导语:
随着技术的发展,不管是前端开发、服务端开发或者是移动端开发(移动也是前端的一个分支)中都会用到自动化构建工具。如果我们没有使用过自动化构建工具,可能对自动构建工具没有什么概念,为什么需要用到自动化构建工具。我们先来看一下在没有使用自动化构建工具前,我们是如何开发项目、管理项目的。项目开发过程中涉及新建项目-》代码开发—》依赖管理-》编译-》测试-》打包-》上传等过程。依赖管理,项目开发过程中会用到很多jar包,自己开发的有别人开发的,这些都放在项目的lib目录。大点的项目几百个,很容易造成依赖冲突,另外就是版本更新特别不方便,你得手动去复制新版本的jar包放到lib目录下。测试过程,大家都不重视,基本上写一个java类,在main方法调用调试几下就完了。打包,得手动,如在Eclipse上导出jar包,web开发的话导出war包。另外发布不同版本,还得手动去更改后才能打出自己想要的。上传过程中,得手动或用ftp上传到服务器上面。这些过程太频繁、琐碎无聊,小点项目还能管理的过来,大的项目简直是灾难。技术大牛们忍无可忍总于爆发了,发明出了构建工具这个东西,将程序员们从水深火热中解脱出来。
构建工具的作用
- 依赖管理
- 自动测试、自动打包、自动发布到制定的地方去
- 机器能干的,我们绝不自己动手
Java方面主流的构建工具
- 最早出现的Ant,提供了编译、测试、打包三个最基本的功能
- 接着Maven,在Ant的基础上加了依赖管理和发布功能,通过xml标记性语言来进行管理构建脚步
- 接着重点来了,我们要学习的Gradle,它在Maven基础上更近一步,使用Groovy进行管理构建脚步,不再使用xml ,因为项目大了之后使用xml很容易造成啰唆、臃肿难以管理。而使用这种特定领域语言来管理构建脚步具有更高的可拓展性和灵活性。
Gradle是什么
一个开源的项目自动化构建工具,建立在Apache Ant 和 Apache Maven概念的基础上,并引入了基于Groovy的特定领域语言(DSL),而不再使用xml形式的管理构建脚本。
Gradle的作用,即能为我们做什么
Gradle是一个项目自动化构建工具,它当然具备自动化构建的所有功能,依赖管理,自动化测试、自动化打包,发布到制定的地方去。另外它具有很高的拓展性和灵活性,你想要它做什么,它都能帮你完成。
准备使用Gradle
Gradle的安装、配置环境变量
1. 因为Gradle是基于JVM的所以确保本地安装了JDK java -version
2. 打开官网下载安装包,解压到制定的目录Gradle官网https://gradle.org/docs#getting-started
3. 配置环境变量,GRADLE_HOME添加到path中,%GRADLE_HOME%\bin;
4. 验证是否安装成功,gradle -v
groovy语言基础知识
Groovy是什么
Groovy是用Java虚拟机的一种敏捷的动态语言,它是一种成熟的面向对象编程语言,即可用于面向对象编程,又可以用作纯粹的脚本语言。使用该语言不需要编写太多的代码,同时又具有闭包和动态语言中的其他特性。
下面的知识点都可以到官网文档中查询到http://www.groovy-lang.org/documentation.html
与java相比
1、Groovy完全兼容java语法,最终也编译成字节码
2、Groovy注释标记和Java一样,支持//或者//
3、Groovy中支持动态类型,即定义变量的时候可以不指定其类型。
4、Groovy中,变量定义可以使用关键字def。注意,虽然def不是必须的,但是为了代码清晰,建议还是使用def关键字。
def var =1
def str= "i am a person"
def int x = 1//也可以指定类型
5、函数定义时,参数的类型也可以不指定。比如
String function(arg1,args2){//无需指定参数类型
}
6、除了变量定义可以不指定类型外,Groovy中函数的返回值也可以是无类型的。
比如://无类型的函数定义,必须使用def关键字
def nonReturnTypeFunc(){
last_line //最后一行代码的执行结果就是本函数的返回值
}
//如果指定了函数返回类型,则可不必加def关键字来定义函数
String getString(){
return "I am a string"
}
其实,所谓的无返回类型的函数,我估计内部都是按返回Object类型来处理的。毕竟,Groovy是基于Java的,而且最终会转成Java Code运行在JVM上。
7、 函数返回值:Groovy的函数里,可以不使用return xxx来设置xxx为函数返回值。如果不使用return语句的话,则函数里最后一句代码的执行结果被设置成返回值。比如
//下面这个函数的返回值是字符串"getSomething return value"
def getSomething(){
"getSomething return value" //如果这是最后一行代码,则返回类型为String
1000 //如果这是最后一行代码,则返回类型为Integer
}
注意,如果函数定义时候指明了返回值类型的话,函数中则必须返回正确的数据类型,否则运行时报错。如果使用了动态类型的话,你就可以返回任何类型了。
