介绍
越来越喜欢Facebook的东西了,虽然很久以来我一直是个Google产品及技术的忠实粉丝。但最近在AI框架上一直频繁去翻弄Pytorch/Caffe2,感觉其API及核心模块设计结构比Tensorflow更加清晰、易懂。
同时看到Facebook出的像ResNext这种分类网络比Google一直在捧的Inception v4/Inception Resnet v2等网络也要更为简单而高效。
本来始终都不能从Inception v4/Inception Resnet系列网络的复杂噩梦中解脱,但看过ResNeXt后,终于如释重负,恢复了自己一直以来的哲学信仰。这个世界的很多高深、有效的道理其实都可以有简单的方式去表达。
ResNeXt可以说是基于Resnet与Inception 'Split + Transfrom + Concat'而搞出的产物,结构简单、易懂又足够强大。在行业标志性的Imagenet 1k数据集上它取得了比Resnet/Inception/Inception-Resnet系列更佳的效果。
以下为构成ResNeXt网络的基本block单元。
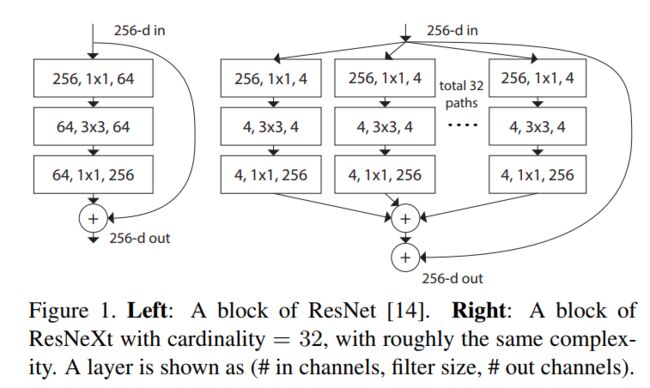
乍看上去它与Inception Resnet中所有的基本单元极为相似,可实际上它block当中的每个sub branch都是相同的,这是它与IR网络结构的本质区别,而正是基于这区别,我们可以使用Group convolution来对其进行良好实现。
ResNeXt
ResNeXt网络的整体结构
正如ResNet是由基本的Residual模块一个个累积起来的一样,ResNeXt网络也是由上图中所描述的模块一个个累积起来的。下面表格当中,我们能看到ResNeXt与ResNet网络的整体结构。
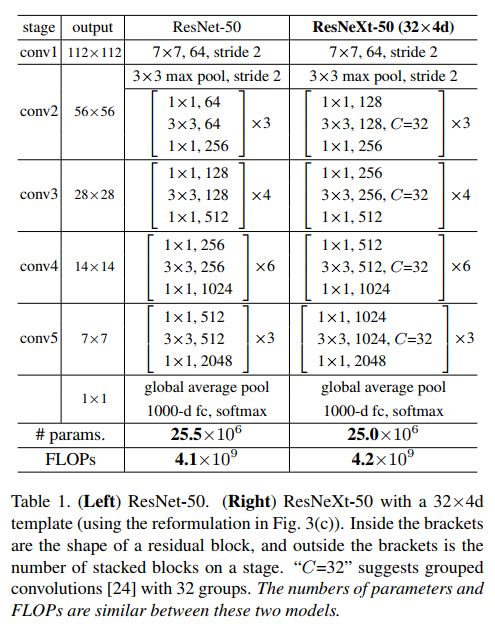
在这里它Follow了之前VGG/ResNet等网络中的一贯做法:一是如果一个block输出同样大小的chnnel size,那么blocks输入、输出有着相同的hyper-parameters(即width和filter sizes);二是若其输出与输入有着不同的大小(如downsampling操作),那么就需要相应地扩大filters的数目。
从上面表格里,亦能看出ResNeXt与ResNet一样都follow这样两条准则以保证每个block的计算量类似,所传递的信息也不会因层数递增而有太多丢失。
ResNeXt网络模块的变形
下面图中显示了三种ResNeXt网络模块的变形。它们在数学计算上是完全等价的,而第三种包含有Group convolution操作的正是最终ResNeXt网络所采用的操作。

