
文/Bruce.Liu1
1.运算符
本章节主要说明Python的运算符。举个简单的例子 4 +5 = 9 。 例子中,4 和 5 被称为操作数,"+" 称为运算符。
Python语言支持以下类型的运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 成员运算符
- 身份运算符
- 位运算符
- 运算符优先级
1.1.算术运算
- 以下假设变量: a=10,b=20:
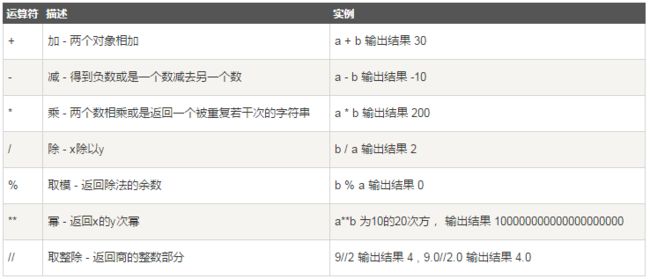
以下运算结果是多少?
>>> 10 / 3 + 2.5
1.2.比较运算
- 以下假设变量: a=10,b=20:
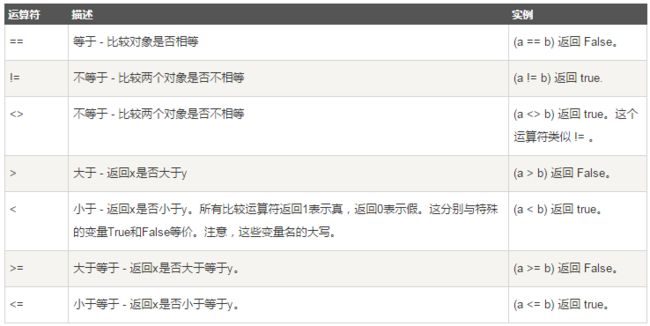
Python 3以后丢弃<>方式
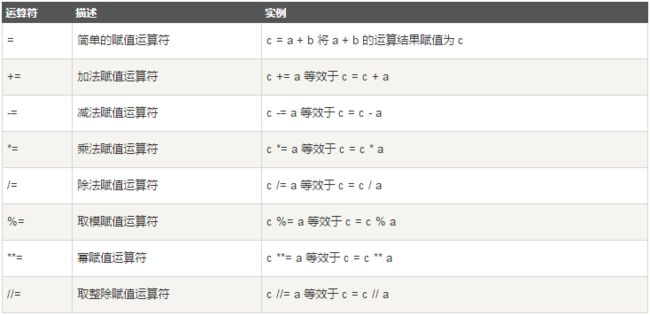
1.3.赋值运算
- 以下假设变量a为10,变量b为20:
1.4.逻辑运算
- Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:

- or(或)示例
>>> a - b > 0 or b == a + 10
True
- and(与)示例
>>> a + 10 == b and b - a == 10
True
- not(非)示例
>>> a
10
>>> not a
False
1.5.成员运算
- 除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。

- 判断成员是否在字符串、列表、元组中
>>> res_list = range(10)
>>> 5 in res_list
True
- 判断成员是否不在字符串、列表、元组中
>>> test_code = 'Hello World'
>>> 'L' not in test_code
True
1.6.身份运算

- is示例验证两个标识符来自同一个引用
>>> def main():
... pass
...
>>> result = main()
>>> result is None
True
- 以下代码和"sql result"做 == is运算返回是否相等
>>> a = 'sql result'
>>> a is 'sql result'
False
>>> a == 'sql result'
True
- is not 示例验证两个标识符来自不同引用
>>> a is not 'sql result'
True
1.7.位运算
- 按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:

- 下表中变量 a 为 60,b 为 13,二进制格式如下:
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011
- 利用 bin() eval() int()方法,方便二、十进制的转换
>>> a = 60
>>> binary_a = bin(a)
'0b111100'
>>> eval(binary_a)
60
>>> int(binary_a,2)
60
1.8.运算符优先级
- 以下表格列出了从最高到最低优先级的所有运算符:

简单温习一下小学数学
>>> a = 20
>>> b = 10
>>> c = 15
>>> d = 5
>>> e = 0
>>> e = (a + b) * c / d
>>> print "(a + b) * c / d 运算结果为:", e
(a + b) * c / d 运算结果为: 90
>>> e = ((a + b) * c) / d
>>> print "((a + b) * c) / d 运算结果为:", e
((a + b) * c) / d 运算结果为: 90
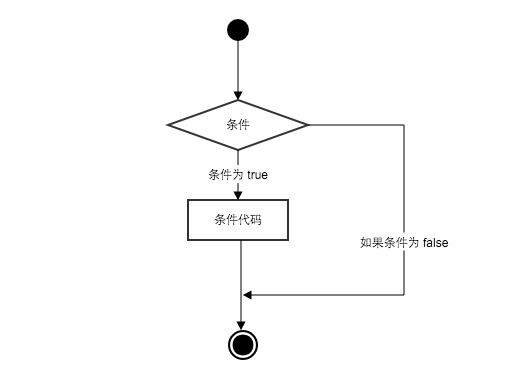
2.条件语句
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
可以通过下图来简单了解条件语句的执行过程:
2.1.用户登录验证
2.1.1.基本控制子句
- 用户输入账户名和密码,根绝输入的对错提示不同的消息
#!/bin/env python
#! _*_ coding:utf-8 _*_
import getpass
username = 'liu'
password = '745'
users = raw_input('Enter your name: ')
pwds = getpass.getpass('password : ')
if username == users and password == pwds :
print('Welcome user {_name}'.format(_name = users))
else:
print('invalid username or password!')
2.1.2.多重控制子句
2.1.2.1.多重控制子句-1
- 猜年龄程序,基于用户输入的年龄返回是否正确,及提示差距
问:当输入18的时候,到底是返回那个结果?
#!/bin/env python
# _*_ coding:utf-8 _*_
__author__ = "Bruce"
age_of_python = 30
guess_age = raw_input('Enter age: ')
if guess_age < age_of_python:
print('think bigger!')
elif guess_age == 18:
print('成年了,骚年!')
elif guess_age > age_of_python:
print('think smaller!')
else:
print('yes. you got it.')
现实总是这么的让人茫然,结果总是太出乎人的意料,think smaller!,python BUG?
# python 3_guess.py
Enter age: 18
think smaller!
2.1.2.1.多重控制子句-2
raw_input 函数接收的参数都将以str类型返回
input 函数将接收的参数数据类型原样返回
3.x python 取消了input方法,raw_input方法改成成input()
- 此时在问:当输入18的时候,到底是返回那个结果?
#!/bin/env python
# _*_ coding:utf-8 _*_
__author__ = "Bruce"
age_of_python = 30
#guess_age = input('Enter age: ')
guess_age = int(raw_input('Enter age: '))
if guess_age < age_of_python:
print('think bigger!')
elif guess_age == 18:
print('成年了,骚年!')
elif guess_age > age_of_python:
print('think smaller!')
else:
print('yes. you got it.')
3.循环语句
循环语句允许我们执行一个语句或语句组多次,下面是在大多数编程语言中的循环语句的一般形式:

- Python提供了for循环和while循环

- 循环控制语句可以更改语句执行的顺序。Python支持以下循环控制语句:

3.1.loop循环
3.1.1.简单的Loop循环
>>> for i in range(10):
... print 'Loop:',i
...
Loop: 0
Loop: 1
Loop: 2
Loop: 3
Loop: 4
Loop: 5
Loop: 6
Loop: 7
Loop: 8
Loop: 9
3.1.2.循环控制语句
循环控制语句可以更改语句执行的顺序
3.1.2.1.循环控制语句continue
continue子句的作用:停止并跳出当前本次循环,执行下一次循环
打印1到100数字,打印到50的时候显示特殊信息
>>> for i in range(100):
... if i == 50:
... print 'I have got to the round 50th!'
... continue
... print i
3.1.2.2.循环控制语句break
break子句的作用:终止循环,并跳出整个循环体
打印1到100数字,打印到50的时候显示信息并停止程序
>>> for i in range(100):
... if i == 50:
... print 'I have got to the round 50th!'
... break
... print i
3.1.2.3.循环控制语句pass
仅仅是为了是代码保持语法完整性的.
该代码,竟不能够执行,因为python认为有从属关系的代码块,就必须有子代码
>>> for i in range(10):
...
File "", line 2
^
IndentationError: expected an indented block
改成这种方法即可。这会非常有用。
>>> for i in range(10):
... pass
...
3.2.while 循环
3.2.1.无限循环
# !/bin/env python
count = 0
while True:
print 'loop:',count
count +=1
3.2.2.条件循环
打印1到100数字,打印到50的时候显示特殊信息,打印到70停止程序
#!/bin/env python
# _*_ coding:utf-8 _*_
__author__ = "Bruce"
counter = 1
while True:
counter += 1
if counter == 50:
print 'I have got to the round 50th!'
continue
elif counter > 70:
break
print counter
3.3.嵌套循环
- 九九乘法表
>>> for i in range(1,10):
... for j in range(1,10):
... print "{} x {} = {}".format(i, j, i * j)
4.字符串操作
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。和其他语言一样字符串是不可修改的。
4.1.字符串基本操作
4.1.1.声明字符串
创建字符串很简单,只要为变量分配一个值即可。例如:
>>> msg = 'Hello World'
4.1.2.单引号、双引号
python中没有字符串的引用符 双引号 " 、单引号'。没有强引用、弱引用之说,有些情况确需要不懂的引用方式
示例一
>>> 'hello,world!'
'hello,world!'
示例二 这种方式明显是语法错误。如何表示我们想要表达的意思呢?
>>> 'Let's go!'
File "", line 1
'Let's go!'
^
SyntaxError: invalid syntax
示例三 通过双引号表示
>>> "Let's go!"
"Let's go!"
示例四 或者通过转移符 \将 Let's转转成普通字符
>>> 'Let\'s go!'
"Let's go!"
4.1.3.字符串拼接
>>> x= 'Hello,'
>>> y = 'world!'
>>> x + y
'Hello,world!'
4.1.4.访问字符串的值
Python访问子字符串,可以使用方括号来截取字符串,如下实例:
- 默认(下标0开始);[0:5]表示从下标0开始匹配,匹配到5结束,这种方式也叫切片。(切片search数据的方式是:顾头不顾尾)
>>> msg = 'Hello World'
>>> msg[0]
'H'
>>> msg[0:5]
'Hello'
4.2.转义字符
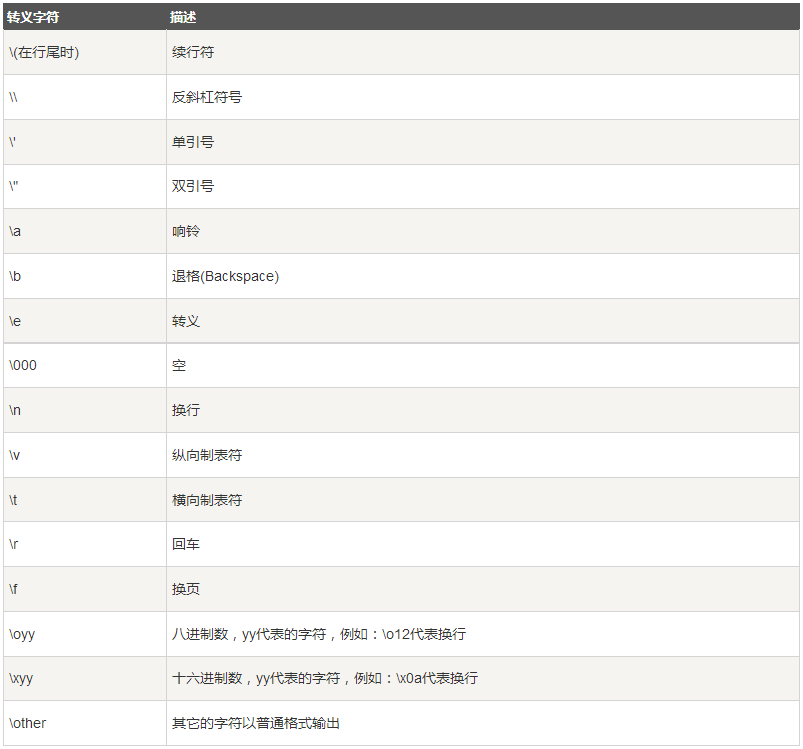
4.3.字符串运算符
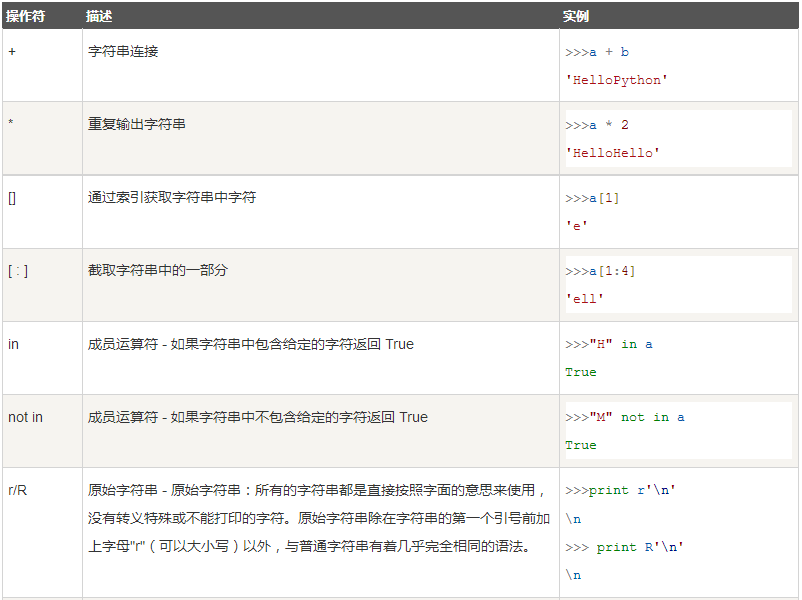
4.5.字符串格式化
