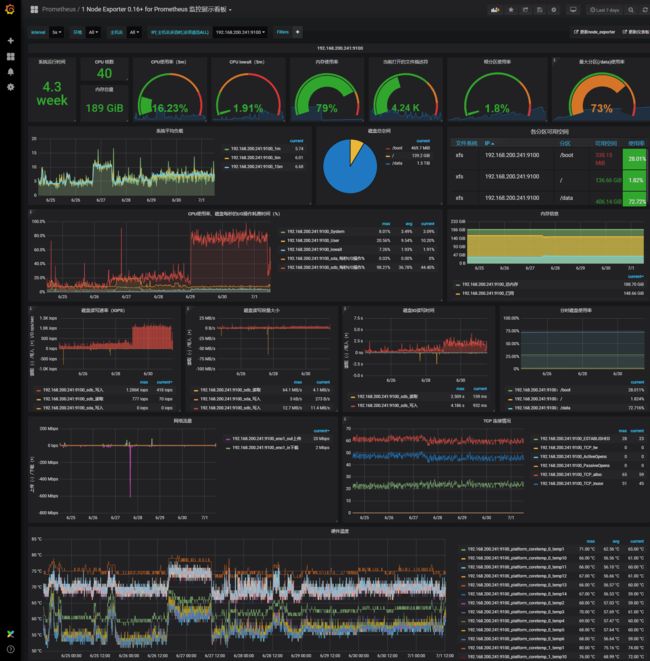
Prometheus Alertmanager Grafana 监控警报
#node-exporter, Linux系统信息采集组件
#prometheus , 抓取、储存监控数据,供查询指标
#alertmanager , 发送警报通知
#grafana , web图形展示#环境 centos7+docker
#单机模式,快速搭建测试环境
#安装node-exporter
#docker安装方式
docker rm -f node-exporter
docker run -d -p 9100:9100 \
--name node-exporter \
-h $(hostname) \
-v "/proc:/host/proc:ro" \
-v "/sys:/host/sys:ro" \
-v "/:/rootfs:ro" \
--net="host" \
--pid="host" \
--cap-add=SYS_TIME \
--cpus 0.1 \
--memory 32M \
--restart always \
prom/node-exporter \
--path.rootfs /rootfs \
--path.procfs /host/proc \
--path.sysfs /host/sys \
--collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
#非docker方式,正式环境推荐
#curl -s http://files.elven.vip/download/node_exporter.sh |bash
#默认端口9100 可浏览器访问查看文本数据 IP:9100/metrics#安装prometheus
##prometheus配置文件
# mkdir -p /data/prometheus/
# vi /data/prometheus/prometheus.yml
#prometheus.yml
global:
scrape_interval: 15s # 设定抓取数据的周期,默认为1min
evaluation_interval: 15s # 设定更新rules文件的周期,默认为1min
scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
# rule配置
rule_files:
- "/prometheus/rules.*yml"
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['localhost:9100']
##警告规则
# vi /data/prometheus/rules.linux.yml
#rules
groups:
- name: test-rules
rules:
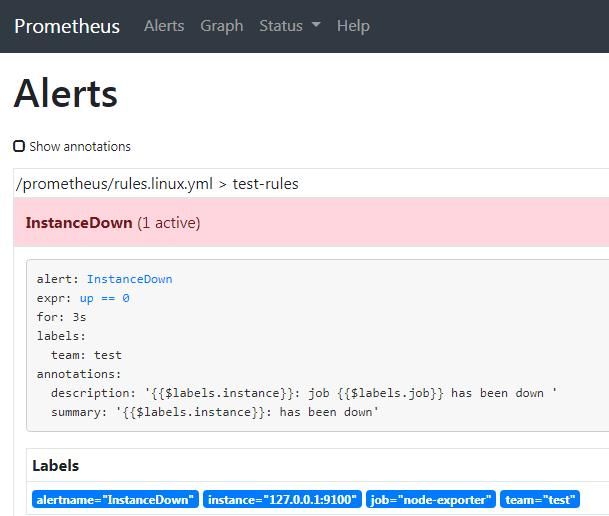
- alert: InstanceDown #告警名称
expr: up == 0 #告警判定条件
for: 3s #持续多久后,才发送
labels: #标签
team: test
annotations: ##警报信息
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: job {{$labels.job}} has been down "
#启动prometheus
docker rm -f prometheus
Dir=/data/prometheus
docker run -dit \
-u root --restart=always \
-h prometheus --name prometheus \
--net="host" \
-v /etc/localtime:/etc/localtime:ro \
-v $Dir:/prometheus \
-v $Dir/prometheus.yml:/etc/prometheus/prometheus.yml \
--cpus 0.5 --memory 1024M \
prom/prometheus --web.enable-lifecycle
#浏览器访问 IP:9090
#修改配置后 curl -X POST http://localhost:9090/-/reload
#安装alertmanager
#配置文件
# mkdir -p /data/prometheus/alertmanager
# vi /data/prometheus/alertmanager/alertmanager.yml
# 全局配置项
global:
resolve_timeout: 5m #超时,默认5min
#邮箱smtp服务
smtp_smarthost: 'smtp.qq.com:587'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxx密码'
smtp_hello: 'qq.com'
# 路由
route:
group_by: ['alertname'] # 报警分组依据
group_wait: 20s #组等待时间
group_interval: 20s # 发送前等待时间
repeat_interval: 10m #重复周期10分钟
receiver: 'email' # 默认警报接收者
# 警报接收者
receivers:
- name: 'email' # 警报名称
email_configs:
- to: '[email protected]' # 接收警报的email
#关于email、微信发送模板,后面单独讲
#启动alertmanager
docker rm -f alertmanager
Dir=/data/prometheus/alertmanager
docker run -dit \
-u root --restart=always \
-h alertmanager --name alertmanager \
--net="host" \
-v /etc/localtime:/etc/localtime:ro \
-v $Dir:/alertmanager \
-v $Dir/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
--cpus 0.2 --memory 128M \
prom/alertmanager
#浏览器访问 IP:9093#关闭node-exporter测试
# docker stop node-exporter
# netstat -lntp |grep 9100
#查看prometheus点击Alerts查看rules生效
#查看alertmanager是否收到,等待邮件通知……
#grafana
docker rm -f grafana
docker run -dit --name grafana \
-h grafana -u root \
--restart always \
--cpus 0.2 --memory 128M \
-v /etc/localtime:/etc/localtime:ro \
-v /data/grafana:/var/lib/grafana \
--net="host" \
grafana/grafana
# 浏览器访问 ip:3000 默认登录用户密码 admin
#添加数据源Add data sources选 Prometheus
#可以参考这个grafana模板
#https://grafana.com/grafana/dashboards/8919
#导入 左边+按钮 -> Import -> 8919 -> prometheus选择源 -> Import