ResNeXt网络的Capacity
一般增强一个CNN的表达能力有三种手段:一是增加网络层次即加深网络(目前CNN已经由最初Alexnet的不到十层增加到了成百上千层,而实际实验结果表明由层次提升而带来的边际准确率增加已是越来越少);二是增加网络模块宽度(可见我们之前有介绍过的Wide residual network,可宽度的增加必然会带来指数级的参数规模提升,因此它并非为主流CNN设计所认可。);
三是改善CNN网络结构设计(当然在不增加模型复杂度的情况下通过改良模型设计以来提升模型性能是最理想的做法,不过其门槛则实在是太高,不然Google/Facebook/Microsoft的那些埋头设计网络/调参的哥们儿就没办法拿那么高工资了。:))。
ResNeXt的做法可归为上面三种方法的第三种。它引入了新的用于构建CNN网络的模块,而此模块又非像过去看到的Inception module那么复杂,它更是提出了一个cardinatity的概念,用于作为模型复杂度的另外一个度量。Cardinatity指的是一个block中所具有的相同分支的数目。
作者进行了一系列对比实验,有力证明在保证相似计算复杂度及模型参数大小的前提下,提升cardinatity比提升height或width可取得更好的模型表达能力。
下图为反映Cardinatity增加对模型性能提升的实验结果。
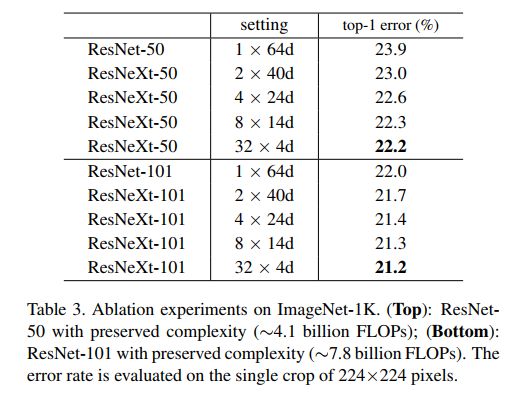
实验结果
ImageNet-1K
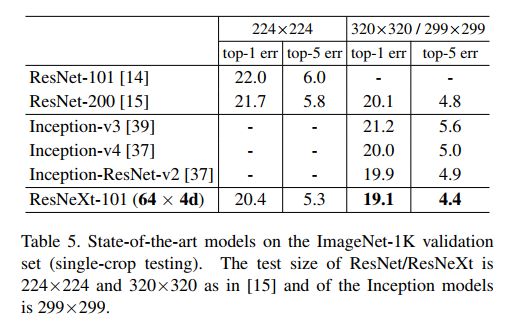
首先在标准的ImageNet-1K上进行了实验,并与其它state-of-art的模型进行了对比。

可以看出ResNeXt网络相对于ResNet网络可在training accuracy/val accuracy上都取得提升,但training accuracy上的提升显得更大。作者分析认为是因为ResNeXt的表达能力更强了,但此类结果改善却并非是因为Regularization的因素导致的。
为了减少可能的overfitting以来有效利用ResNext的表达能力,作者还试着在更大的ImageNet-5K上进行了实验。
下表为ResNeXt与更多CNN网络在ImageNet-1K上的结果比较。
ImageNet-5K
下面的图与表格中反映了ResNeXt与ResNet相比在更大的ImageNet-5K数据集上的优势。

代码分析
原文的代码是基于Torch来完成的,因为此Framework已经不再维护,所以在这里还是通过由Caffe所表达的结构来分析下此模型的组成。
下面是一个典型的ResNeXt网络模块,可以与之前的ResNet模块对比下,其主要的区别就是中间的3x3 conv transform层由direct conv变为了cardinatity为32的group conv。
layer {
name: "stage1_unit2_conv1"
type: "Convolution"
bottom: "stage1_unit1_plus"
top: "stage1_unit2_conv1"
convolution_param {
num_output: 128
kernel_size: 1
stride: 1
pad: 0
bias_term: false
}
}
layer {
name: "stage1_unit2_bn1"
type: "BatchNorm"
bottom: "stage1_unit2_conv1"
top: "stage1_unit2_conv1"
batch_norm_param {
use_global_stats: true
eps: 2e-5
}
}
layer {
name: "scale_stage1_unit2_bn1"
bottom: "stage1_unit2_conv1"
top: "stage1_unit2_conv1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
name: "stage1_unit2_relu1"
type: "ReLU"
bottom: "stage1_unit2_conv1"
top: "stage1_unit2_conv1"
}
layer {
name: "stage1_unit2_conv2"
type: "Convolution"
bottom: "stage1_unit2_conv1"
top: "stage1_unit2_conv2"
convolution_param {
num_output: 128
kernel_size: 3
stride: 1
group: 32
pad: 1
bias_term: false
}
}
layer {
name: "stage1_unit2_bn2"
type: "BatchNorm"
bottom: "stage1_unit2_conv2"
top: "stage1_unit2_conv2"
batch_norm_param {
use_global_stats: true
eps: 2e-5
}
}
layer {
name: "scale_stage1_unit2_bn2"
bottom: "stage1_unit2_conv2"
top: "stage1_unit2_conv2"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
name: "stage1_unit2_relu2"
type: "ReLU"
bottom: "stage1_unit2_conv2"
top: "stage1_unit2_conv2"
}
layer {
name: "stage1_unit2_conv3"
type: "Convolution"
bottom: "stage1_unit2_conv2"
top: "stage1_unit2_conv3"
convolution_param {
num_output: 256
kernel_size: 1
stride: 1
pad: 0
bias_term: false
}
}
layer {
name: "stage1_unit2_bn3"
type: "BatchNorm"
bottom: "stage1_unit2_conv3"
top: "stage1_unit2_conv3"
batch_norm_param {
use_global_stats: true
eps: 2e-5
}
}
layer {
name: "scale_stage1_unit2_bn3"
bottom: "stage1_unit2_conv3"
top: "stage1_unit2_conv3"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
name: "stage1_unit2_plus"
type: "Eltwise"
bottom: "stage1_unit1_plus"
bottom: "stage1_unit2_conv3"
top: "stage1_unit2_plus"
eltwise_param {
operation: SUM
}
}
layer {
name: "stage1_unit2_relu"
type: "ReLU"
bottom: "stage1_unit2_plus"
top: "stage1_unit2_plus"
}
参考文献
- Aggregated Residual Transformations for Deep Neural Networks, Saining-Xie, 2017
- https://github.com/cypw/ResNeXt-1