一、 实验目的
了解 weka 中 Explorer 的 Preprocess 相关功能。
二、 实验内容
进入 weka 中 Explorer 界面,打开 data 目录下 weather.numeric.arff 文件,了解 Preprocess 相关功能。

三、 实验过程
1. 了解 arff 格式
用记事本打开 weather.numeric.arff 文件,
@relation weather
@attribute outlook {sunny,overcast,rainy}
@attribute temperature numeric
@attribute humidity numeric
@attribute windy {TRUE,FALSE}
@attribute play {yes,no}
@data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
rainy,71,91,TRUE,no
显而易见,可以知道 arff 格式是这样组织数据的:
- (唯一)一个 ** @relation ** + 关系名称。
- 若干 ** @attribute ** + 属性名称 + 属性类型({}中写出枚举类型,以逗号隔开,表示离散型数据; numeric 表示连续型数据;还有 string 和 date 类型,顾名思义,就知道一个是字符串型,一个是日期型)。
- (唯一)一个 ** @data **占一行,后接若干具体数据(依照上面定义的属性顺序写出采样数据,以逗号隔开)。
- 另外,网上资料显示,** % ** 为 arff 格式下的注释标记。
2. 了解区域功能
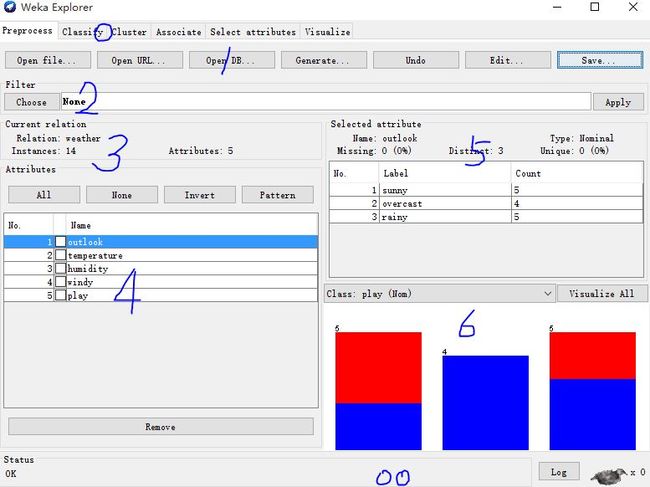
(0) 功能标签:用于数据预处理及针对数据进行的各种处理之间的切换。
(1) 编辑按钮:包括打开各种形式的数据集,生成数据集,撤销,编辑数据集和保存。
(2) 筛选器选择:对数据进行某种变换,比如离散化,二进制化。
(3) 当前信息:显示当前数据集的基本信息,包括关系名,属性个数,实例个数等。
(4) 属性信息:包括所有属性的显示和可以对它们进行的一些操作,比如移除一些无用属性,使数据集更简洁明了。
(5) 选中属性:显示当前选中的属性的摘要信息,比如名称、类型、数值等。
(6) 属性可视化:以直方图的形式显示当前选中属性,给人更直观的感受。
(00) 状态信息: 显示是否在进行数据挖掘,历史记录查看,内存使用信息等。
3. 举例操作
区域(0)和(00),在此实验中(学习 preprocess 的基本操作)基本是用不到的,这里也就不再多说了。
区域(1),前面已经使用过打开 arff 格式数据集功能;至于打开网络资源和数据库内容,现在还不太了解;生成功能,就是根据一定的规则(还不清楚这些规则的意义)生成一些随机数据;而撤销、编辑和保存,跟记事本也差不太多,亦不赘述。


- 区域(2)中的各个筛选器我还不了解,就做一下归一化(感觉这就是统计里的标准化),并拿 humidity 做一下无监督的离散化(这应该就是画直方图之类的东西时要做的工作吧)好了。

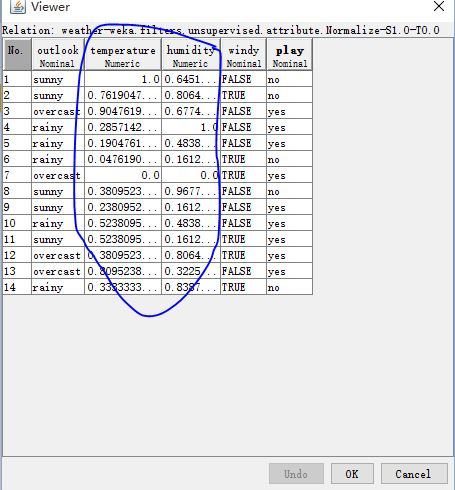



区域(3)显示当前数据集的信息,其实就是提取了 ** @relation ** 后面的字符串,统计了 ** @attribute ** 的个数和 ** @data ** 后的行数,没什么可说的。
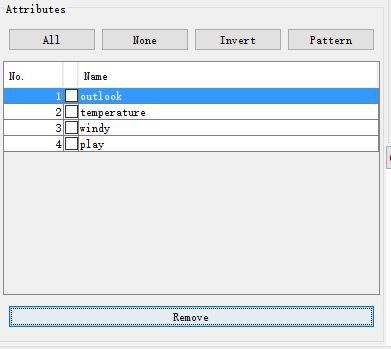
区域(4)是属性信息栏,可以移除一些无用数据,比如数据的序号、聚类分析时的类别标签;这里试了一下去除 humidity 属性,不过它并非无用信息,所以之后还得用下 undo 。
- 区域(5)用一些统计数据(对于离散和连续数据并不相同)概括地显示了当前选中属性的信息,刚才进行数据离散化时也有涉及。

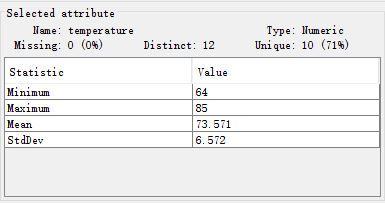
- 区域(6)是可视化区域,以直方图的形式进一步描述数据(和区域(5)相辅相成),给人较为直观的感受(或许利于启发式方法的使用?);在其上的颜色,是以某一属性为目标变量添加的。

以上,即为 weka 中 Explorer 的 Preprocess 界面的主要功能。