Url编码解码
生活中的场景:
平时我们在浏览器上的“地址栏输入链接”、“点击form提交按钮”、“点击链接”等发起请求操作,浏览器在将http请求 发送出去前都会做一些处理:Url编码。如我们在地址栏输入:https://segmentfault.com/?name=你
而其实浏览器会先将‘你’编码成%E4%BD%A0才发送出去,如下图。其他请求操作亦然。

所以其实浏览器默默地帮我们做了好多事情,只是我们小白不知道而已。
那么为何浏览器要对发出的请求都先进行Url编码呢?原因如下:
熟悉Http协议的人都知道,Request和Response中是有好多特定意义的字符的,如=、?、/、:等等。Request请求达到server端要想被server正确解析处理,就需要保证 这些字符无异议,即不能迷惑了server。而我们平时发博客、朋友圈、说说、推特中是经常会输入这些 字符的,这样的请求如果直接发送出去,server根本无法识别出哪个=是 说说内容中的 还是 用在http协议的。 因此我们必须要解决这个 字符冲突 的问题。这就是Url编码的意义所在。
如http://localhost:8080/examples/servlets/servlet/test?n=?&&y==
其实我希望是这样的:n =?&,y==
可是?、&、=这些是保留字,server接收到后根本不知道怎么处理,往往就会报错。
Url编码解码原理过程
Url编码解码 只是针对非Ascii字符集 和 跟http协议中的保留字冲突(unsecure)的字符,而Ascii字符 是忽略的。

(1)拿字符串:“罗a志%晓”做例子
对于每一个字符,按照Utf-8字符编码格式得到字节,转成十六进制:
罗:非Ascii字符 ,0xE7BD97
a :Ascii字符 ,不处理
志:非Ascii字符,0xE5BF97
% :冲突字符 ,0x25
晓:非Ascii字符,0xE69993
(2)对每个字符的 十六进制格式 进行 每两个(即8bit,一个字节)用百分号%隔开
罗:非Ascii字符 ,0xE7BD97,%E7%BD%97
a :Ascii字符 ,不处理,不处理
志:非Ascii字符,0xE5BF97,%E5%BF%97
% :冲突字符 ,0x25,%25
晓:非Ascii字符,0xE69993,%E6%99%93
(3)综合得到:%E7%BD%97a%E5%BF%97%25%E6%99%93
(4)其实js中自带有Url编码解码 函数:window.encodeURI()和window.encodeURIComponent()
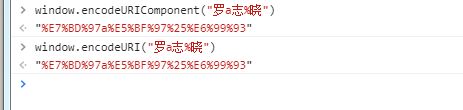
【后面会补一文细说两个函数的区别。】
浏览器Url编码过程
(1)先说说Url的组成
http://域名:端口/contextPath/servletPath/pathInfo?queryString
下图更直观:

(2)一般地,浏览器对PathInfo的url编码 都是 基于Utf-8 ,这主要是根据浏览器的设置;而
对于Get请求,QueryString则是根据ResponseHeader中的ContentType头中指定的字符集编码格式。
对于Post请求,body中也是根据ResponseHeader中的ContentType头中指定的字符集编码格式。
如果ResponseHeader中的ContentType头没有指定,那么一般地默认都是用Utf-8,如“在输入栏输入链接”的情况就是如此。
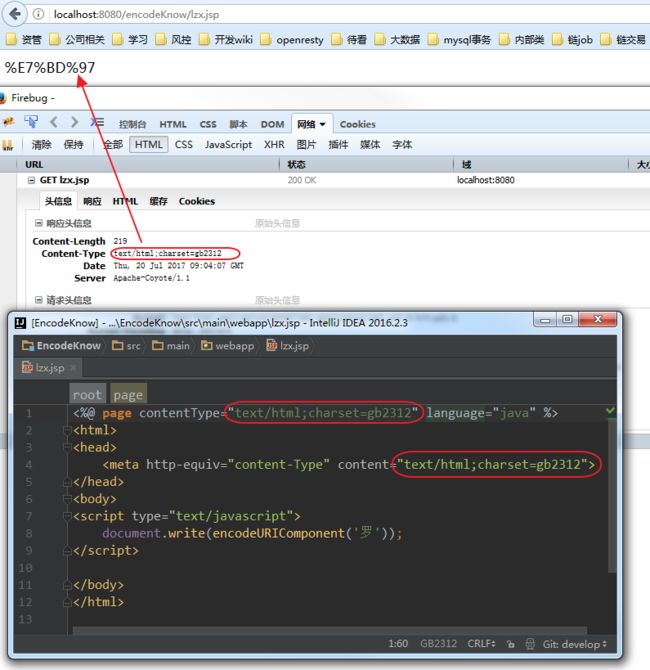
这里有个地方注意:Js自带的window.encodeURI()和window.encodeURIComponent()任何情况下都是基于Utf-8进行Url编码解码的(即使是Gb2312、GBK等编码的网页);而浏览器自己url编码解码的话,则是考虑根据RepponseHeader的ContentType(如果没有,则基于中指定的ContentType)!!
证明如下图:
(3)拿http://localhost:8080/examples/servlets/servlet/罗a志%晓?author=罗a志%晓 做例子:
发起请求的方式无论是“在输入栏输入”或“点击链接”:
你通过F12的控制台,可以看到实际发送出去的请求内容是这样的:"罗志晓"被编码了:
http://localhost:8080/examples/servlets/servlet/%E7%BD%97a%E5%BF%97%%E6%99%93?author=%E7%BD%97a%E5%BF%97%%E6%99%93

对于Post请求,就不多演示了。
有个疑问:
细心的同学可能发现:怎么%没有被url编码?浏览器本身并不会对这些 不安全字符(http协议保留字)进行编码,因为无法判断这些字符 哪些是用作 保留字的、那些是用户内容,同样,server接收到也是无法解析。因此我们需要自己用js代码对这些 不安全字符url编码。
同样,举文头的那个极端例子:
http://localhost:8080/examples/servlets/servlet/test?n=?&&y==
我们希望server能够这样处理的:n =?&,y ==。
如果我们就这样按下enter,你会发现 浏览器并不会对?&=编码 就发送出去了,因为它也无法识别哪个=、?、&号是用来分割的啊。浏览器无法识别,server当然也难以识别(报错)啊。