8、Groovy对字符串支持相当强大,充分吸收了一些脚本语言的优点:单引号''中的内容严格对应Java中的String,不对$符号进行转义
def singleQuote='I am $ dolloar' //输出就是I am $ dolloar
双引号""的内容则和脚本语言的处理有点像,如果字符中有$号的话,则它会$表达式先求值。
def doubleQuoteWithoutDollar = "I am one dollar" //输出 I am one dollar
def x = 1
def doubleQuoteWithDollar = "I am $x dolloar" //输出I am 1 dolloar
三个引号'''xxx'''中的字符串支持随意换行 比如
def multieLines = ''' begin
line 1
line 2
end '''
9、 Groovy语句可以不用分号结尾。Groovy为了尽量减少代码的输入,确实煞费苦心
10、除了每行代码不用加分号外,Groovy中函数调用的时候还可以不加括号。比如:
println("test") ---> println "test"
注意,虽然写代码的时候,对于函数调用可以不带括号,但是Groovy经常把属性和函数调用混淆。比如
def getSomething(){
"hello"
}
getSomething() //如果不加括号的话,Groovy会误认为getSomething是一个变量。
数据类型的不同
Groovy中的数据类型我们就介绍两种和Java不太一样的:
一个是Java中的基本数据类型。
另外一个是Groovy中的容器类。
最后一个非常重要的是闭包。
基本数据类型
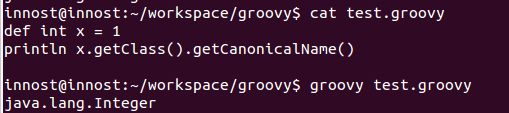
作为动态语言,Groovy世界中的所有事物都是对象。所以,int,boolean这些Java中的基本数据类型,在Groovy代码中其实对应的是它们的包装数据类型。比如int对应为Integer,boolean对应为Boolean。比如下图中的代码执行结果:
容器类
List类其实是ArrayList类
变量定义:List变量由[]定义,比如
def aList = [5,'string',true] //List由[]定义,其元素可以是任何对象
变量存取:可以直接通过索引存取,而且不用担心索引越界。如果索引超过当前链表长度,List会自动
往该索引添加元素
assert aList[1] == 'string'
assert aList[5] == null //第6个元素为空
aList[100] = 100 //设置第101个元素的值为10
assert aList[100] == 100
那么,aList到现在为止有多少个元素呢?
println aList.size ===>结果是101
Map类其实是LinkedHashMap类
容器变量定义
变量定义:Map变量由[:]定义,比如
def aMap = ['key1':'value1','key2':true]
Map由[:]定义,注意其中的冒号。冒号左边是key,右边是Value。key必须是字符串,value可以是任何对象。另外,key可以用''或""包起来,也可以不用引号包起来。比如
def aNewMap = [key1:"value",key2:true] //其中的key1和key2默认被
处理成字符串"key1"和"key2"
不过Key要是不使用引号包起来的话,也会带来一定混淆,比如
def key1="wowo"
def aConfusedMap=[key1:"who am i?"]
aConfuseMap中的key1到底是"key1"还是变量key1的值“wowo”?显然,答案是字符串"key1"。如果要是"wowo"的话,则aConfusedMap的定义必须设置成:
def aConfusedMap=[(key1):"who am i?"]
Map中元素的存取更加方便,它支持多种方法:
println aMap.keyName <==这种表达方法好像key就是aMap的一个成员变量一样
println aMap['keyName'] <==这种表达方法更传统一点
aMap.anotherkey = "i am map" <==为map添加新元素
Range类
Range是Groovy对List的一种拓展,变量定义和大体的使用方法如下:
def aRange = 1..5 <==Range类型的变量 由begin值+两个点+end值表示
左边这个aRange包含1,2,3,4,5这5个值
如果不想包含最后一个元素,则
def aRangeWithoutEnd = 1..<5 <==包含1,2,3,4这4个元素
println aRange.from
println aRange.to
高级特性闭包
闭包,英文叫Closure,是Groovy中非常重要的一个数据类型或者说一种概念了。闭包的历史来源,种种好处我就不说了。我们直接看怎么使用它!闭包,是一种数据类型,它代表了一段可执行的代码。其外形如下:
def aClosure = {//闭包是一段代码,所以需要用花括号括起来..
