Flume的功能和架构特点
- ** 功能 **
flume 是一个分布式的,可靠的,可用的,可以非常有效率的对大数据的日志数据进行收集、聚集、转移。 -
架构特点
 1.png
1.png
- flume仅仅能运行在linux环境下,如果想收集windows服务器上的日志数据,可以配置一个网络文件系统(nfs),让windows上的日志数据可以在linux上访问。
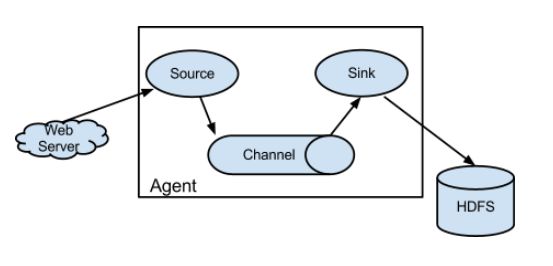
- 每一个flume进程都有一个agent层,agent层包含有source、channel、sink
source:采集日志数据,并发送给channel
channel:管道,用于连接source和sink,它是一个缓冲区,从source传来的数据会以event的形式在channel中排成队列,然后被sink取走。
sink:获取channel中的数据,并存储到目标源中,目标源可以是HDFS和Hbase。 - 配置文件很简单:只需要配置source、channel、sink
- 数据是基于流式(只要有数据更新,就立即获取),因此可以在线实时的采集日志数据。
-
数据传输单元event
 2.png
2.png
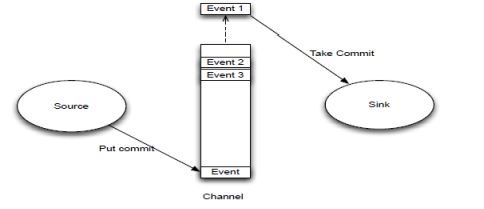
event是整个数据流的基本单位,每次source写和sink拿都是把数据封装在一个event对象中,类似于mapreduce的基本处理单位是
对一样。为了数据的安全性考虑,event载有的数据对flume来说是不透明的。 - flume数据流过程
source监控某个文件,若文件数据改变,则将数据拿到,并封装到一个event当中,并put commit到channel中,channel的数据结构是一个先进先出的队列,sink主动去从channel当中拉去数据,然后存储到目标路径。
安装搭建Flume
flume的版本:flume-ng-1.5.0-cdh5.3.6
-
下载解压
 3.png
3.png
 4.png
4.png - 修改配置文件
编辑flume-env.sh文件,配置JDK目录
export JAVA_HOME=/opt/modules/jdk1.8.0_101
将hdfs的配置文件放到flume的conf目录中(要把搜集的数据放到hdfs中,需要找HADOOP_HOME)
 5.png
5.png - 在中hdfs写数据,需要添加相应的jar包
commons-configuration-1.6.jar
hadoop-auth-2.5.0-cdh5.3.6.jar
hadoop-common-2.5.0-cdh5.3.6.jar
flume的使用
- 监控hive.log日志文件,channel设置为memory(如果宕机,不能完全读取数据);sink设置为logger,表示把数据打印到flume的配置文件中。
source为exec,代表执行一个命令来监控文件
# define agent
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# define the source
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /opt/cdh-5.3.6/hive-0.13.1-cdh5.3.6/logs/hive.log
a1.sources.s1.shell = /bin/sh -c
#define the channel
a1.channels.c1.type = memory
# define the sink
a1.sinks.k1.type = logger
# source link channel,and sink link channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
运行
bin/flume-ng agent -c conf/ -n a1 -f conf/hive-mem-log.properties -Dflume.root.logger=INFO,console
测试结果
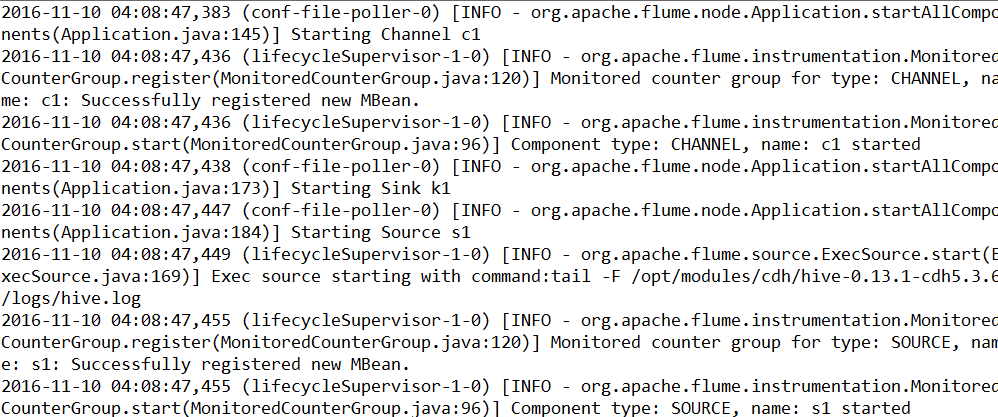
可以从启动的INFO中发现启动agent的
启动顺序为: channel->sink->source
关闭顺序为: source->sink->channel
- 还是监控hive.log,由于channel为内存的时候,当发生宕机的时候,将会丢失数据,可以将channel设置为file,保证数据的安全性,便于恢复。
# define agent
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# define the source
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /opt/modules/cdh/hive-0.13.1-cdh5.3.6/logs/hive.log
a1.sources.s1.shell = /bin/sh -c
#define the channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/datas/flume-ch/checkpoint
a1.channels.c1.dataDirs = /opt/datas/flume-ch/datadirs
# define the sink
a1.sinks.k1.type = logger
# source link channel,and sink link channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
checkpointDir是用来存储监控哪些目录
dataDirs用来存储数据文件,如果宕掉,且sink没有取走的话,可以从这个目录下面知道数据用来恢复
运行
bin/flume-ng agent -c conf/ -n a1 -f conf/channel-file.properties -Dflume.root.logger=INFO,console````
3. 将目标路径配置为hdfs
define agent
a1.sources = s1
a1.channels = c1
a1.sinks = k1
define the source
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /opt/cdh-5.3.6/hive-0.13.1-cdh5.3.6/logs/hive.log
a1.sources.s1.shell = /bin/sh -c
define the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000
define the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/hdfs
a1.sinks.k1.hdfs.fileType = DataStream
source link channel,and sink link channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
测试结果