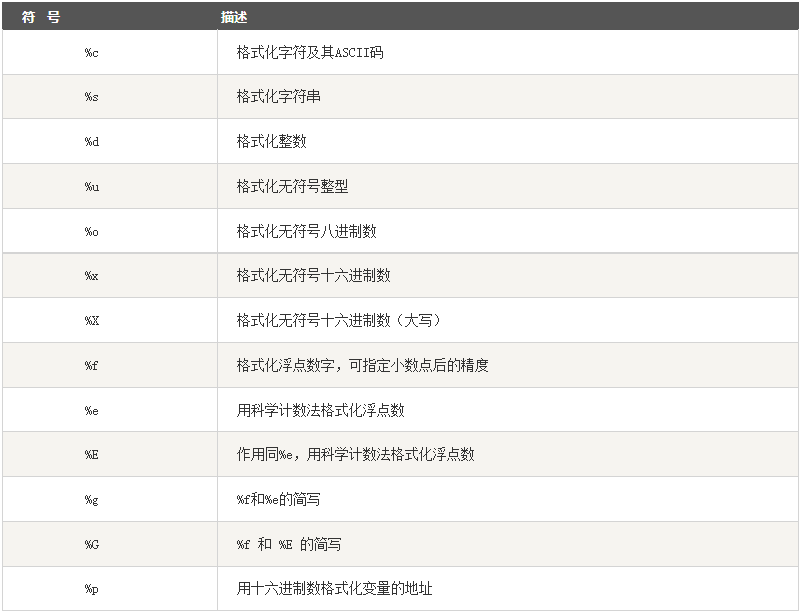
4.6.字符串内置方法
字符串方法是从python1.6到2.0慢慢加进来的——它们也被加到了Jython中。
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
- 获取帮助信息
help的时候方法不需要加括号
>>> msg = 'hello world'
>>> help(msg.capitalize)
- 首字母大写
>>> msg.capitalize()
'Hello world'
- 集中对齐
>>> msg.center(15 )
' hello world '
>>> msg.center(15 ,'#')
'##hello world##'
- 统计输入参数出现的次数
>>> msg.count('l')
3
- 编码成bytes格式
>>> msg.encode()
'hello world'
- 判断字符串结尾是否包含输入参数
>>> msg.endswith('world')
True
- 自动以制表符的长度
>>> text = 'hello\tworld'
>>> print text
hello world
>>> text.expandtabs(10)
'hello world'
- 返回字符串位置,没有则返回-1(默认下标0开始自左向右find,找到就返回)
>>> msg.find('l')
2
>>> msg.find('x')
-1
- 格式化字符串
第一种写法
>>> cmd = "mysql -h{ip} -P{port} -u{user} -p{passs}".format(ip='localhost',port=3306,user='mysql',passs='buzhidao')
>>> cmd
'mysql -hlocalhost -P3306 -umysql -pbuzhidao'
第二种写法
>>> cmd = "mysql -h{0} -P{1} -u{2} -p{3}".format('localhost',3306,'mysql','buzhidao')
>>> print cmd
mysql -hlocalhost -P3306 -umysql -pbuzhidao
第三种写法
>>> cmd = "mysql -h{} -P{} -u{} -p{}".format('localhost',3306,'mysql','buzhidao')
>>> cmd
'mysql -hlocalhost -P3306 -umysql -pbuzhidao'
- 返回字符串位置,没有则报错(多个重复值时,找到第一个就返回)
>>> msg.index('l')
2
>>> msg.index('a')
Traceback (most recent call last):
File "", line 1, in
ValueError: substring not found
- 判断是否是标准字符(0-9,a-Z)
>>> msg.isalnum()
False
>>> '09aZ'.isalnum()
True
- 判断是否是字母(a-Z)
>>> 'asdf'.isalpha()
True
>>> 'as21'.isalpha()
False
- 判断是否是数字(0-9)
>>> '123'.isdigit()
True
- 判断是否是小写
>>> msg.islower()
True
- 判断是否是空格
>>> s = ' '
>>> s.isspace()
True
- 判断是否是首字母大写
>>> _msg = 'Hello World'
>>> _msg.istitle()
True
- 判断字符串是否全部是大写
>>> _msg = 'TEST CODE'
>>> _msg.isupper()
- 将序列中的元素以指定的字符连接生成一个新的字符串
>>> tuple_res = ('Bruce','BJ')
>>> '#'.join(tuple_res)
'Bruce#BJ'
- 显示长度,不够时右边用空格填充
>>> msg.ljust(12)
'hello world '
- 返回字符串小写格式
>>> _msg.lower()
'test'
- 去掉左边的空格回车符
>>> text = '\n\taa'
>>> print text
aa
>>> text.lstrip()
'aa'
- 默认从左侧开始匹配;返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
>>> names = 'Burce.Liu'
>>> names.partition('.')
('Burce', '.', 'Liu')
- 字符串替换,默认全面替换
>>> info = '***** hotle'
>>> hotel = info.replace('*','星')
>>> print hotel
星星星星星 hotle
- 返回字符串位置,没有则返回-1
默认(下标0开始) 自左向右find,找到最右侧的在返回
>>> msg
'hello world'
>>> msg.rfind('l')
9
>>> msg.find('a')
-1
- 从右至左返回字符串位置,没有则报错(多个重复值时,找到第一个就返回)
>>> msg.rindex('l')
9
- 显示长度,不够时左边用空格填充
>>> msg.rjust(12)
' hello world'
- 从右边开始切分,返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
>>> url = 'www.hanxiang.com'
>>> url.rpartition('.')