String param1, int param2 -> //这个箭头很关键。箭头前面是参数定义,箭头后面是代码
println"this is code" //这是代码,最后一句是返回值,
//也可以使用return,和Groovy中普通函数一样
}
简而言之,Closure的定义格式是:
def xxx = {paramters -> code} //或者
def xxx = {无参数,纯code} 这种case不需要->符号
说实话,从C/C++语言的角度看,闭包和函数指针很像。闭包定义好后,要调用它的方法就是:闭包对象.call(参数) 或者更像函数指针调用的方法:闭包对象(参数)比如
aClosure.call("this is string",100) 或者
aClosure("this is string", 100)
\\上面就是一个闭包的定义和使用。在闭包中,还需要注意一点:
\\如果闭包没定义参数的话,则隐含有一个参数,这个参数名字叫it,和this的作用类似。it代表闭包的参数。比如:
def greeting = { "Hello, $it!" }
assert greeting('Patrick') == 'Hello, Patrick!'
\\等同于
def greeting = { it -> "Hello, $it!" }
assert greeting('Patrick') == 'Hello, Patrick!'
\\但是,如果在闭包定义时,采用下面这种写法,则表示闭包没有参数!
def noParamClosure = { -> true }
\\这个时候,我们就不能给noParamClosure传参数了!
noParamClosure ("test") \\<==报错喔!
Closure使用中的注意点
1、省略圆括号
闭包在Groovy中大量使用,比如很多类都定义了一些函数,这些函数最后一个参数都是一个闭包。比如:
public static
上面这个函数表示针对List的每一个元素都会调用closure做一些处理。这里的closure,就有点回调函数的感觉。但是,在使用这个each函数的时候,我们传递一个怎样的Closure进去呢?比如:
def iamList = [1,2,3,4,5] //定义一个List
iamList.each{ //调用它的each,这段代码的格式看不懂了吧?each是个函数,圆括号去哪了?
println it
}
上面代码有两个知识点:each函数调用的圆括号不见了!原来,Groovy中,当函数的最后一个参数是闭包的话,可以省略圆括号。比如
def testClosure(int a1,String b1, Closure closure){
//do something
closure() //调用闭包}那么调用的时候,就可以免括号!
testClosure (4, "test", {
println "i am in closure"
} )
//括号可以不写..
注意,这个特点非常关键,因为以后在Gradle中经常会出现图1这样的代码:
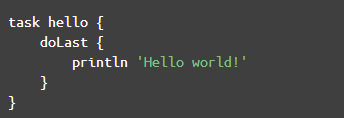
经常碰见图1这样的没有圆括号的代码。省略圆括号虽然使得代码简洁,看起来更像脚本语言,但是它这经常会让我confuse(不知道其他人是否有同感),以doLast为例,完整的代码应该按下面这种写法:
doLast({
println 'Hello world!'
})
有了圆括号,你会知道 doLast只是把一个Closure对象传了进去。很明显,它不代表这段脚本解析到doLast的时候就会调用println 'Hello world!' 。但是把圆括号去掉后,就感觉好像println 'Hello world!'立即就会被调用一样!
2、如何确定Closure的参数
另外一个比较让人头疼的地方是,Closure的参数该怎么搞?还是刚才的each函数:
public static
如何使用它呢?比如:
def iamList = [1,2,3,4,5] //定义一个List变量
iamList.each{ //调用它的each函数,只要传入一个Closure就可以了。
println it
}
看起来很轻松,其实:对于each所需要的Closure,它的参数是什么?有多少个参数?返回值是什么?我们能写成下面这样吗?
iamList.each{String name,int x -> return x} //运行的时候肯定报错!
所以,Closure虽然很方便,但是它一定会和使用它的上下文有极强的关联。要不,作为类似回调这样的东西,我如何知道调用者传递什么参数给Closure呢?
