浅析 DeepSeek 开源的 FlashMLA 项目
浅析 DeepSeek 开源的 FlashMLA 项目
DeepSeek 开源周 Day 1(2025 年 2 月 24 日)放出的开源项目——FlashMLA,是一款针对 Hopper 架构 GPU 高效多层级注意力 (Multi-Level Attention, MLA) 解码内核,专门为处理变长序列问题而设计。
趁热浏览一下:GitHub - deepseek-ai/FlashMLA
一、概述
传统的注意力计算方法在面对变长序列或长序列推理时,往往面临显存碎片和访存延迟等问题。针对这一点,FlashMLA 通过以下几个关键方向实现性能突破:
- 分页 KV 缓存管理:针对长序列推理中显存碎片严重的问题,FlashMLA 实现了一种基于 64-block 粒度的分页 KV 缓存,极大提高了显存利用率,缓解内存访问瓶颈。
- 基于 Hopper 架构的深度优化:利用 NVIDIA Hopper GPU 上的 SM90 架构特性,FlashMLA 借助 Tensor Memory Accelerator (TMA) 异步内存拷贝指令,实现 GDDR6 到共享内存(SRAM)的零拷贝传输,从而接近理论峰值带宽。
- 双模式执行引擎:为了适应不同输入序列长度的场景,FlashMLA 采用动态负载均衡算法,设计了双模式执行策略,即在短序列下采用计算优化模式,在长序列下采用内存优化模式,使得整体延迟大幅降低。
通过这些主要创新,FlashMLA 解决了长文本生成、实时对话和多模态模型中注意力计算效率低下的问题。
二、项目架构概览
FlashMLA 这个项目很精炼,代码量很小:
::: center
:::
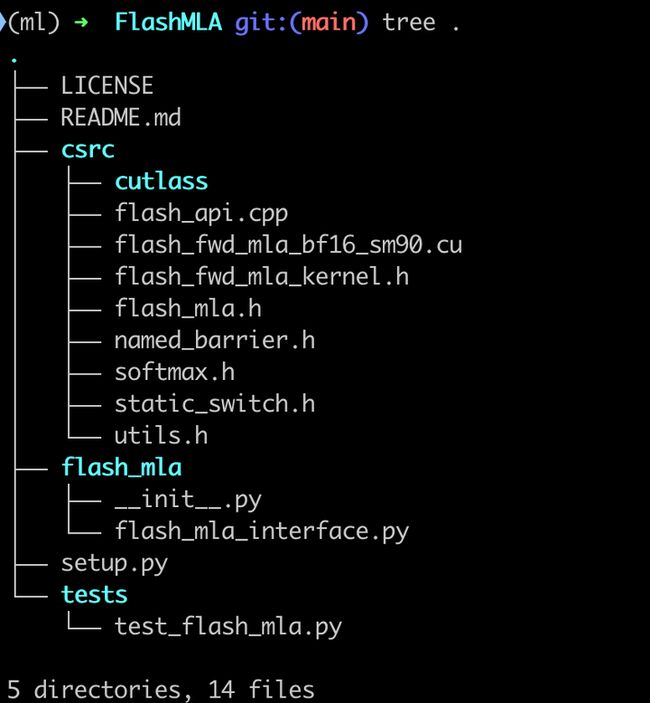
项目代码结构清晰,共分为以下几个主要模块:
- CUDA 内核层:位于
csrc/目录下,包含 FlashMLA 的核心实现文件,如flash_fwd_mla_bf16_sm90.cu和flash_fwd_mla_kernel.h。这些文件利用 CUDA 和 CUTLASS 库实现了对注意力计算的深度优化:flash_fwd_mla_bf16_sm90.cu:专为 Hopper 架构设计的 BF16 计算内核,通过模板实例化调用具体的内核函数。flash_fwd_mla_kernel.h:定义了主要的内核参数结构和模板,包括共享内存布局、矩阵乘法调度(TiledMma)、全局内存拷贝策略等。named_barrier.h、softmax.h、static_switch.h:提供硬件同步、混合精度 softmax 以及静态分支选择等辅助工具。cutlass/子模块:集成了 NVIDIA CUTLASS 库,支持高效矩阵运算。
- Python 接口层:位于
flash_mla/目录下,主要文件为flash_mla_interface.py。这一层为上层应用提供了简单易用的 API 封装,使得用户可以直接在 PyTorch 中调用 FlashMLA 内核:get_mla_metadata:负责根据输入的缓存序列长度和维度信息,生成调度元数据(tile_scheduler_metadata)和 block_table 的分割指标(num_splits)。flash_mla_with_kvcache:核心 API 函数,内部调用底层 CUDA 内核,完成注意力计算。函数中包括张量维度校验、CUDA 内核启动及返回结果封装等步骤。
- 内存管理子系统:位于
csrc/flash_api.cpp中,实现了分页 KV 缓存机制。这种设计使得对长序列的动态内存分配更加灵活,并通过硬件加速指令(如__ldg())提高内存访问效率。 - 计算调度系统:主要分布在
flash_fwd_mla_kernel.h中,使用 tile_scheduler_metadata 进行动态负载均衡。该系统通过分析输入序列长度,调整计算和内存预取策略,实现内存和计算优化模式的切换,以达到最佳的总体性能。
::: center
:::
三、技术实现细节解析
1. CUDA 内核模块的核心设计
模板元编程和 CUTLASS 应用
FlashMLA 内核广泛使用了模板元编程技术,使得内核能够在编译期完成类型和参数选择。以 Flash_fwd_kernel_traits_mla 为例,该模板定义了:
- 基本参数:包括注意力头维度(kHeadDim)、块大小(kBlockM 和 kBlockN)、和线程数量(kNThreads)。
