Flink作为一个分布式流式计算引擎,需要计算资源才可以执行应用程序。Flink能够与目前所有通用的资源管理框架集成,比如Hadoop YARN、Apache Mesos和Kubernetes。除了运行在现有资源管理器上,Flink还能够独立部署运行(stand-alone cluster),也就是自身提供资源管理。
Standalone集群部署
Flink运行在类Unix操作系统之上,所以你可以部署在Linux、Mac OS X和Cygwin上。
环境准备
- Java1.8.x及以上版本。
- ssh安装
Java需要配置JAVA_HOME环境变量,并且指向Java安装目录。
ssh需要在集群节点上配置免密码登录,并且Flink安装目录也要在所有节点的相同目录上,这样我们就可以使用Flink的脚本来管理它们了。
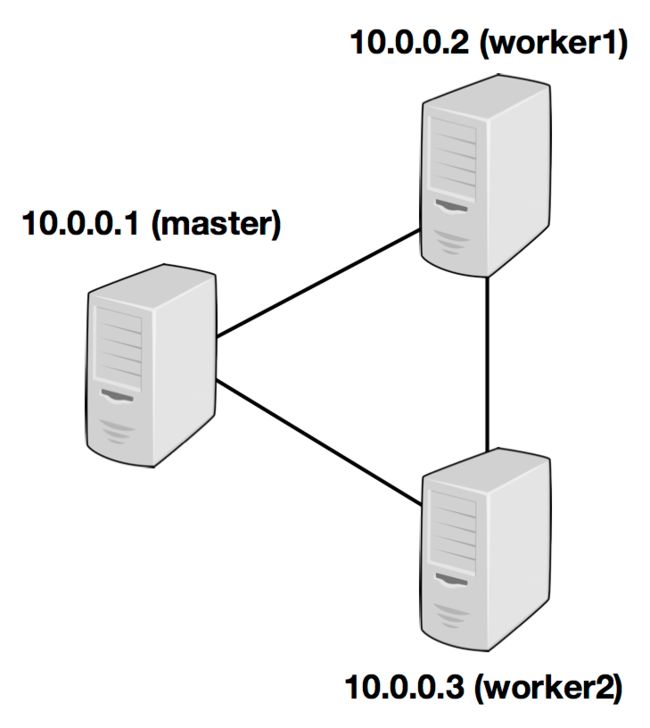
Flink集群由一个Master节点和一个或多个Worker节点组成。
| 主机 | 节点类型 | 服务名称 |
|---|---|---|
| 10.0.0.1 | master | jobmanager |
| 10.0.0.2 | worker | taskmanager |
| 10.0.0.3 | worker | taskmanager |
下载安装
使用Flink并不是必须要提前安装Hadoop,如果我们不打算使用Hadoop组件(比如HDFS、YARN、HBase等),我们就可以下载没有将Hadoop预编译到Flink的二进制安装包上。
Flink下载页面:https://flink.apache.org/downloads.html
tar xzf flink-*.tgz
cd flink-*
如果需要与Hadoop集成使用,需要选择预编译好的Hadoop版本,或者自己编译Flink源码来指定Hadoop版本。
配置Flink
我们下载解压缩Flink之后,就需要对Flink进行配置了。Flink配置文件在${FLINK_HOME}/conf/目录中,我们主要的配置文件为flink-conf.yaml。
在flink-config.yaml配置文件添加以下基础配置项:
- jobmanager.rpc.address:指定master节点。
- jobmanager.heap.mb:为master节点JVM配置最大内存。
- taskmanager.heap.mb:为worder节点JVM配置最大内存。
vim conf/flink-conf.yaml
jobmanager.rpc.address: 10.0.0.1
jobmanager.heap.mb: 2048m
taskmanager.heap.mb: 1024m
如果每个worker节点的内存不同,想要为某些特定worker节点多指定一些内存,则可以在特定节点上使用环境变量
FLINK_TM_HEAP来覆盖指定。
配置完flink-conf.yaml后,还需要在conf/slaves文件中给出所有worker节点。
vim conf/slaves
10.0.0.2
10.0.0.3
这里给出的是Flink的最简单集群配置,更多配置信息可以查看:https://ci.apache.org/projects/flink/flink-docs-release-1.7/ops/config.html。
节点分发
配置好后,我们需要将Flink目录文件分发到集群中的所有其它节点上。
scp -r flink-1.7.2 [email protected]:/opt/yjz/flink/flink-1.7.2/
scp -r flink-1.7.2 [email protected]:/opt/yjz/flink/flink-1.7.2/
特别注意:所有节点的Flink所在目录必须一致。
服务启动
节点分发后我们通过start-cluster.sh脚本在Master节点上来启动Flink集群。由于我们在slaves文件里面指定了所有worker节点,所以master节点会通过ssh免密码登录来启动所有worker节点。
bin/start-cluster.sh
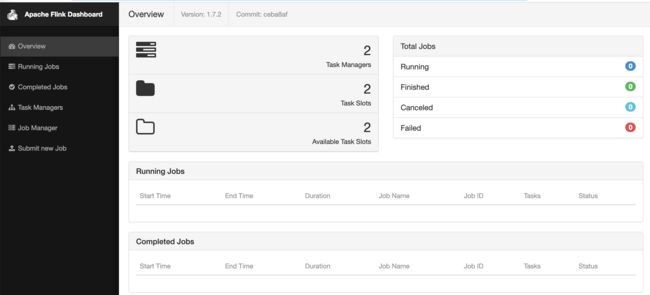
启动成功后我们可以通过UI界面来查看:http://10.0.0.1:8081
停止服务
停止服务直接使用bin/stop-cluster.sh脚本即可。
高可用部署
Flink集群的JobManager同时负责任务调度和资源管理(在Standalone模式下),可想而知它的压力是很大的。在默认情况下Flink集群只会启动一个JobManager,这样就会存在单点故障(single point of failure, SPOF)。
因此,一般在生产环境中我们需要为Standalone模式或YARN模式提供Flink的高可用部署方式(High Availability, HA)。
这里我们给出Standalone部署模式的HA部署方案,关于YARN的可以放到Flink on YARN部署文章中。
Flink高可用部署原理
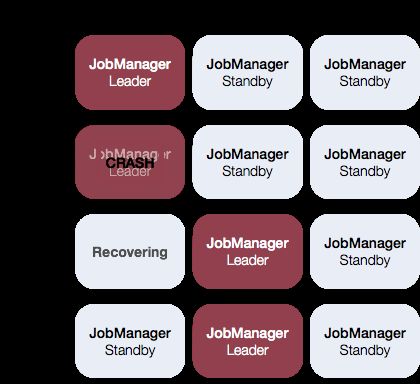
Flink的HA部署方案和业界的其它大数据处理框架HA基本一致:启动过程中启动多个JobManager,然后通过Zookeeper来选举出一个leader,其它JobManager作为备用主节点(standby)。