('www.hanxiang', '.', 'com')
- 从右侧开始,将字符串默认以空格分割,分割后以list的形势返回
>>> msg.rsplit()
['hello', 'world.', 'none..']
- 去掉右边的空格回车符
>>> test = '\n\ttile......\n\t'
>>> print test.rstrip()
tile......
- 将字符串默认以空格分割,分割后以list的形势返回
>>> names.split('.')
['Burce', 'Liu']
- 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表
>>> info = '123\n456\n789'
>>> info.splitlines()
['123', '456', '789']
- 判断字符串首部是否包含参数值
>>> ftp_cmd = 'get file'
>>> ftp_cmd.startswith('get')
True
- 默认脱掉两边的空格回车符
>>> test = '\n\ttile......\n\t'
>>> print test
tile......
>>> test.strip()
'tile......'
- 对字符串的大小写字母进行转换
>>> info = 'Test Code!'
>>> info.swapcase()
'tEST cODE!'
- 返回字符串首字母大写
>>> msg.title()
'Hello World. None..'
- 方法根据参数table给出的表(包含 256 个字符)转换字符串的字符
>>> from string import maketrans
>>> intab = 'a'
>>> outtab = '1'
>>> # str.translate(table[, deletechars]);
>>> # table -- 翻译表,翻译表是通过maketrans方法转换而来。
>>> # deletechars -- 字符串中要过滤的字符列表。
>>> trantab = maketrans(intab, outtab)
>>> str = "a this is string example....wow!!!";
>>> print str.translate(trantab)
1 this is string ex1mple....wow!!!
- 返回字符串的大写形式
>>> msg.upper()
'HELLO WORLD. NONE..'
- 方法返回指定长度的字符串,原字符串右对齐,前面填充0。
>>> #返回一个值的ASCII映射值
>>> ord('2')
50
>>> #将50转换成二进制方式表示
>>> bin(ord('2'))
'0b110010'
>>> #用zfill方法填充默认不够的0
>>> binary_num.zfill(10)
'000b110010'
4.7.字符串的进阶
- 返回变量的类型
>>> type(msg)
- 返回最大值
>>> msg = 'my name is Burce1.'
>>> max(msg)
'y'
- 返回最小值
>>> min(msg)
' '
- 取长度
>>> len(msg)
18
- 数据类型转换-int
>>> one = '1'
>>> num1 = int(one)
>>> type(num1)
- 数据类型转换-str
>>> numtwo = str(num1)
>>> type(numtwo)
- ascii转换-1(str -> ascii)
>>> ord('a')
97
- ascii转换-2(ascii -> str)
>>> chr(97)
'a'
- 比较两个值的大小
>>> a = 'z'
>>> b = 'a'
>>> cmp(a,b)
1
>>> cmp(b,a)
-1
- 为每一个元素添加一个ID
>>> import string
>>> string.lowercase
'abcdefghijklmnopqrstuvwxyz'
>>> for i in string.lowercase:
... print string.lowercase.index(i),i
...
0 a
1 b
2 c
3 d
4 e
5 f
6 g
7 h
8 i
9 j
10 k
11 l
12 m
13 n
14 o
15 p
16 q
17 r
18 s
19 t
20 u
21 v
22 w
23 x
24 y
25 z
- 想合并一组序列如何做
>>> nums = ('Bruce',27,'erha',1,'QQ',23)
>>> ','.join(nums)
Traceback (most recent call last):
File "", line 1, in
TypeError: sequence item 1: expected string, int found
尝试一下代码
>>> nums = ('Bruce',27,'erha',1,'QQ',25)
>>> result = ''
>>> for i in nums:
... if type(i) is int:
... result += '{},'.format(str(i))
... continue
... result += '{},'.format(i)
...
>>> result
'Bruce,27,erha,1,QQ,25,'
5.列表操作
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。并且列表内的数据类型灵活多变。
列表(list)具有一下几个特点:
- 任意对象的有序集合
- 可变的序列
有一个需求需要存放班级所有同学的姓名,如果有同学休学或其他原因造成不能继续上课,存放数据的结构中还需要对应的维护,如何存放数据呢?
- 这种写法显然不能灵活的维护更新数据,那么此时就引入了list数据类型
>>> grade = 'erha,eric,Bruce,tom'
其实通过刚才的知识就能将字符串转换成list,那么此时grade_list就变得很好维护更新了
>>> grade_list = grade.split(',')
>>> grade_list
['erha', 'eric', 'Bruce', 'tom']
5.1.列表的基本操作
5.1.1.定义列表
name_list = ['Bruce','erha','tom','Yang']
5.1.2.访问列表
- 获取list元素,默认下标0是第1个位置,以此类推
>>> name_list[0]
'Bruce'
>>> name_list[-1]
'Yang'
5.1.3.切片
如果说想一次性访问list中多个元素如何做呢?

- 取下标1~4的元素(包括1,不包括4)
>>> names = ['Bruce','tom','jack','Yang','QQ']
>>> names[1:4]
['tom', 'jack', 'Yang']
- 取下标2~-1的元素(-1是元素中最右侧的下标)
>>> names[2:-1]
['jack', 'Yang']
- 从头开始取,取到下标3
>>> names[:3]
['Bruce', 'tom', 'jack']
>>> names[0:3]
['Bruce', 'tom', 'jack']
- 去最后3下标的元素
>>> names[-3:]
['jack', 'Yang', 'QQ']
#这种是错误的,因为-1在尾部不能被包含
>>> names[-3:-1]
['jack', 'Yang']
- 取下标3之前的元素,每隔一个元素,取一个
>>> names[:3:2]
['Bruce', 'jack']
- 也可以基于切片,指定下标2位置插入
>>> names[2:2] = ['wang da chui']
>>> names
['Bruce', 'tom', 'wang da chui', 'jack', 'Yang', 'QQ']
5.2.列表的内置方法
- 列表末尾追加元素
>>> names = ['Bruce', 'tom', 'wang da chui', 'jack', 'Yang', 'QQ']
>>> names.append('QQ')
- 统计元素在列表中出现的个数
>>> names.count('QQ')
2
- 扩展列表
>>> names = ['Bruce', 'tom', 'wang da chui', 'jack', 'Yang', 'QQ']
>>> names.extend(range(10))
>>> print names
等于以下方式
>>> names += range(10)
>>> print names
- 返回该元素的位置,无则抛异常,并且匹配第一个元素即返回
>>> names.index('QQ')
5
>>> names.index('Tom')
Traceback (most recent call last):
File "", line 1, in
ValueError: list.index(x): x not in list
- 指定元素下标插入
>>> names.insert(4,'新来的')
>>> print names[4]
新来的
- 指定下标删除元素并返回删除的元素,默认不指定删除最后一个元素
>>> names.pop(4)
'\xe6\x96\xb0\xe6\x9d\xa5\xe7\x9a\x84'
>>> names.pop()
4
- 删除第一次出现的改元素
>>> names.remove('QQ')
- 倒序
>>> names.reverse()
>>> names
[3, 2, 1, 0, 'QQ', 'Yang', 'jack', 'wang da chui', 'tom', 'Bruce']
- 排序
>>> names.sort()
>>> names
[0, 1, 2, 3, 'Bruce', 'QQ', 'Yang', 'jack', 'tom', 'wang da chui']
倒序、排序都是基于首字符ascii码的大小进行的
5.3.列表的高级进阶
5.3.1.Enumerate枚举
enumerate在循环的同时直接访问当前的索引值
>>> for k, v in enumerate(names):
... print k, v
...