- 共享内存布局:通过辅助函数
getSmemLayoutK()来确定共享内存中各数据块的存放方式。该函数利用if constexpr分支,保证内存访问对齐,例如:
if constexpr (headSizeBytes % 128 == 0 && headSizeBytes2 % 128 == 0) {
return GMMA::Layout_K_SW128_Atom<PrecType>{};
} else if constexpr (headSizeBytes % 64 == 0 && headSizeBytes2 % 64 == 0) {
return GMMA::Layout_K_SW64_Atom<PrecType>{};
} else {
return GMMA::Layout_K_SW32_Atom<PrecType>{};
}
这种选择机制保证了在不同的数据排列和对齐条件下,都能达到最高效的共享内存访问。
Warp Specialization 及双缓冲技术
FlashMLA 利用了 Warp Specialization 技术,将内核中的线程分成不同组:
- 计算组:负责实际的矩阵乘法和 softmax 计算。
- IO 组:负责加载 Q、K 数据到共享内存,并进行预取操作。
双缓冲设计在共享内存中维护两个 buffer,用于数据的交替加载和计算。在块切换时,内核可以预加载下一块数据,利用异步内存拷贝(cp.async 指令),从而隐藏内存延迟,大幅提升整体吞吐量。
异步拷贝和流水线调度
基于 Hopper GPU 的 TMA(Tensor Memory Accelerator)特性,FlashMLA 内核通过 cp.async 指令实现异步内存拷贝:
cp.async.ca.shared.global [addr], [reg], 128;
这种指令使得 GPU 能够在计算过程中同时加载数据,与传统同步内存拷贝相比能降低延迟。进一步,内核还设计了指令级流水线,以连续 overlapped 执行计算和内存传输,实现内存带宽与计算吞吐的最佳平衡。
2. 内存管理子系统解析
内存管理是 FlashMLA 的一大亮点,关键在于如何高效管理长序列下的 KV 缓存。FlashMLA 采用了分页 KV 缓存机制,关键思想如下:
- 64 Block 粒度:每个缓存块大小设定为 64 个元素(例如,对于 BF16 来说,每个元素 2 字节,64×576 即 72KB 级别内存),这一设计既能保证足够的数据并行度,又能避免因内存碎片产生的浪费。
- 动态内存映射:利用 BlockTable 结构,记录各序列当前已分配的内存块和对应的指针。内核在运行时,通过
__ldg()指令加速访问这张分页表,保证了极低的延迟。 - 零拷贝优化:内核在访问块数据时,采用基于常量缓存的只读访问模式,利用硬件的缓存优化技术降低全局内存访问开销,进一步提升内存带宽利用率。
3. Python 接口层与易用性考量
在 flash_mla_interface.py 中,FlashMLA 的 Python 接口提供了友好的 API 封装,使得用户可以轻松地将高性能 CUDA 内核整合到 PyTorch 模型中。主要函数包括:
- get_mla_metadata:接收输入的缓存序列长度、各头注意力数量等信息,调用底层 CUDA 库生成 tile_scheduler_metadata 和 num_splits。返回的数据用作后续 CUDA 内核调度与分块。
- flash_mla_with_kvcache:该函数是用户直接调用的接口。其内部首先对输入张量维度进行校验,再调用
flash_mla_cuda.fwd_kvcache_mla()启动 CUDA 内核。用户只需传入 query、KV 缓存、块表、缓存序列长度以及其他调度参数,即可获得注意力计算的输出和 softmax LSE(LogSumExp)。
这种设计不仅降低了使用门槛,同时隐藏了 CUDA 内核的复杂细节,使得主流深度学习框架的用户也能受益。
4. 计算调度系统与动态负载均衡
FlashMLA 在长序列推理过程中需处理数据的不均衡问题,因此设计了一套动态调度系统。该系统的核心在于利用 tile_scheduler_metadata 进行分块调度,确保各计算单元能够根据实际输入长度自动调整工作量。这种智能调度确保了在各种工作负载下都能达到最佳性能。
- 动态负载均衡:内核在启动时根据输入序列的长度和 batch 大小,动态计算最优的计算块数,并在内核执行过程中通过命名屏障(NamedBarrier)实现线程间细粒度同步。这样既减少了全局同步的开销,又确保了数据计算与内存预取的高效衔接。