此问题如何破解?只能通过查询API文档才能了解上下文语义。比如下图2:
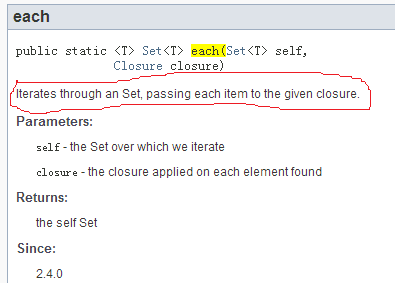
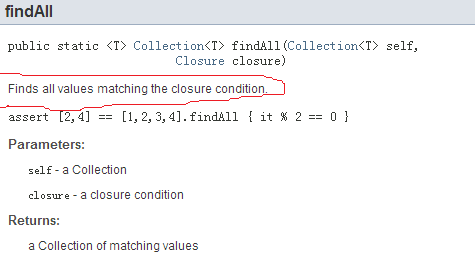
图2中:each函数说明中,将给指定的closure传递Set中的每一个item。所以,closure的参数只有一个。findAll中,绝对抓瞎了。一个是没说明往Closure里传什么。另外没说明Closure的返回值是什么.....。
对Map的findAll而言,Closure可以有两个参数。findAll会将Key和Value分别传进去。并且,Closure返回true,表示该元素是自己想要的。返回false表示该元素不是自己要找的。示意代码所示:
def result = aMap.findAll {
key, value ->
println "key=$key,value=$value"
if (key == "k1")
return true
return false
}
Closure的使用有点坑,很大程度上依赖于你对API的熟悉程度,所以最初阶段,SDK查询是少不了的。
3、脚本类
groovy也可以像java那样写package,然后写类
package bean
class Person {
String name
String gender
Person(name, gender) {
this.name = name
this.gender = gender
}
def print() {
println name + " " + gender
}
}
import bean.Person
def name = 'EvilsoulM'
def person=new Person(name,"male");
person.print()
groovy和Java类很相似。当然,如果不声明public/private等访问权限的话,Groovy中类及其变量默认都是public的。
4、脚本到底是什么
Java中,我们最熟悉的是类。但是我们在Java的一个源码文件中,不能不写class(interface或者其他....),而Groovy可以像写脚本一样,把要做的事情都写在xxx.groovy中,而且可以通过groovy xxx.groovy直接执行这个脚本。这到底是怎么搞的?
Groovy把它转换成这样的Java类:执行 groovyc -d classes test.groovy groovyc是groovy的编译命令,-d classes用于将编译得到的class文件拷贝到classes文件夹下图4是test.groovy脚本转换得到的java class。用jd-gui反编译它的代码:
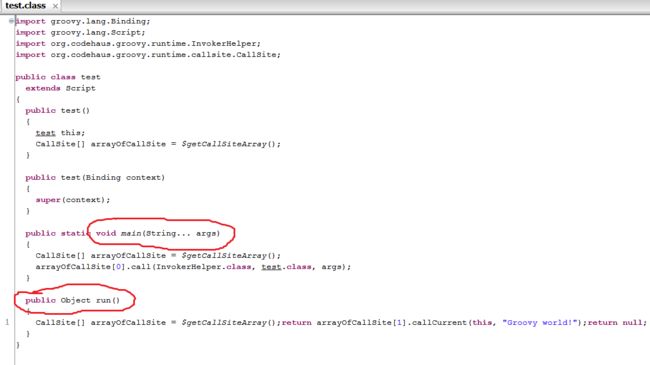
test.groovy被转换成了一个test类,它从script派生。
- 每一个脚本都会生成一个static main函数。
- 这样,当我们groovy test.groovy的时候,其实就是用java去执行这个main函数脚本中的所有代码都会放到run函数中。比如,println 'Groovy world',这句代码实际上是包含在run函数里的。
- 如果脚本中定义了函数,则函数会被定义在test类中。
groovyc是一个比较好的命令,读者要掌握它的用法。然后利用jd-gui来查看对应class的Java源码。
5、脚本中的变量和作用域
前面说了,xxx.groovy只要不是和Java那样的class,那么它就是一个脚本。而且脚本的代码其实都会被放到run函数中去执行。那么,在Groovy的脚本中,很重要的一点就是脚本中定义的变量和它的作用域。举例:
def x = 1 // <==注意,这个x有def(或者指明类型,比如 int x = 1)
def printx(){
println x
}
//printx() <==报错,说x找不到
为什么?继续来看反编译后的class文件。
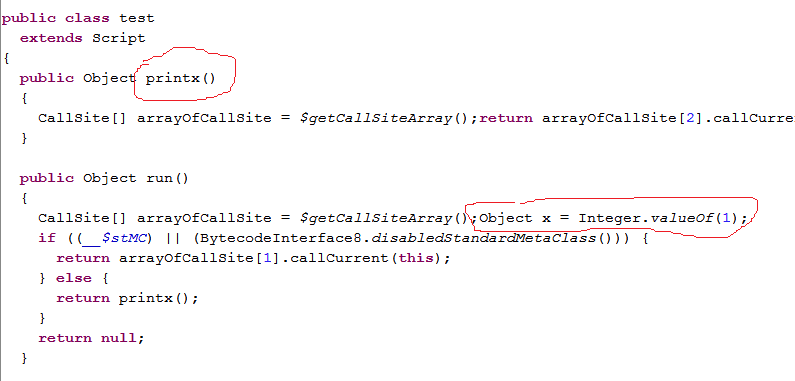