0 0
1 1
2 2
3 3
4 Bruce
5 QQ
6 Yang
7 jack
8 tom
9 wang da chui
5.3.2.找出列表中的最大值
>>> import random #随机模块,后面展开讲解
>>>
>>> sequences = range(15)
>>> random.shuffle(sequences)
>>> d = -1
>>> for i in sequences:
... if i > d:
... d = i
...
>>> print d
14
5.3.3.列表的复制
5.3.3.1.潜复制
- 一维数据潜复制验证,
>>> import copy
>>> names = ['Bruce', 'Eric', 'goods cat!']
>>> names2 =copy.copy(names)
>>> names[1] = 'eric'
>>> print names
['Bruce', 'eric', 'goods cat!']
>>> print names2
['Bruce', 'Eric', 'goods cat!']
- 二维数据或多维数据中潜复制的区别
但是二维列表中发现,其实浅复制并没有真正的复制一个单独的列表,而是指向了同一个列表的指针,这就是潜复制;二维数据时,潜复制并不会完全的复制一个副本
>>> shopping = [['Iphone',5800],['Nike',699],'buy']
>>> copy_shopping = copy.copy(shopping)
>>> shopping[0][0]
'Iphone'
>>> shopping[0][1] = 5699
>>> print shopping
[['Iphone', 5699], ['Nike', 699], 'buy']
>>> print copy_shopping
[['Iphone', 5699], ['Nike', 699], 'buy']
- 潜复制也并非鸡肋,我们看一场景:
父子卡账户拥有相同的一个卡号和金额,但是名字不同,发生扣款时金额必须同时扣款
>>> blank_user = ['names',['blank_name','card_type',0]]
>>> Tom = ['犀利哥',['光大','储值卡',800]]
>>> jery = copy.copy(Tom)
>>> jery[0] = '凤姐'
>>> jery[1][2] = 800 - 699
>>> print jery[0],jery[1][2]
凤姐 101
>>> print Tom[0],Tom[1][2]
犀利哥 101
5.3.3.2.深复制
- 深复制才是真正的将多维元素进行完全的copy(类似于软连接、硬链接)
>>> shopping = [['Iphone',5800],['Nike',699],'buy']
>>> deepcopy_shopping = copy.deepcopy(shopping)
>>> shopping[0] = ['Iphone Plus','8800']
>>> shopping
[['Iphone Plus', '8800'], ['Nike', 699], 'buy']
>>> deepcopy_shopping
[['Iphone', 5800], ['Nike', 699], 'buy']
5.3.4.列表的转换
- str转换list
>>> import string
>>> result = string.uppercase
>>> list_res = list(result)
>>> print list_res
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
- list转换str
str方法仅仅是将数据结构外面用引号,这并不是我们想要的结果
>>> str(list_res)
"['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']"
- 正确的姿势
>>> ''.join(list_res)
'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
补充
- zip拉链
两个列表长度不一致,zip拉链的时候,自动截取一致
>>> a = [1, 2, 3, 4]
>>> b = [5, 6, 7, 8, 9]
>>> zip(a,b)
[(1, 5), (2, 6), (3, 7), (4, 8)]
两遍元数量一样的效果
>>> a.append('new')
>>> zip(a,b)
[(1, 5), (2, 6), (3, 7), (4, 8), ('new', 9)]
- map方法
如果list长度不一致,则用None补充
>>> b.append(10)
>>> map(None,a,b)
[(1, 5), (2, 6), (3, 7), (4, 8), ('new', 9), (None, 10)]
6.元组操作
元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字、函数或其他对象的返回结果都是元组形式
元组(tuple)具有以下几个特点:
- 任意对象的有序集合
- 不可变的序列
6.1.元组的基本操作
6.1.1.声明一个元组
>>> db_res = ('as','the','is','at','go')
6.1.2.访问元组
>>> db_res[0]
'as'
因为元组是只读的所以没有过多关于修改的内置函数,也不支持修改元组中的元素
>>> db_res[0] = 'Change'
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object does not support item assignment
6.2.元组的内置方法
- 统计元素出现的次数
>>> db_res.count('as')
1
- 返回元素的下标位置
>>> db_res.index('at')
3
补充
- tuple -> list
>>> list_db_res = list(db_res)
>>> print list_db_res
['as', 'the', 'is', 'at', 'go']
- list -> tuple
>>> db_res_2 = tuple(list_db_res)
>>> print db_res_2
('as', 'the', 'is', 'at', 'go')
- tuple -> str
result_tuple = ('Tablespace->', 'INDEX_PAY', 'TotalSize->', 69632, 'FreeSize->', 14293.0625, 'UsedSize->', 55338.9375, 'FreePencent->', 20.52)
>>> tmp_res = ''
>>> for i in result_tuple:
... tmp_res += str(i)
>>> print tmp_res
Tablespace->INDEX_PAYTotalSize->69632FreeSize->14293.0625UsedSize->55338.9375FreePencent->20.52
7.字典操作
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
字典(dict)具有以下几个特点:
- 任意对象的无序集合
- 可变的序列
- Search元素效率极高
为什么dict查找速度这么快?因为dict的实现原理和查字典是一样的。假设字典包含了1万个汉字,我们要查某一个字,一个办法是把字典从第一页往后翻,直到找到我们想要的字为止,这种方法就是在list中查找元素的方法,list越大,查找越慢。
第二种方法是先在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字,无论找哪个字,这种查找速度都非常快,不会随着字典大小的增加而变慢。
dict就是第二种实现方式,给定一个名字,比如'Michael',dict在内部就可以直接计算出Michael对应的存放成绩的“页码”,也就是95这个数字存放的内存地址,直接取出来,所以速度非常快。
你可以猜到,这种key-value存储方式,在放进去的时候,必须根据key算出value的存放位置,这样,取的时候才能根据key直接拿到value。
- 假设要根据同学的名字查找对应的成绩,如果用list实现,需要两个list
给定一个名字,要查找对应的成绩,就先要在names中找到对应的位置,再从scores取出对应的成绩,list越长,耗时越长。
>>> names = ['Michael', 'Bob', 'Tracy']
