文/michaelgbw
import numpy,pandas
python这个语言有着天然的数据计算优势,numpy,scipy,pandas这些拓展的出现更是如虎添翼~更有ML的sklearn等,这里我们先打好基础。
# encoding=utf-8
from __future__ import division
import pandas as pd
import numpy as np
spark DF
说起pandas,我总会和spark做比较,spark将RDD转为DF,然后一句SQL搞定,不要太爽~
val str = "XXX,XXX,XXX,XXX"
val field = str.split(",")
.map(fieldName =>
StructField(fieldName, StringType, nullable = true))
val schema = StructType(field)
world.foreachRDD{
rdd =>
val rowRDD = rdd.map(a=> Row(a(1),a(2),a(3),a(4)))
val rechargeDF = sqc.createDataFrame(rowRDD, schema)
rechargeDF.registerTempTable("test")
var query = sqc.sql("select count(*) from test")
}
}
而且sql中可以添加UDF即用户自己的function,更是即为灵活
大家参考这个 http://www.tuicool.com/articles/yiMneyI
pandas
我们言归正传
来来来,我们跟着这个一起学习
# encoding=utf-8
from __future__ import division
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import scipy as sy
dates = pd.date_range('20170228',periods=10)#从2017-02-28开始共10天
#randn(10,4)正太分布
df = pd.DataFrame(np.random.randn(10,4), index=dates, columns=list('ABCD'))
#randint整型随机
df = pd.DataFrame(np.random.randint(1,10,size=(10,4)), index=dates, columns=list('ABCD'))
#可以自己制定DF
df2 = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
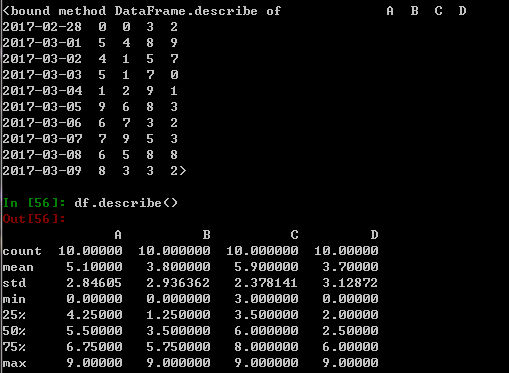
df.describe()
#count 每列的数量
#mean 每列的均值
#std 每列的标准差
#std 每列的标准差
#XX% 每列的个分位数
#max 每列的最大值
pd.read_csv() #读scv
df.to_csv('xx.csv') #输出为scv
df.sort_index(axis=1, ascending=False) #按列关键字排序
df.sort_values(by='B',ascending=False) #按值排序
df3 = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
df.groupby(['A','B']).sum() #select sum(`A`),sum(`B`) from df group by A,B
df.groupby(['A']).count() #select count(`A`) from df group by A
而我们整理好的dataframe 转化为其他数据类型也十分方便。

numpy,scipy,pandas区别
- numpy主要是用于数值计算,包括sin、cos、exp等,同时提供N维数据对象;
- pandas提供了数据结构和数据分析工具;
- scipy 则是基于numpy,提供了一个在python中做科学计算的工具集,也就是说它是更上一个层次的库;
结语
先知道有这个东西,然后多在实际中应用哦~