图中,x也没有被定义成test的成员函数,而是在run的执行过程中,将x作为一个属性添加到test实例对象中了。然后在printx中,先获取这个属性。注意,Groovy的文档说 x = 1这种定义将使得x变成test的成员变量,但从反编译情况看,这是不对的.....(这是infoQ文章中说的,但是测试来说这句话是对的,应该是文章作者没有定义成class)虽然printx可以访问x变量了,但是假如有其他脚本却无法访问x变量。因为它不是test的成员变量。比如,我在测试目录下创建一个新的名为test1.groovy。这个test1将访问test.groovy中定义的printx函数:
def atest=new test()
atest.printx()
这种方法使得我们可以将代码分成模块来编写,比如将公共的功能放到test.groovy中,然后使用公共功能的代码放到test1.groovy中。执行groovy test1.groovy,报错。说x找不到。这是因为x是在test的run函数动态加进去的。怎么办?
import groovy.transform.Field; //必须要先import
@Field x = 1 // <==在x前面加上@Field标注,这样,x就彻彻底底是test的成员变量了。
查看编译后的test.class文件,得到:
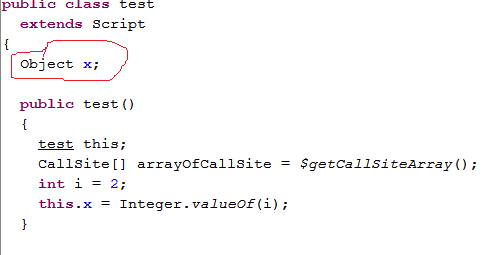
这个时候,test.groovy中的x就成了test类的成员函数了。如此,我们可以在script中定义那些需要输出给外部脚本或类使用的变量了!
eg:
ScriptBase.groovy类 (用了filed 就相当这就是一个class 就不用再自己定义class了)
import groovy.transform.Field;
@Field author = 'EvilsouM'
@Field gender = 'male'
@Field age = 25//必须要先import
def printInfo() {
println "name->$author gender->$gender age->$age"
}
//或者自己定义class
class ScriptBase {
def author = 'EvilsouM'
def gender = 'male'
def age = 25//必须要先import
def printInfo() {
println "name->$author gender->$gender age->$age"
}
}
.groovy类
def Closure printAuthorInfo = {
String name, String gender, int age ->
println "name->$name gender->$gender age->$age"
}
def ScriptBase base = new ScriptBase()
base.printInfo()
printAuthorInfo.call(base.author, base.gender, base.age) //上面两种方式都能拿到成员变量
文件I/O操作
本节介绍下Groovy的文件I/O操作。直接来看例子吧,虽然比Java看起来简单,但要理解起来其实比较难。尤其是当你要自己查SDK并编写代码的时候。整体说来,Groovy的I/O操作是在原有Java I/O操作上进行了更为简单方便的封装,并且使用Closure来简化代码编写。主要封装了如下一些了类:

- 读文件Groovy中,文件读操作简单到令人发指:def targetFile = new File(文件名) <==File对象还是要创建的。然后打开http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/File.html看看Groovy定义的API:
- 读该文件中的每一行:eachLine的唯一参数是一个Closure。Closure的参数是文件每一行的内容其内部实现肯定是Groovy打开这个文件,然后读取文件的一行,然后调用Closure...