>>> scores = [95, 75, 85]
- 如果用dict实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩,无论这个表有多大,查找速度都不会变慢。用Python写一个dict如下:
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d['Michael']
95
7.1.字典的基本操作
7.1.1.声明一个字典
- 如创建一个员工信息
>>> contacts = { '3951' : ['Bruce','IT','DBA'], '3091' : ['Jack','HR','HR'], '5122' : ['BlueTShirt','Sales','SecurityGuard'] }
7.1.2.访问字典中的元素
>>> contacts['3951'][0]
'Bruce'
7.1.3.添加字典中的元素
- 没有key,默认就是添加
>>> contacts['5927'] = ['Tang','BUG','土豪不需要职业']
>>> print contacts['5927'][2]
土豪不需要职业
7.1.4.修改字典中的元素
- 存在的key,就是修改
>>> contacts['5927'][0] = 'TangYan'
>>> contacts['5927'][0]
'TangYan'
7.2.字典的内置方法
7.2.1.清空字典
>>> contacts.clear()
7.2.2.潜复制字典
- 和list一样潜复制这对二维或以上多维数据结构时,不是全完数据副本的拷贝
>>> copy_contacts = contacts.copy()
>>> contacts['3091'][0] = 'erha'
>>> contacts
{'3951': ['Bruce', 'IT', 'DBA'], '3091': ['erha', 'HR', 'HR'], '5122': ['BlueTShirt', 'Sales', 'SecurityGuard']}
>>> copy_contacts
{'3951': ['Bruce', 'IT', 'DBA'], '3091': ['erha', 'HR', 'HR'], '5122': ['BlueTShirt', 'Sales', 'SecurityGuard']}
- 深度复制
>>> deepcopy_contacts = copy.deepcopy(contacts)
>>> contacts
{'3951': ['Bruce', 'IT', 'DBA'], '3091': ['erha', 'HR', 'HR'], '5122': ['BlueTShirt', 'Sales', 'SecurityGuard']}
>>> contacts['3091'][0] = 'Jack'
7.2.3.初始化dict
- 和潜复制一样都是有二级结构指针问题
>>> dict_module = dict.fromkeys(['BJ','SH','GZ'],['domain',{'module':'example.com'}])
>>> for k in dict_module: #遍历字典
... print k,dict_module[k]
...
SH ['domain', {'module': 'example.com'}]
GZ ['domain', {'module': 'example.com'}]
BJ ['domain', {'module': 'example.com'}]
7.2.4.获取dict的value
- 获取字典中的value,找不到不抛出异常
>>> contacts.get('3951')
['Bruce', 'IT', 'DBA']
>>> contacts.get(3951)
7.2.5.判断dict中的key是否存在
>>> contacts.has_key(3951)
False
>>> contacts.has_key('3951')
True
7.2.5.将dict转换成list
- 一般用于遍历字典使用,我们后面介绍语法及效率问题
>>> contacts.items()
[('3951', ['Bruce', 'IT', 'DBA']), ('3091', ['Jack', 'HR', 'HR']), ('5122', ['BlueTShirt', 'Sales', 'SecurityGuard'])]
7.2.6.返回字典的所有Key
>>> contacts.keys()
['3951', '3091', '5122']
- 判断成员是否在字典的key中
>>> '3527' in contacts.keys()
True
7.2.7.返回字典的所有values
>>> contacts.values()
[['Bruce', 'IT', 'DBA'], ['Jack', 'HR', 'HR'], ['BlueTShirt', 'Sales', 'SecurityGuard']]
- 判断成员是否在字典的value中
>>> test_dict = {'sansha':['erha','samo']}
>>> test_dict.values()
[['erha', 'samo']]
>>> test_dict.values()[0]
['erha', 'samo']
>>> 'erha' in test_dict.values()[0]
True
7.2.8.删除dict元素
- 删除dict元素,并返回删除的value
>>> contacts.pop('3091')
['Jack', 'HR', 'HR']
7.2.9.随机删除dict元素
>>> contacts.popitem()
('3951', ['Bruce', 'IT', 'DBA'])
7.2.10.添加dict元素
- 添加dict元素,如果不写value,则为空;如果存在及不创建
>>> contacts.setdefault('name_module')
>>> contacts.setdefault(3951,['Bruce','IT','DBA'])
['Bruce', 'IT', 'DBA']
7.2.11.合并dict
- 如果key冲突,则覆盖原有value
>>> a ={ 1:'a',2:'2', 4:'5'}
>>> b = {1:2,2:3,3:4}
>>> a.update(b)
>>> a
{1: 2, 2: 3, 3: 4, 4: '5'}
7.3.字典的高级特性
7.3.1.多维字典的应用
- 声明一个字典
site_catalog = {
"BJ":{
"noodle": ["pretty, good"],
"duck": ["Who eats"," ho regrets"],
"tiananmen": ["many people"],
},
"SH":{
"food":["i do not know","I heard that sweets mainly"]
},
"GZ":{
"vermicelli":["Looking at the scary", "eating is fucking sweet"]
}
}
- 字典的添加
>>> site_catalog['CD'] = {'gril':['White,','rich','beautiful']}
>>> #上下两种方法都可以.
>>> site_catalog['CD']['boay'] = {}
>>> site_catalog['CD']['boay']['key'] = ['Tall', 'rich and handsome']
>>> site_catalog['BJ']['ditan'] = ['拜地']
- 字典的修改value
注意:dict不能修改字典的key,只能是删除,在创建
>>> site_catalog['CD']['gril'][0] = 'Bai...'
- 字典的访问
>>> site_catalog['CD']['gril'][0]
'White,'
>>> site_catalog['CD']['gril'].count('White')
0
- 三维字典的访问
>>> for k in site_catalog:
... print "Title:%s" % k
... for v in site_catalog[k]:
... print "-> index:%s" % v
... for j in site_catalog[k][v]:
... if 'key' in site_catalog[k][v]:
... print '--> result:{}'.format(site_catalog[k][v][j])
... continue
... print '--> result:{}'.format(j)
...
