如今我们生活的时代被称作大数据时代,随着互联网技术的普及以及即将到来的5G通信技术,使我们比以往任何年代获取数据都变得更加的容易。那么大数据有什么特征呢?一:数据量大,以前我们衡量数据大小所用的单位都是MB、GB,而现在的数据量都是以TB,EB,ZB来计等等。二:数据类型多,如今我们所拿到的数据不单单是数值型数据,我们有语言文字、声音、图像等数据,它们的处理技术就不能采用以往的数据分析技术了,所以就产生了如今的人工智能领域,该领域主要由四大部分组成,机器学习(ML)作为该领域的主体,主要是对各种常规算法的研究,深度学习(DL)是在机器学习的基础上做的进一步提升,比如我们经常听到的神经网络算法等,自然语言处理(NLP)主要是对文字,声音等语言类进行处理,如我们的有道翻译(汉译英,文字转语音等)就属于这个方向,计算机视觉(CV)主要应用于图像识别领域,如我们小区门口的人脸识别机器,自动驾驶汽车需实时对周围环境进行识别等等。三:数据更新速度快,伴随着物联网技术的成熟,比如可穿戴设备,它可以实时监测我们的心率与血压等数据,并且这一数据在不断地更新。

相比以往的小批量数据的时代,我们注重分析数据之间的因果关系。而在这个大规模数据的时代,我们更加注重分析数据之间的相关性,对因果关系的分析逐渐的淡化。举个例子,假如我有一家客户属于快递行业,通过观察,它的车辆的行驶里程在逐月减少,我们可以很明显的发现客户的业务量在减少,随之而来,它的加油量也在减少,司机的工资也在相应的下降。现在有一家汽车4S店,当然它无法获取客户的业务情况以及司机薪资的变动情况(保密),但是客户的加油数据是可以从加油站获取的,一般情况下,公司都是用自己的油卡去加油的。通过分析加油数据,我们就可以判断客户的业务量的大小,业务量大,车辆运行时间长,故障风险就高,那么作为4S店,就得考虑是否多招聘一些技师或者多准备一些汽车配件?我举的例子可能没有那么准确,主要意思是原本两个不相关的数据也是可以产生联系的。
这个领域其实是挺深的,我也不是特别的专业,我平时主要跟车上的这些车联网设备打交道比较多,参数的调试,设备的维修,写报告,还有一点业务等。如果大家对这方面感兴趣,下面是一些不错的入门课程,课时都不是很长,讲的也都清晰易懂,空闲时间可以参考下。
这里我们主要说一说数据可视化,在我们的工作和学习中,做数据分析的工具有很多,如我们最常用的Excel,SPSS等等,这里我们用Python来做数据分析。Python与Excel,SPSS的区别在于用Python做数据分析更加的灵活,所有的功能都可以自定义,在Excel中,我们只能使用已经设置好的函数与功能。如果对数据分析感兴趣的话,可以按照Python基础 - Numpy库 - Pandas库 - Matplotlib库的顺序进行学习。
Python数据分析三板斧
Numpy:科学计算库,主要用于矩阵计算。
推荐一门快速入门课程[莫凡Python-Numpy]:
https://study.163.com/course/courseMain.htm?courseId=1003214021
Pandas:数据处理库,做好数据分析前的数据清洗工作。
课程推荐[莫凡Python-Pandas]:
https://study.163.com/course/courseMain.htm?courseId=1003214021
Matplotlib:数据可视化库,主要用于数据的展示工作。
课程推荐[莫凡Python-Matplotlib]
https://study.163.com/course/courseMain.htm?courseId=1003240004
如果Python基础有所欠缺,建议学习这门课程,1~2天时间,补习下Python的语法基础。
Python基础课程推荐[唐宇迪-Python快速入门]:
https://study.163.com/course/courseMain.htm?courseId=1003664056
数据可视化
这一节我们使用Seaborn库来展示数据,Seaborn库是Matplotlib库的扩展,它对Matplotlib库进行了封装和升级,语法更加的简单,图形也更加简洁美观。
通常一份数据集过来,其中都包含有许多特征(一列就是一个特征),我们的数据分析的一般步骤为单特征分析,双特征分析,多特征分析。
单特征分析
单特征分析我们一般要来研究数据的均值,中位数,方差,标准差,数据的分布规律等。
导入我们要使用的库,把我们的三板斧导进来。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
我们对数据的单个特征进行可视化展示,我们以Titanic(泰坦尼克)数据集为例进行展示。
数据集下载链接:https://pan.baidu.com/s/1WsxWwe4QKtmEsbh6qDxhaQ
提取码:5m48
titanic = pd.read_csv('D:\\Py_dataset\\titanic.csv')# pandas方法读取数据集
titanic = titanic.dropna()#数据预处理,删除缺失值
sns.distplot(titanic['Age'])#绘制年龄分布的直方图,图1
sns.violinplot(data = titanic,y = 'Age')#绘制年龄分布的小提琴图,图2
sns.boxplot(data = titanic,y = 'Age')#绘制年龄分布的盒图,图3
sns.countplot(data = titanic,y = 'Pclass')#对乘客的船舱等级分布进行统计,图4
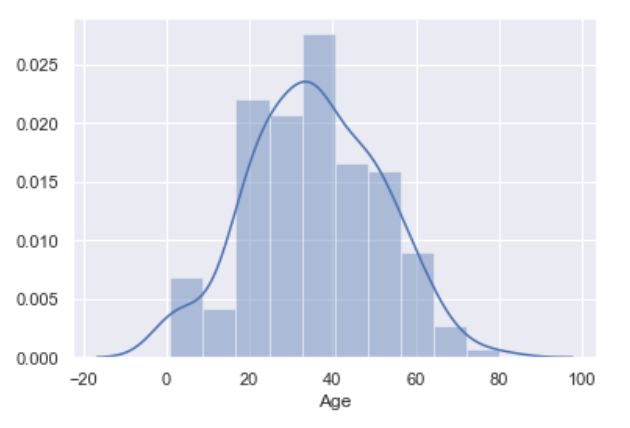
直方图可以很清楚的展示出不同年龄段(数值型特征)的数量分布,如果我们想自己指定年龄区间的话,我们可以在sns.distplot()函数中增加一个bins参数,如bins = [0,20,40,60,80]。
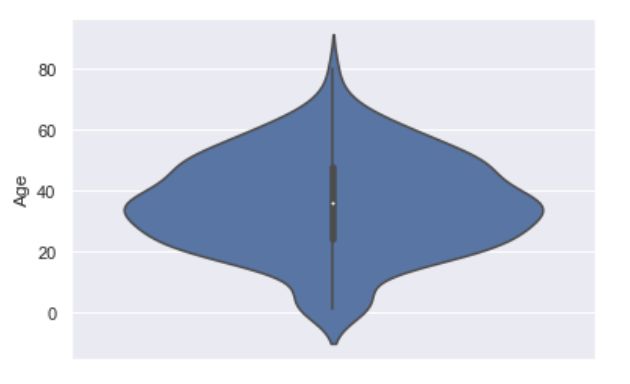
小提琴图也可以很直观地展示出年龄分布状况,面积越大的区域表示该区域分布的人数越多。