def File targetFile = new File("build.gradle")
targetFile.eachLine {
String line ->
println line
}
- 直接得到文件内容
targetFile.getBytes() <==文件内容一次性读出,返回类型为byte[]
- 使用InputStream.InputStream的SDK在 http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/InputStream.html
def ism = targetFile.newInputStream() //操作ism,最后记得关掉
ism.close
- 使用闭包操作inputStream,以后在Gradle里会常看到这种搞法
``
targetFile.withInputStream{
ism -> //操作ism. 不用close。Groovy会自动替你close
}
写文件和读文件差不多
不再啰嗦。这里给个例子,告诉大家如何copy文件。
def srcFile = new File(源文件名)
def targetFile = new File(目标文件名)
targetFile.withOutputStream{
os->
srcFile.withInputStream {
ins->
os << ins //利用OutputStream的<<操作符重载,完成从inputstream到OutputStream //的输出
}
}
以上的知识点都可以去官网查看API,Groovy的API文档位于 http://www.groovy-lang.org/api.html
第一个Gradle项目,领略Gradle的风采
Gradle构建脚步基本原理部分
构建脚步介绍
Gradle构建中的两个基本概念就是项目(project)和任务(task),每个构建(build.gradle)至少包含一个项目,项目中包含一个或多个任务。在多项目构建中,一个项目可以依赖于其他项目;类似的,任务可以形成一个依赖关系图来确保他们的执行顺序。
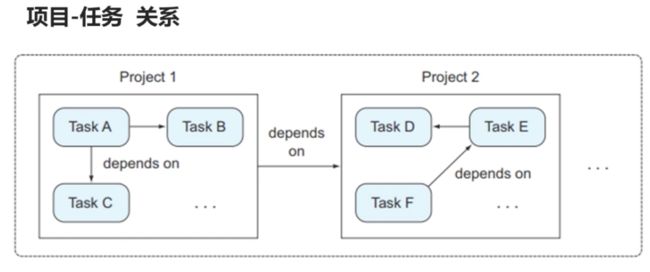
脚步基本组成部分
项目(project)
一个项目代表一个正在构建的组件(比如一个jar文件),当构建启动后,Gradle会基于build.gradle实例化一个org.gradle.api.Project类,并且能够通过project变量使其隐式可用。Project类的主要属性和方法
属性group、name、version
方法有apply、dependencies、repositories、task
属性的其他配置方式:ext、gradle.properties
任务(task)
任务对应org.gradle.api.Task。主要包括任务动作和任务依赖。任务动作定义了一个最小的工作单元。可用定义依赖于其他任务、动作序列和执行条件。