Title:SH
-> index:food
--> result:i do not know
--> result:I heard that sweets mainly
Title:GZ
-> index:vermicelli
--> result:Looking at the scary
--> result:eating is fucking sweet
Title:BJ
-> index:tiananmen
--> result:many people
-> index:noodle
--> result:pretty, good
-> index:ditan
--> result:拜地
-> index:duck
--> result:Who eats
--> result: ho regrets
Title:CD
-> index:Gril
--> result:White,
--> result:rich
--> result:beautiful
-> index:boay
--> result:['Tall', 'rich and handsome']
-> index:gril
--> result:Bai...
--> result:rich
--> result:beautiful
7.3.2.遍历字典比较
7.3.2.1.方法一
- itesm函数会将所有dict转换成list,数据量大时dict转换成list,效率超级低下
>>> contacts = {'3527': 'tangYan', '3951': {'Bruce': ['IT', 'DBA']}, '3091': {'Jack': ['HR', 'HR']}, '5122': {'BlueTShirt': ['Sales', 'SecurityGuard']}}
>>> for k, v in contacts.items():
... print k ,v
...
3527 tangYan
3951 {'Bruce': ['IT', 'DBA']}
3091 {'Jack': ['HR', 'HR']}
5122 {'BlueTShirt': ['Sales', 'SecurityGuard']}
7.3.2.2.方法二
- 最简单的遍历字典
>>> for i in contacts:
... print i,contacts[i]
...
3527 tangYan
3951 {'Bruce': ['IT', 'DBA']}
3091 {'Jack': ['HR', 'HR']}
5122 {'BlueTShirt': ['Sales', 'SecurityGuard']}
7.3.2.3.方法三
- 基于dict内置方法iteritems()迭代器(iterator)
items()是返回包含dict所有元素的list,但是由于这样太浪费内存。性能也是极其的地下,所以就引入了iteritems(), iterkeys(), itervalues()这一组函数,用于返回一个 iterator 来节省内存;但是在 3.x 里items() 本身就返回这样的 iterator,所以在 3.x 里items() 的行为和 2.x 的 iteritems() 行为一致,iteritems()这一组函数就废除了。”
>>> for i in contacts.iteritems():
... print i
...
('3527', 'tangYan')
('3951', {'Bruce': ['IT', 'DBA']})
('3091', {'Jack': ['HR', 'HR']})
('5122', {'BlueTShirt': ['Sales', 'SecurityGuard']})
- iteritems()
>>> result_iterator = contacts.iteritems()
>>> result_iterator.next()
('3527', 'tangYan')
>>> result_iterator.next()
('3951', {'Bruce': ['IT', 'DBA']})
>>> result_iterator.next()
('3091', {'Jack': ['HR', 'HR']})
>>> result_iterator.next()
('5122', {'BlueTShirt': ['Sales', 'SecurityGuard']})
>>> result_iterator.next()
Traceback (most recent call last):
File "", line 1, in
- iterkeys()
>>> '3951' in contacts.iterkeys()
True
- itervalues()
>>> 'tangYan' in contacts.itervalues()
True
7.3.2.4.一致性
虽然Iterator被采纳,评论却指出,这种说法并不准确,在 3.x 里 items() 的行为和 2.x 的 iteritems() 不一样,它实际上返回的是一个"full sequence-protocol object",这个对象能够反映出 dict 的变化,后来在 Python 2.7 里面也加入了另外一个函数 viewitems() 和 3.x 的这种行为保持一致
创建一个测试dict
>>> d = {'size': 'large', 'quantity': 6}
>>> il = d.items()
>>> it = d.iteritems()
>>> vi = d.viewitems()
- 模拟字典被正常修改
d['newkey'] = 'newvalue'
- 验证一下不同方式dict的结果
- 原生字典
>>> for i in d:
... print i, d[i]
...
newkey newvalue
quantity 6
size large
- items()字典
>>> for k, v in il:
... print k, v
...
quantity 6
size large
- iteritems()字典
>>> for k, v in it:
... print k, v
...
Traceback (most recent call last):
File "", line 1, in
RuntimeError: dictionary changed size during iteration
- viewitmes()字典
>>> for k, v in vi:
... print k, v
...
newkey newvalue
quantity 6
size large
总结:在 2.x 里面,最初是 items() 这个方法,但是由于太浪费内存,所以加入了 iteritems() 方法,用于返回一个 iterator,在 3.x 里面将 items() 的行为修改成返回一个 view object,让它返回的对象同样也可以反映出原 dictionary 的变化,同时在 2.7 里面又加入了 viewitems() 向下兼容这个特性。
所以在 3.x 里面不需要再去纠结于三者的不同之处,因为只保留了一个 items() 方法。
8.集合操作
在Python中set是基本数据类型的一种集合类型,是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)等数学运算;它有可变集合(set())和不可变集合(frozenset)两种。
8.1.集合基本操作
8.1.1.声明集合
>>> a = set(range(1,6))
>>> b = set(range(5,10))
>>> a
set([1, 2, 3, 4, 5])
>>> b
set([8, 9, 5, 6, 7])
8.1.2.交集
>>> a & b
set([5])
或
>>> a.intersection(b)
set([5])
8.1.3.并集
>>> a | b
set([1, 2, 3, 4, 5, 6, 7, 8, 9])
或
>>> a.union(b)
set([1, 2, 3, 4, 5, 6, 7, 8, 9])
8.1.4.差集
>>> a - b
set([1, 2, 3, 4])
>>> b - a
set([8, 9, 6, 7])
或
>>> a.difference(b)
set([1, 2, 3, 4])
>>> b.difference(a)
set([8, 9, 6, 7])
8.1.5.对称差集
- 取两个集合中互相没有的元素
>>> a ^ b
set([1, 2, 3, 4, 6, 7, 8, 9])
或
>>> a.symmetric_difference(b)
set([1, 2, 3, 4, 6, 7, 8, 9])
8.1.6.子集
- D是C的子集
>>> c = set([1,2,3,4,5,6,7])
>>> d = set([1,3,7])
>>> d <= c
True
或
>>> d.issubset(c)
True
8.1.7.父集
- C是D的父集
>>> c >= d
True
或
>>> c.issuperset(d)
True
8.1.8.成员测试
- 成员1在集合A的元素?
>>> 1 in a
True
- 成员1不在集合A的元素?