盒图可以很清楚的看出数据的分布范围,在盒图中我们可以看到五条线,从下到上,依次是最小值,四分位数,中位数,四分之三位数,最大值。如果出现了落在这个范围之外的点,我们就称之为离群数据点。
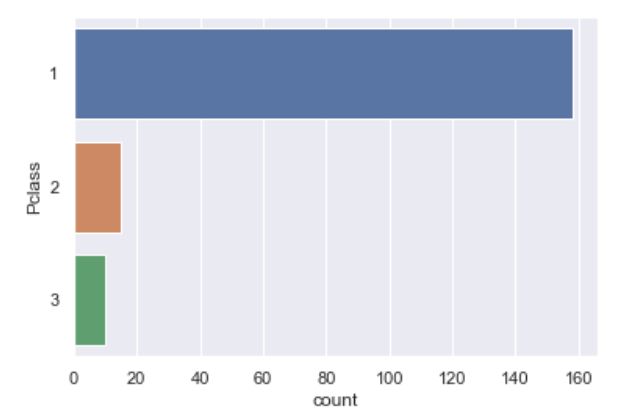
统计图可以很清楚地展示特征(非数值型特征)的数量分布情况。上图是titanic上乘客购买不同等级的船舱的数量分布。
还有一种数据类型我们称之为时间序列,例如,我们有一个城市过去3年中,每一个月的平均温度与平均降水量数量。对于时间序列数据,最直观的就是折线图,它可以反映数据随时间的变化情况。
双特征分析
探究两两特征之间的关系,seaborn库为我们封装了许多数据集,这个很方便我们用来做练习。我们用其中的iris数据来举例,分析两个特征之间关系最直观的就是散点图。