**Task重要的方法
dependsOn
doFirst,doLast << **
task是个动作列,doFirst就是在动作列表最前面添加一个动作,doLast就是在动作列表的最后面添加一个动作
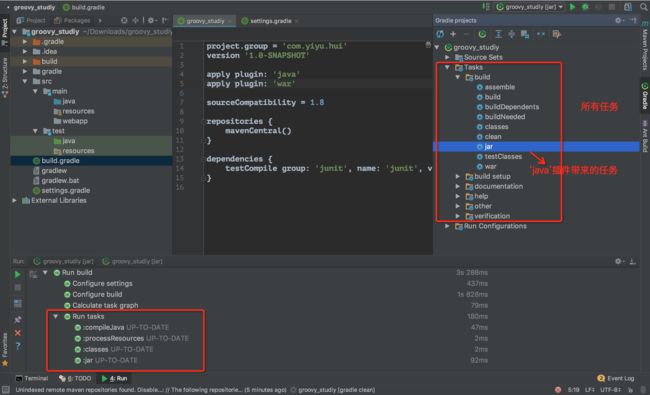
自定义任务(Task)、Task的生命周期
自定义创建文件夹任务

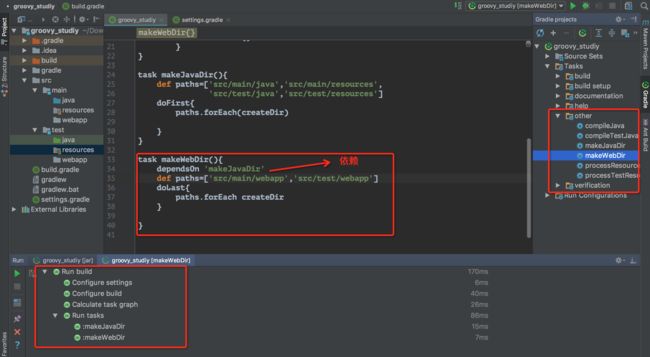
构建生命周期
1、 初始化阶段
项目构建开始的时候,会根据build.gradle构建一个项目即project并且在这个脚本中隐式可用。在多项目构建中这个阶段也是很重要的,它会初始化所有需要参与到构建中的项目。
2、配置阶段
这个阶段就是遍历项目中所有task,生成task依赖顺序以及执行顺序,根据配置代码来生成的。配置代码就是除了动作代码外都是配置代码,可以简单的这么理解。 这个阶段相当于初始化任务Task阶段
配置代码如:

3、执行阶段
主要执行动作代码,执行完后即一个构建就完成了。
动作代码如:

Gradle的工作流程其实蛮简单,用一个图15来表达:

图15告诉我们,Gradle工作包含三个阶段:
首先是初始化阶段。对我们前面的multi-project build而言,就是执行settings.gradle
Initiliazation phase的下一个阶段是Configration阶段。
Configration阶段的目标是解析每个project中的build.gradle。比如multi-project build例子中,解析每个子目录中的build.gradle。在这两个阶段之间,我们可以加一些定制化的Hook。这当然是通过API来添加的。Configuration阶段完了后,整个build的project以及内部的Task关系就确定了。恩?前面说过,一个Project包含很多Task,每个Task之间有依赖关系。Configuration会建立一个有向图来描述Task之间的依赖关系。所以,我们可以添加一个HOOK,即当Task关系图建立好后,执行一些操作。
最后一个阶段就是执行任务了。当然,任务执行完后,我们还可以加Hook。
我在:
- settings.gradle加了一个输出。
- 在posdevice的build.gradle加了图15中的beforeProject函数。
- 在CPosSystemSdk加了taskGraph whenReady函数和buidFinished函数。
好了,Hook的代码怎么写,估计你很好奇,而且肯定会埋汰,怎么就还没告诉我怎么写Gradle。马上了!
最后,关于Gradle的工作流程,你只要记住:
- Gradle有一个初始化流程,这个时候settings.gradle会执行。
- 在配置阶段,每个Project都会被解析,其内部的任务也会被添加到一个有向图里,用于解决执行过程中的依赖关系。
- 然后才是执行阶段。你在gradle xxx中指定什么任务,gradle就会将这个xxx任务链上的所有任务全部按依赖顺序执行一遍!
