简述
再次进行分析抓取气象数据练习,本节主要抓取预报气象数据。抓取数据请勿存档,商用请联系官方。
爬取对象
抓取中央气象台城市预报数据
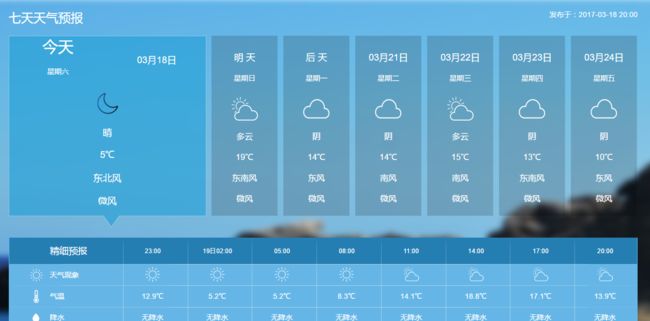
城市预报数据
使用包
import pymssql # MS Sql Server 操作
from bs4 import BeautifulSoup
import time, os
import requests
import datetime
实现步骤
1、抓取对象初步分析
- 通过
F12捕获页面内容,分析页面加载内容,得知目标对象主要分为两部分,点击后续预测某日,下方切换显示具体时刻。
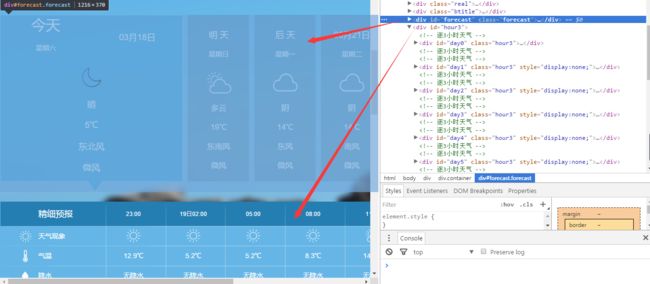
页面分析
- 分析总结主体抓取步骤如下
Start
1、download_page("http://www.nmc.cn/f/rest/province") # 请求所有直辖市、省列表 list x
2、download_page("http://www.nmc.cn/f/rest/province/x") # 请求 x 下所有城市列表 list y
3、download_page("http://www.nmc.cnpublish/forecast/zzz/z.html"),# 请求城市 z 页面内容,并从中过滤出目标对象
4、循环目标对象中每天详细预测数据,存储至数据库
End_定时重复上述步骤
- 因对预测全天数据中气象气温数据含义不了解,估放弃全天数据抓取,仅抓取预测时刻数据
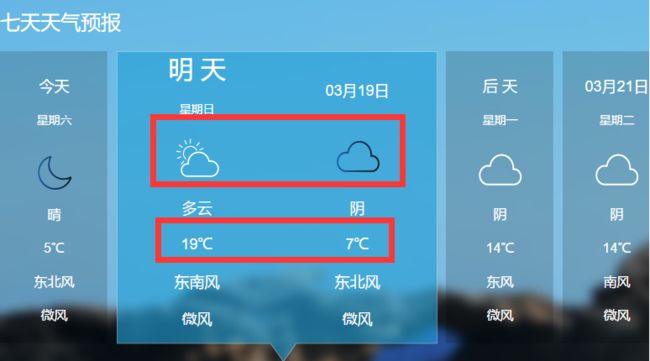
全天数据
2、抓取对象深入分析

预测时刻数据
- 分析总结后续需注意以下问题
1、数据以表格形式显示,列头为时刻(与常规数据存储习惯相反),后续读取数据需按列分组
2、所有数据第一列为说明,后续为 8 个时刻数据(间隔 3 小时);“今天”第一列为最近的时刻,后续所有日期数据第一列为 “08:00”,估涉及重复数据
3、预测时刻中“23:00”以后,涉及日期整体加一天
4、天气气象数据为图片,需转换为对应文字
3、问题对应实现伪代码
- 按时间分组获取数据
values_list = []
#定义不同的数据 list 保存每列数据,后续便于统一整合
value1_list = []
value2_list = []
......
for i,row_table in enumerate(day_html.find_all('div', attrs={'class': 'row'})):
for j,column_table in enumerate(row_table.find_all('div')):
if j == 1:
value1_list.append(text)
elif j == 2:
value2_list.append(text)
......
values_list.append(value1_list)
values_list.append(value2_list)
......
- 重复数据判断
sql="select count(id) from Space0009A where column_0='%s' and column_1='%s' and column_2='%s' " %(publish_city,publish_time,f_sj)
isRepeat = ms.ExecQuery(sql.encode('utf-8'))
if isRepeat[0][0] == 0:
sql = "insert into Space0009A values ('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s') " %(publish_city,publish_time,f_sj,f_tqxx,f_qw,f_js,f_fs,f_fx,f_qy,f_sd,f_yl,f_njd)
ms.ExecNonQuery(sql.encode('utf-8'))
- 预测时刻日期区分
days_html = soup.find_all('div', attrs={'class':'hour3'})
flag_date = int(day_html["id"].replace('day','')) #day0 、day1......
forecast_date = datetime.datetime.strptime(publish_time,"%Y-%m-%d %H:%M").date() + datetime.timedelta(flag_date) #获取预测日期
for i,row_table in enumerate(day_html.find_all('div', attrs={'class': 'row'})):
is_new_day = False
for j,column_table in enumerate(row_table.find_all('div')):
if i == 0:
if "日" in text:
text = str(forecast_date + datetime.timedelta(1)) +" "+ text.split('日')[1]
is_new_day = True
elif is_new_day:
text = str(forecast_date + datetime.timedelta(1)) + " " + text
else:
text = str(forecast_date) + " " + text
- 天气气象转换
def parse_html_forecast_code(html):
soup = BeautifulSoup(html, "html.parser")
#获取建立图标对应气象字典,因字典变化较少,抓取一次即可
icon_list_soup = soup.find('div', attrs={'class': 'forecast'}).find_all('div',attrs={'class': 'day'})
for icon in icon_list_soup:
icon_key = icon.find('img')["src"].split("/")[-1]
if (icon_key in icon_list) == False:
icon_list[icon_key] = icon.find('div', attrs={'class': 'wdesc'}).getText().strip()
print(icon_list)
总结
本轮示例主要实现 嵌套div 数据解析(目前嵌套list方案仍需改进),使用 in 关键字对 list 进行重复检查,利用 enumerate 获取循环下标等内容,至此完成气象预测数据抓取......
抓取日志示意
源码:
MSSql_SqlHelp
spider_www.nmc.cn_city_Forecast