4. 可以从上面的运行结果发现,存储到hdfs上的文件size很小,一般来说,不希望小文件太多,可以配置size的大小
define agent
a1.sources = s1
a1.channels = c1
a1.sinks = k1
define the source
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /opt/modules/cdh/hive-0.13.1-cdh5.3.6/logs/hive.log
a1.sources.s1.shell = /bin/sh -c
define the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000
define the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/size
a1.sinks.k1.hdfs.fileType = DataStream
表示隔多少秒生成一个新文件,设置为0,表名一直为一个文件
a1.sinks.k1.hdfs.rollInterval = 0
文件如果达到某个大小,则生成新文件
a1.sinks.k1.hdfs.rollSize = 10240
a1.sinks.k1.hdfs.rollCount = 0
source link channel,and sink link channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
测试结果

从上图可以发现不再是1KB就生成一个新文件了。
5. 可以把路劲设置为日期,还可以设置文件的前缀,然后结合hive中的分区表使用
define agent
a1.sources = s1
a1.channels = c1
a1.sinks = k1
define the source
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /opt/modules/cdh/hive-0.13.1-cdh5.3.6/logs/hive.log
a1.sources.s1.shell = /bin/sh -c
define the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000
define the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H-%M
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = hive-log
source link channel,and sink link channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
测试结果

6. 配置source监控文件夹,只要文件夹有文件生成,就为立即被source获取,不管是原来已经存在的,还是后面新生成的,都会被上传到hdfs中。
define agent
a1.sources = s1
a1.channels = c1
a1.sinks = k1
define the source
a1.sources.s1.type = spooldir
a1.sources.s1.spoolDir = /opt/datas/flume-ch/spdir
define the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000
define the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/spdir
a1.sinks.k1.hdfs.fileType = DataStream
source link channel,and sink link channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
测试结果

上传成功后,文件自动重命名,回家上后缀.COMPLETE

7. 可以用正则表达式,指定忽略某些文件名,对其不上传。
define agent
a1.sources = s1
a1.channels = c1
a1.sinks = k1
define the source
a1.sources.s1.type = spooldir
a1.sources.s1.spoolDir = /opt/datas/flume-ch/spdir
a1.sources.s1.ignorePattern = ([^ ]*.tmp$)
define the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000
define the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/spdir
a1.sinks.k1.hdfs.fileType = DataStream
source link channel,and sink link channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
这样写就可以忽略所有.tmp后缀的文件名,对其不上传,除非修改文件名不以.tmp结尾。还有个参数includePattern,可以设置需要包含的文件名。
8. 一个source多sink架构

因为有时候一份数据需要进行不同的数据分析,所以可以设置多sink结构,把数据上传的不同的框架和目录中。
define agent
a1.sources = s1
a1.channels = c1 c2
a1.sinks = k1 k2
define the source
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /opt/modules/cdh/hive-0.13.1-cdh5.3.6/logs/hive.log
a1.sources.s1.shell = /bin/sh -c
define the channel 1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/datas/flume-ch/check1
a1.channels.c1.dataDirs = /opt/datas/flume-ch/data1
define the channel 2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/datas/flume-ch/check2
a1.channels.c2.dataDirs = /opt/datas/flume-ch/data2
define the sink 1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/hdfs/sink1
a1.sinks.k1.hdfs.fileType = DataStream
define the sink 2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /flume/hdfs/sink2
a1.sinks.k2.hdfs.fileType = DataStream
source link channel,and sink link channel
a1.sources.s1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
测试结果


9. 当我们想动态的监控一个目录,还想监控这个目录里面的文件该如何实现? source使用taildirource模式,但是flume1.7之前是没有提供这个功能的,需要自己编译实现。这里不再赘述