下面的这个链接对于学习Gradle很重要,
https://docs.gradle.org/current/dsl/
依赖管理
几乎所有的基于JVM软件项目都需要依赖外部类库来重用现有的功能。自动化依赖管理可以明确依赖的版本,可以解决因传递性依赖带来的版本冲突。
工件坐标
group、name、version
** 仓库**
mavenLocal/mavenCentral/jcenter,第一个本地仓库,后面两个是公共仓库
自定义maven仓库,就是maven私服仓库,公司内部为了代码的安全肯定不会放到公共仓库里面去,我们需要搭建一个内部仓库,管理自己的jar包。这个是实际中经常用的。
文件仓库,所谓的文件仓库,就是本地机器上的文件路径也可以作为仓库,这个非常不建议大家使用,因为我们使用构建工具就是为了让构建一致性,就是到处构建,结果应该是一样的。如果跟具体的机器有关的话,就违反了我们使用构建工具的初衷。
依赖的传递性
B依赖A,如果C依赖B,那么C依赖A
正是因为有这种依赖的传递性,造成版本的冲突
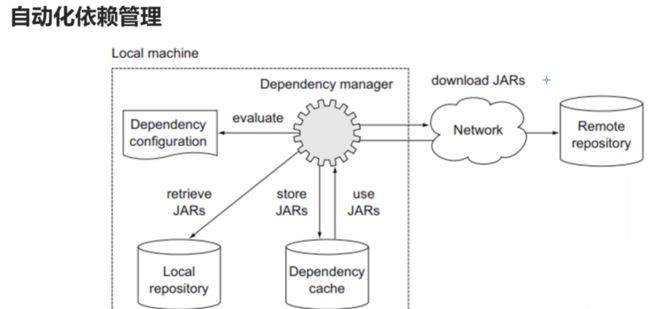
依赖阶段配置
- compile、runtime
- testCompile、testRuntime
依赖阶段关系
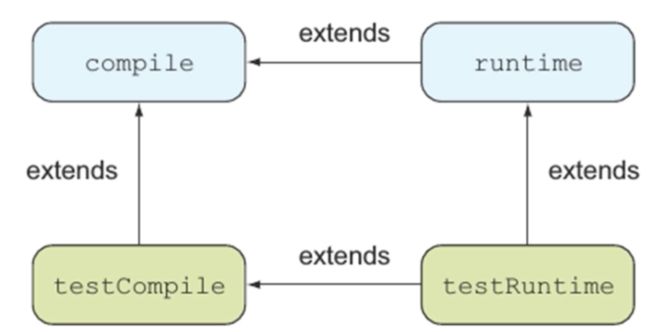
编译期依赖的,运行期必然依赖,运行期依赖的,编译期未必依赖;源码编译依赖的,测试编译必然依赖,测试编译依赖的,源码编译期未必依赖;测试编译依赖的,测试运行期必然依赖。
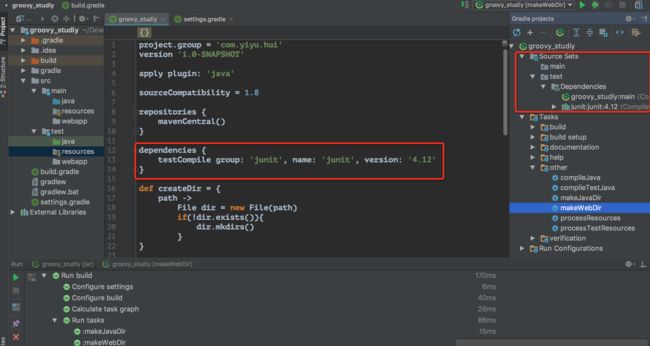
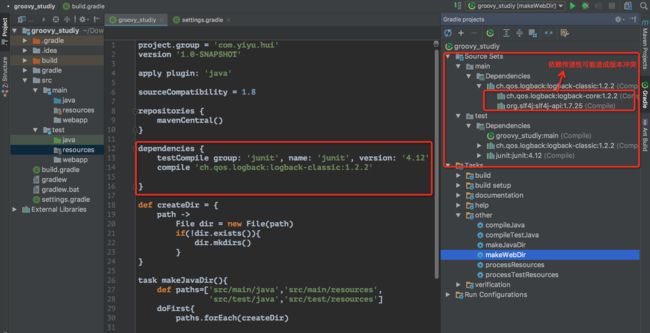
mavenCentral公共仓库网址 http://search.maven.org/
** 版本冲突解决方法**
版本冲突实际列子
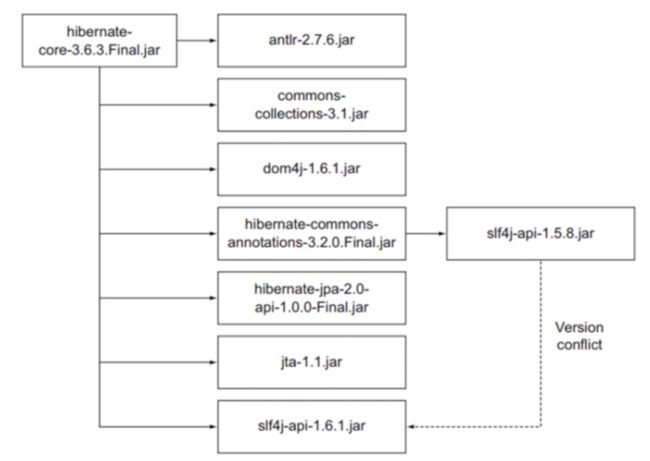
解决方法步骤
1、查看依赖报告
2、排除传递性依赖
3、强制制定一个版本
基本不需要我们自己解决版本冲突,gradle会自动帮我们强制依赖最高版本的jar包
修改默认解决策略方法,不然很难发现版本冲突
configurations.all{
resolutionsStrategy{
failOnVersionConflict()
}
}
排除传递性依赖的方法如下
compile('org.hibernate:hibernate-core:3.6.3.Final'){
exclude group:"org.slf4j",module:"slf4j-api"
//transitive=false
}
强制制定一个版本
configurations.all{
resolutionsStrategy{
force 'org.slf4j:slf4j-api:1.7.24'
}
}