- 双模式执行:调度系统根据输入序列的长度,自动在「内存优化模式」和「计算优化模式」之间切换:
- 当序列较长时,侧重内存预取和分页管理;
- 当序列较短时,则主要强调计算吞吐。
四、性能表现与优势
FlashMLA 不仅能够极大提高注意力计算的速度,同时还能有效降低推理延迟,提升用户体验。在性能上展现出惊人的表现:
- 内存带宽:在内存受限配置下,达到最高 3000 GB/s。
- 计算吞吐:在计算受限配置下,峰值可达 580 TFLOPS。
- 整体时延:针对长序列,端到端时延降低约 40%,这对于实时对话系统、大规模文本生成等场景意义重大。
五、与同生态位其他方案的对比
在注意力优化技术领域,当前主流方案还包括 FlashAttention-3、xFormers、FasterTransformer 等。下面对这些方案与 FlashMLA 进行简要比较(注意:数据可能有误差,需进一步验证):
::: center

:::
差异分析:
- 内存管理方式:FlashMLA 利用分页 KV 缓存大幅提高显存利用率,而 FlashAttention-3 则采用连续内存布局。对于长序列任务(例如超过 4K tokens 的生成任务),FlashMLA 的分页机制可以有效避免内存溢出,同时提高带宽利用率。
- 硬件适配性:FlashMLA 是专为 Hopper 架构设计,而 FlashAttention-3 则兼容性更强,支持 Ampere 架构。对于用户而言,选择哪种方案取决于所使用 GPU 的架构及预期负载。
- 执行模式与吞吐:FlashMLA 采用双模式执行引擎,根据实际序列长度切换内存和计算优化模式,这使得在长序列场景下能够获得较低延迟和较高吞吐,而其他方案在短序列或固定格式任务下可能更优秀。
整体来看,如果在长序列任务和跨模态任务中有较高要求,FlashMLA 是十分合适的选择;而在资源受限或需求多样的场景下,需根据实际硬件和应用需求进行权衡选择。
六、项目未来展望
尽管 FlashMLA 在技术上取得了巨大突破,但仍存在值得改进的地方。
- 硬件兼容性增强:当前 FlashMLA 主要针对 Hopper 架构,对于 A100 或 T4 等其他 GPU 架构,建议开发 fallback 内核。这样不仅可以拓宽用户群,还能在多种硬件平台上保持良好性能。
- 自动化调优工具:针对不同长度和批量的输入,内核参数(如分块大小 kBlockM、kBlockN)需要手动调优。未来可以考虑引入自动分块调优器,甚至基于强化学习算法动态选择最优参数,降低使用难度。
- 扩展数据精度支持:随着 FP8、INT8 等低精度计算的逐步普及,将 FlashMLA 扩展到支持量化计算,可以在保证性能的同时进一步提升吞吐,特别是在边缘设备部署时显得尤为重要。
- 改进代码可维护性和异常处理:目前内核代码高度模板化,虽然性能优秀但调试与维护难度较高。未来建议增加详细注释、API 类型注解以及全面的测试覆盖率,并设计出健壮的错误恢复机制,比如自动内存扩容方案。
- 分布式分页与异构计算支持:对于大规模分布式系统,跨多卡管理统一块表(利用 NCCL 等技术)以及 CPU-GPU 协同分页管理将成为亟待解决的问题。这样的扩展将使 FlashMLA 能够在超大规模模型(如超过百万 tokens)中发挥更大优势。
七、总结
FlashMLA 项目代表了注意力机制优化领域的最新突破,它采用分页 KV 缓存、Hopper TMA 异步拷贝以及双模式执行等技术,实现了以下目标:
- 高效长序列处理:突破传统内存管理瓶颈,在长文本生成与多模态应用中展现出极佳的性能表现。
- 硬件深度优化:利用最新 GPU 架构的特性,充分发挥硬件性能,达到极高的内存带宽利用率和计算吞吐。
- 智能调度与负载均衡:设计动态调度系统,根据不同输入自动选取最佳执行模式,兼顾内存与计算资源的高效利用。
FlashMLA 同时也面临一些挑战,包括较高的代码复杂度、对特定硬件架构的依赖以及未来扩展性不足等问题。总体来看,该项目在大模型及长序列任务中具有显著优势,适合追求极致性能的场景,如大语言模型预训练与微调、实时对话系统以及生物信息领域的大规模序列分析等。
FlashMLA 作为大模型时代的基础设施级项目,其技术突破和性能优化为深度学习社区带来了全新的思路。对于 GPU 性能极致追求者而言,FlashMLA 是不可多得的重要工具;而在长期维护和多平台扩展方面,则需要持续投入精力和技术资源进行完善。