下图是描述在JobManager启动时首先选举一个Leader,当Leader节点挂掉后,从standby leader中再重新选举出一个新的Leader节点。
HA配置
Flink的JobManager使用Zookeeper作为分布式协调服务,所以我们需要独立部署一套Zookeeper,然后在Flink上添加一些必要的配置。
配置masters文件
我们需要将所有JobManager节点配置到conf/masters文件中,配置内容除了主机地址外,还需要配置webUI的端口。
jobManagerAddress1: webUIPort1
[...]
jobManagerAddressN: webUIportN
默认JobManager的通信端口是随机启动的,我们也可以为Flink指定特定的通信端口,但是范围只能是:50010,50011,50020-50025,50050-50075。(该配置在conf/flink-conf.yaml中)
high-availability.jobmanager.port: 50010
配置flink-conf.yaml文件
HA其余配置都在conf/flink-conf.yaml中,以下是基本配置:
#必要配置,通过Zookeeper启动HA模式
high-availability: zookeeper
#必要配置,指定Zookeeper连接地址,可以配置多个broker,防止Zk单节点挂掉
high-availability.zookeeper.quorum: 10.0.0.1:2181,10.0.0.2:2181
#建议配置,存储JobManager集群节点的根目录
high-availability.zookeeper.path.root: /flink
#建议配置,存储协调数据的目录
high-availability.cluster-id: /defaul_ns
#必须配置,JobManager中持久化元数据的存储目录(Zookeeper只存储了状态信息)
high-availability.storageDir: hdfs:///flink/recovery
启动集群
在启动Flink之前,要确保Zookeeper集群已经启动并运行。
bin/start-cluster.sh
Flink自带Zookeeper集群
对于测试集群,如果我们没有Zookeeper实例集群,可以使用Flink自带的Zookeeper集群。在conf/zoo.cfg下有Zookeeper的配置模板。我们可以指定运行Zookeeper服务的节点:
server.1= address1:peerPort1:leaderPort1
[...]
server.X= addressX:peerPort:leaderPort
然后使用Flink自带的脚本启动Zookeeper集群:bin/start-zookeeper-quorum.sh。
对于生产环境,建议使用自己的独立Zookeeper集群。
单机部署
我们在学习或测试的时候可以使用本地单机Flink模式,单机Flink部署方式非常简单,我们只需要将Flink二进制安装包下载下来后,直接使用bin/flink-start.sh来启动即可。
默认conf/flink-conf.yaml中的jobmanager.rpc.address配置项为localhost,slaves文件中也为localhost,所以会在本地即启动jobmanager又启动taskmanager。
Flink CLI
Flink提供了命令行接口(Command-Line Interface,CLI)来运行作业jar包和控制作业执行。CLI位于bin/flink 目录下。
Flink CLI格式如下:
./flink [OPTIONS] [ARGUMENTS]
ACTION包含了一下几类:
| ACTION | 使用方式 | 说明 |
|---|---|---|
| run | ./flink run [OPTIONS] |
编译并运行作业 |
| info | ./flink info [OPTIONS] |
以JSON的形式显示程序的优化执行计划 |
| list | ./flink list [OPTION] | 列出正在执行和调度(scheduled)的任务 |
| stop | ./flink stop [OPTION] |
停止运行的程序,注意使用stop只能停止流处理作业。 |
| cancel | ./flink cancel [OPTION] |
取消运行的程序 |
| savepoint | ./flink savepoint [OPTIONS] |
为运行中的作业触发保存点 |
| modify | ./flink modify |
修改运行中的程序 |
具体OPTIONS参数我们可以通过./flink 命令详细查看使用。
stop和cancel虽然都是停止作业,但是两者实现是不一样的。使用cancel方法作业中的operator会立即接收到停止命令,来取消任务。如果operator没有取消任务,Flink开始定期中断线程,直到它停止。而stop是以一种更优雅的方式来停止作业,使用Stop停止作业,任务数据源需要实现
StoppableFunction接口,这样当收到stop命令时,数据源首先停止发送数据,然后等待集群中的作业执行完成,最后正常停止作业。
关注我
欢迎关注我的公众号,会定期推送优质技术文章,让我们一起进步、一起成长!
公众号搜索:data_tc
或直接扫码:
