- 业务指标1
计算月均消费次数=总消费次数/月份数。
月均消费次数
monthconsume<-consumeNumber/month
monthconsume
[1] 899.6667
monthconsume<-consumeNumber%/%month
monthconsume
[1] 899
class(consumeNumber)
[1] "integer"
class(day)
[1] "difftime"
class(month)
[1] "numeric"

- **业务指标2**
月均消费金额=总金额/月均消费次数
totalmoney<-sum(excelData$actualMoney,na.rm = TRUE)
monthmoney<-totalmoney/month
monthmoney
[1] 50771.71
(原结果为50776.38),尝试了两次结果都不对,还是要仔细仔细,少了28元。
- **业务指标3**
客单价=总消费金额/总消费次数,直接计算就可
pct<-totalmoney / consumeNumber
pct
[1] 56.43391
- **业务指标4**
消费趋势,计算每周消费金额。用到**tapply()**函数。
>tapply(X, INDEX, FUN = NULL, ...,),其中X一般为向量,INDEX为一个或多个因子的列表,每个因子的长度与X相同,FUN = NULL表示tapply返回一个向量,simplify = TRUE表示如果FUN总是返回一个标量,tapply返回一个具有标量模式的数组。
计算每周的消费金额
weekconsume<-tapply(excelData$actualMoney,format(excelData$time,"%Y-%U"),sum)
选择数据中的actualMoney列。其次用format()函数指定日期的格式(年-周数),
最后sum()函数进行求和。最后tapply返回一个数组。
weekconsume
2016-00 2016-01 2016-02 2016-03 2016-04 2016-05 2016-06 2016-07 2016-08
1972.80 9679.64 10979.01 8719.73 15662.30 18758.82 3665.70 8441.51 8453.57
2016-09 2016-10 2016-11 2016-12 2016-13 2016-14 2016-15 2016-16 2016-17
9988.98 8500.78 9869.16 10135.23 8426.46 11400.66 14408.21 10385.33 10265.98
2016-18 2016-19 2016-20 2016-21 2016-22 2016-23 2016-24 2016-25 2016-26
9496.06 9728.40 11794.11 11497.20 9530.38 10806.71 11877.43 14077.38 10894.90
2016-27 2016-28 2016-29
8386.97 13372.67 3454.18

上文中%U是用十进制表示一年当中的周数(week of the year as decimal number),using the first Sunday as day 1 of week 1。使用规则是用第一个星期天作为第一周的第一天(00-53)。感谢**小熊猫**的数据分析学习笔记。
**第九步、结果的输出和展示**
使用plot()函数进行绘图。
将数据存储到数据框中
weekconsume<-as.data.frame.table(weekconsume)
weekconsume
Var1 Freq
1 2016-00 1972.80
2 2016-01 9679.64
3 2016-02 10979.01
4 2016-03 8719.73
5 2016-04 15662.30
6 2016-05 18758.82
7 2016-06 3665.70
8 2016-07 8441.51
9 2016-08 8453.57
10 2016-09 9988.98
11 2016-10 8500.78
12 2016-11 9869.16
13 2016-12 10135.23
14 2016-13 8426.46
15 2016-14 11400.66
16 2016-15 14408.21
17 2016-16 10385.33
......
进行重命名
names(weekconsume)<-c("time","actualmoney")
weekconsume
time actualmoney
1 2016-00 1972.80
2 2016-01 9679.64
3 2016-02 10979.01
4 2016-03 8719.73
5 2016-04 15662.30
6 2016-05 18758.82
7 2016-06 3665.70
8 2016-07 8441.51
9 2016-08 8453.57
10 2016-09 9988.98
......
转换为字符型
weekconsume$time<-as.character(weekconsume$time)
class(weekconsume$time)
计算时间个数
weekconsume$timenumber<-c(1:nrow(weekconsume))
weekconsume$timenumber
绘制图形
plot(weekconsume$timenumber,weekconsume$actualmoney,
xlab ="时间(年份-第几周)",
ylab ="消费金额",
xaxt="n",
main="2016年朝阳医院消费曲线",
col="blue",
type="b")
定义坐标轴显示
axis(1,at=weekconsume$timenumber,labels = weekconsume$time,cex.axis=1.5)

####总结一下
通过学习R语言实战前四章,结合猴子的课程第三讲,并参考部分学员笔记,完成了整个分析的过程。**读取数据、数据预处理、数据的分析和数据结果输出和展示**。其中用到了xlsx/openxlsx(两个会相互影响),is.na(),stringr,order(),duplicated(),class()和plot()函数等,进行了数据重命名、拆分、数据格式转换、排序,以及求和、绘图显示等操作,过程中多处出现错误和不理解,经过多次的反复回头看,但依然存在不明白的地方,需要进一步的去学习和实践。