>>> 1 not in a
False
8.2.集合内置函数
8.2.1.添加一个元素
>>> a.add('haha')
8.2.2.清空集合A
>>> a.clear()
>>> print a
set([])
8.2.3.浅复制
- 老问题,呵呵不说了。
>>> a = set(range(1,6))
>>> e = a.copy()
8.2.4.随机删除元素
- 随机删除集合中的元素,并显示被删除的元素
>>> a.pop()
1
8.2.5.删除元素
>>> a.remove(2)
8.2.6.合并集合
- 此时就能看出来集合的特性:去重功能
>>> a = set(range(1,6))
>>> b = set(range(3,8))
>>> a
set([1, 2, 3, 4, 5])
>>> b
set([3, 4, 5, 6, 7])
>>> a.update(b)
>>> a
set([1, 2, 3, 4, 5, 6, 7])
- 合并list测试
>>> a.update([5,6,7,8])
>>> a
set([1, 2, 3, 4, 5, 6, 7, 8])
9.作业
9.1.猜年龄作业
- 输入用户的信息
- 并且只有猜对年龄才能显示
- 要求猜的机会只有10次
# !/bin/env python
# _*_ coding:utf-8 _*_
name = raw_input('Please imput your name:')
job = raw_input('job:')
salary = raw_input('salary:')
for i in range(10):
age = input('age:')
if age > 29:
print 'think smaller!'
elif age == 29:
print '\033[32;1mGOOD! 10 RMB!\033[0m'
break
else:
print 'think bigger!'
print 'You still got %s shots !' % (9 - i)
print '''
Personal information of %s:
Name: %s
Age : %d
Job : %s
salary : %s
''' % (name,name,age,job,salary)
9.2.用户交互作业
- 用户指定打印循环的次数
- 达到循环的次数是问用户是否继续
- 根据用户选择退出还是再次执行打印的循环次数
# !/bin/env python
# _*_ coding:utf-8 _*_
print_num = input('Which loop do you want it to be printed out?')
counter = 0
while True:
print 'Loop:', counter
if counter == print_num:
choice = raw_input('Do you want to continue the loop?(y/n)')
if choice == 'y' or choice == 'Y':
while print_num <= counter:
print_num = input('Which loop do you want it to be printed out?')
if print_num <= counter:
print '输入值不得小于循环体的值'
elif choice == 'n' or choice == 'N':
print'exit loop....'
break
else:
print 'invalid input!'
continue
counter += 1
以上代码能够完成基本功能但是还有bug的地方
- 在执行choice 代码块时,用户输入,会有多余的loop打印
Do you want to continue the loop?(y/n)12
invalid input!
Loop: 5
- 代码有重复代码,这肯定是可以优化的两个print_num用户输入
print_num = input('Which loop do you want it to be printed out?')
优化版
# !/bin/env python
# _*_ coding:utf-8 _*_
counter = 0
flag_1 = True
flag_2 = True
while True:
if flag_1 is True:
print 'Loop:', counter
else:
flag_1 = True
if flag_2 is True:
print_num = input('Which loop do you want it to be printed out?')
flag_2 = False
if counter == print_num:
choice = raw_input('Do you want to continue the loop?(y/n)')
if choice == 'y' or choice == 'Y':
while print_num <= counter:
print_num = input('Which loop do you want it to be printed out?')
if print_num <= counter:
print '输入值不得小于循环体的值'
elif choice == 'n' or choice == 'N':
print'exit loop....'
break
else:
print 'invalid input!'
flag_1 = False
continue
counter += 1
9.3.购物车作业
- 输入你的工资,进入商城选购商品
- 将商品放入购物车后,相应扣款
- 结束购物车时,清算商品及金额
- 并打印买的商品信息
#!/bin/env python
# _*_ coding:utf-8 _*_
products = [['Iphone',5800],['MacPro',12000],['NB Shoes',680],['MX4',64]]
salary = raw_input('Please input your salary: ')
shopping_list = []
if salary.isdigit():
salary = int(salary)
while True:
# print shoppint cart
for index,item in enumerate(products):
#print products.index(i),i
print index, item
# get user input
choice = raw_input('Please choose sth to buy')
# judge user input data type is number
if choice.isdigit():
choice = int(choice)
# judge goods count and seach goods index
if choice < len(products) and choice >= 0 :
pro_itmes = products[choice]
# judge Wage salary
if salary > pro_itmes[1] :
shopping_list.append(pro_itmes)
salary = salary - pro_itmes[1]
print('Added \033[31;1m%s\033[1m into shopping cart ,your current balance : %s' % (pro_itmes,salary))
else:
print('Sorry, your credit is running low : \033[41;1m%s\033[1m' % salary)
else:
print('input invalied!')
elif choice == 'q':
print("""------ shopping Cart------""")
for i in shopping_list:
print i
print('wage balance : \033[31;1m%s\033[1m ' % salary)
exit()
else:
print('There is no such commodity!')
else:
print('input error!')
9.4.地区查询作业
- 打印省、市、县、区、街道信息
- 可返回上一级
- 可以随时退出程序,以下是所需dict:
menu = {
'北京':{
'海淀':{
'五道口':{
'soho':{},
'网易':{},
'google':{}
},
'中关村':{
'爱奇艺':{},
'汽车之家':{},
'youku':{},
},
'上地':{
'百度':{},
},
},
'昌平':{
'沙河':{
'链家':{},
'小贩':{},
},
'天通苑':{},
'回龙观':{},
},
'朝阳':{},
'东城':{},
},
'上海':{
'闵行':{
"人民广场":{
'炸鸡店':{}
}
},
'闸北':{
'火车战':{
'携程':{}
}
},
'浦东':{},
},
'山东':{},
}
exit_code = False
while not exit_code:
for i in menu:
print i
choire = raw_input('Please input city :')
if choire in menu:
while not exit_code:
for i2 in menu[choire]:
print i2
choire2 = raw_input('Please input area or cd .. (Y/N):')
if choire2 in menu[choire]:
if len(menu[choire][choire2]) <= 0 :
print "没有信息!"
while not exit_code:
for i3 in menu[choire][choire2]:
print i3
choire3 = raw_input('Please input space or cd .. (Y/N):')
if choire3 in menu[choire][choire2]:
for i4 in menu[choire][choire2][choire3]:
print i4
choire4 = raw_input('cd .. (Y/N)')
if choire4 == 'Y':
pass
elif choire4 == 'q':
exit_code = True
if choire3 == 'Y':
break
elif choire3 == 'q':
exit_code = True
if choire2 == 'Y':
break
elif choire2 == 'q':
exit_code = True
- 附录
- 运算符
- 条件语句
- 循环运算
- 字符串操作
- 列表操作
- 元组操作
- 字典操作
- 集合操作
- 作业