上面是iris数据集的前五行,前四列分别表示花萼长度、花萼宽度、花瓣长度、花瓣宽度,最后一列是花的种类。
data = sns.load_dataset('iris')#导入数据集
sns.jointplot(x = 'sepal_length',y = 'petal_length',data = data)#绘制散点图
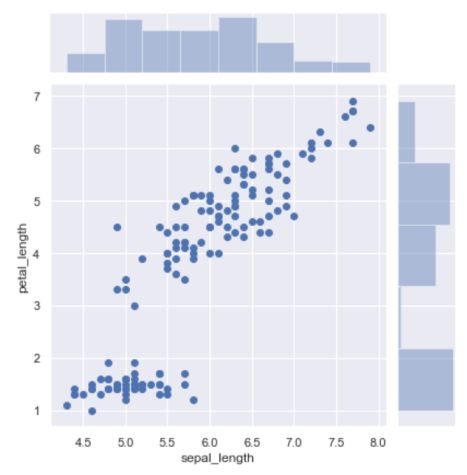
上图表示的是花萼长度与花瓣长度之间的关系,大体上,两者之间呈正相关。图的上侧和右侧简单的汇总了两个特征各自的分布情况。
我们也可以用一句话来画出这四个特征之间的两两关系。
sns.pairplot(data)

其中主对角线表示的是自身与自身之间的关系,即自身的直方图分布。
多特征分析
这里我们所说的多特征分析,主要是三特征分析,在平面空间上,特征再多的话,图形看起来就没那么清楚了。借助一些专业的可视化工具是可以做到更多特征的分析,如Tableau,PowerBI等等。
我们以上面的titanic数据集为例,来分析年龄(Age)、性别(Sex)与登录港口(Embarked)之间的关系。
sns.barplot(x = 'Embarked',y = 'Age',data = titanic, hue = 'Sex')#hue:增加分类特征

从上图我们可以清楚的看出,从三个不同港口登上泰坦尼克号的乘客,女性乘客的年龄均大于男性乘客。
当然也可以用其他的形式来表示这三者之间的关系,下面是小提琴图与树形图。表达方式有很多种,最重要的就是清晰直观,不要华而不实。
sns.violinplot(x = 'Embarked',y = 'Age',data = titanic, hue = 'Sex')#绘制小提琴图
sns.swarmplot(x = 'Embarked',y = 'Age',data = titanic, hue = 'Sex')#绘制树形图

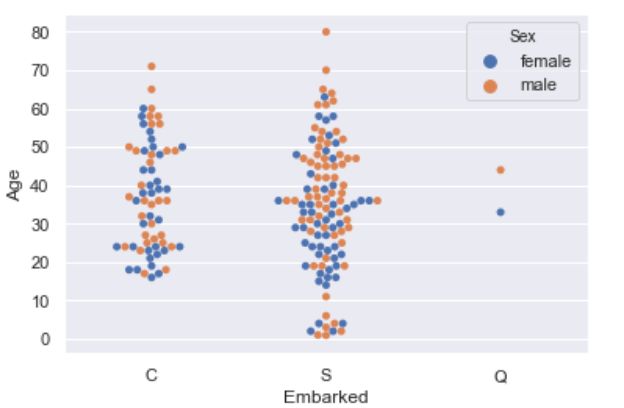
分析三特征关系的还有一种常用的图形-热度图。下面我们还是采用seaborn中的flights(航班)数据集作为例子。
flight = sns.load_dataset("flights")
#下面这一步使用了pandas的数据透视功能,对数据进行了组合
flight = pd.pivot_table(data = flight,index = 'year',columns = 'month',values = 'passengers')
sns.heatmap(flight,annot = True,fmt = 'd')

上面的热度图使用颜色的深浅来展示每一个月份中的乘客数量。
以上就是python数据化可视化的主要内容了,其目的还是对数据进行可视化展示,让观看者更容易理解数据。
当然对于更高维的数据,如果要做可视化展示就比较困难了。假如我是一位房屋中介,那么我平时看的房屋数据集是这个样子的,[小区名称,房屋单元,楼层,面积,卧室数量,距地铁站距离,周边是否有学校,......,价格],这时候如果要将这些特征与价格的关系表示在一张图中就显得很困难。这时我们会引入机器学习算法来拟合前面的特征与价格的关系,最终会得到一个拟合方程,经过过拟合方程的准确性进行优化,后期当我们再遇到新房源的时候,我们只需要在系统中输入房屋的这些基本特征,系统就会给出一个参考结果。
不管是从事生产工作,还是科学实验研究,还是销售业务或者售后服务,我们都会收集到许多数据,对这些历史数据进行研究,发现其中的规律,对我们的工作改进都会有一定的帮助。所以数据分析可以作为一项工作必备小技能。