架构
基本流程: 点对点分布式系统,集群中各节点平等,数据分布于集群中各节点,各节点间每秒交换一次信息。
每个节点的commit log提交日志捕获写操作来确保数据持久性。
数据先被写入MemTable(内存中的数据结构),待MemTable满后数据被写入SSTable(硬盘的数据文件)。
所有的写内容被自动在集群中partition分区并replicate复制。
库表结构: Cassandra数据库面向行。用户可连接至集群的任意节点,通过类似SQL的CQL查询数据。
集群中,一个应用一般包含一个keyspace,一个keyspace中包含多个表。
读写请求: 客户端连接到某一节点发起读或写请求时,该节点充当客户端应用与拥有相应数据的节点间的
coordinator协调者以根据集群配置确定环(ring)中的哪个节点应当获取这个请求。
CQL是客户端,Driver也是一种客户端. 使用CQL连接指定的-h节点就是协调节点.
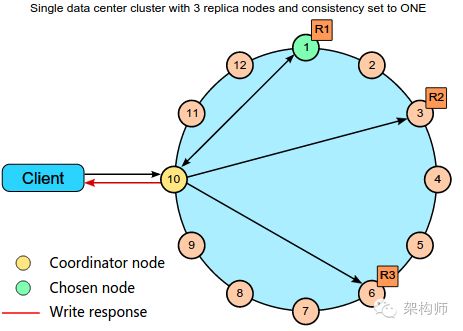
图解: 协调节点(10)负责和客户端的交互.真正的数据在节点1,4,6上,分别表示数据的三个副本,最终只要节点1上的数据返回即可.
关键词

节点间通信gossip
Cassandra使用点对点通讯协议gossip在集群中的节点间交换位置和状态信息。
gossip进程每秒运行一次,与至多3个其他节点交换信息,这样所有节点可很快了解集群中的其他节点信息
gossip协议的具体表现形式就是配置文件中的seeds种子节点. 一个注意点是同一个集群的所有节点的种子节点应该一致.
否则如果种子节点不一致, 有时候会出现集群分裂, 即会出现两个集群. 一般先启动种子节点,尽早发现集群中的其他节点.
每个节点都和其他节点交换信息, 由于随机和概率,一定会穷举出集群的所有节点.同时每个节点都会保存集群中的所有其他节点.
这样随便连到哪一个节点,都能知道集群中的所有其他节点. 比如cql随便连接集群的一个节点,都能获取集群所有节点的状态.
也就是说任何一个节点关于集群中的节点信息的状态都应该是一致的!
失败检测与恢复
●gossip可检测其他节点是否正常以避免将请求路由至不可达或者性能差的节点(后者需配置为dynamic snitch方可)。
●可通过配置phi_convict_threshold来调整失败检测的敏感度。
●对于失败的节点,其他节点会通过gossip定期与之联系以查看是否恢复而非简单将之移除。若需强制添加或移除集群中节点需使用nodetool工具。
●一旦某节点被标记为失败,其错过的写操作会有其他replicas存储一段时间. (需开启hinted handoff,若节点失败的时间超过了max_hint_window_in_ms,错过的写不再被存储). Down掉的节点经过一段时间恢复后需执行repair操作,一般在所有节点运行nodetool repair以确保数据一致。
dynamic snitch特性: 查询请求路由到某个节点,如果这个节点当掉或者响应慢,则应该能够查询其他节点上的副本
删除节点: 节点失败后,仍然在集群中,通过removenode可以将节点从集群中下线.区别就是status如果不存在就说明下线了. DN则仍然在集群中.
失败节点数据: 数据无法正常存储到失败的节点,所以会由其他节点暂时保存,等它恢复之后,再将错过的写补充上去.
一致性哈希DHT
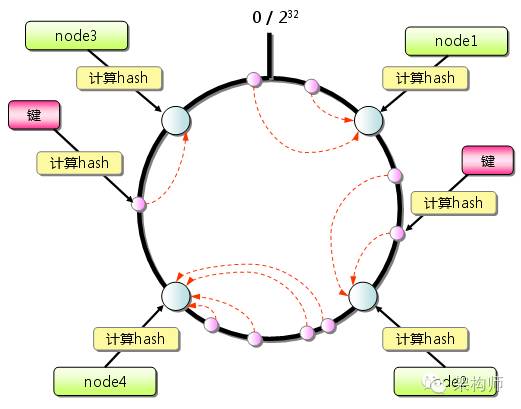
图解: key的范围是0到2^32形成一个环, 叫做hash空间环, 即hash的值空间. 对集群的服务器(比如ip地址)进行hash,都能确定其在环空间上的位置.
定位数据访问到相应服务器的算法:将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,
从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器
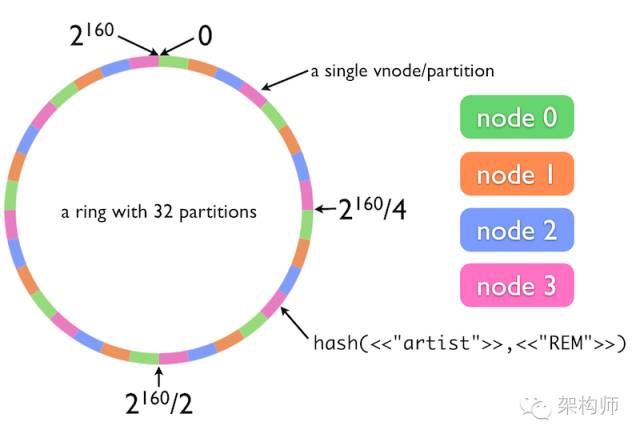
图解: 由于一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题,所以引入了虚拟节点:
把每台server分成v个虚拟节点,再把所有虚拟节点(n*v)随机分配到一致性哈希的圆环上,
这样所有的用户从自己圆环上的位置顺时针往下取到第一个vnode就是自己所属节点. 当此节点存在故障时,再顺时针取下一个作为替代节点.
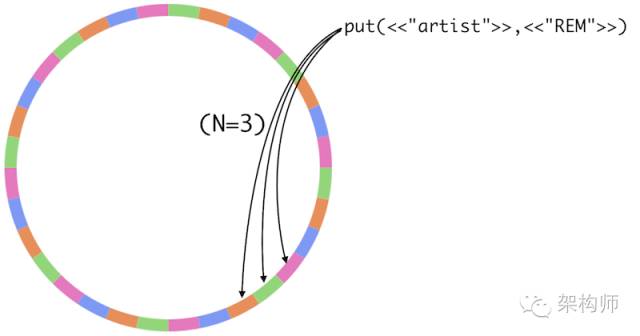
图解: key经过hash会定位到hash环上的一个位置, 找到下一个vnode为数据的第一份存储节点. 接下来的两个vnode为另外两个副本.
hash值空间&token
上面在计算key存在在哪个节点上是使用往前游走的方式找到环上的第一个节点. 游走是一个计算的过程.
如果能够事先计算好集群中的节点(vnodes)在整个hash环的值空间, 这样对key进行hash后,可以看它是落在哪个hash值空间上,
而值空间和节点的关系已经知道了,所以可以直接定位到key落在哪个节点上了. 这就是token的作用.
C表中每行数据由primary key标识,C为每个primarykey分配一个hash值,集群中每个节点(vnode)拥有一个或多个hash值区间。
这样便可根据primary key对应的hash值将该条数据放在包含该hash值的hash值区间对应的节点(vnode)中
虚拟节点
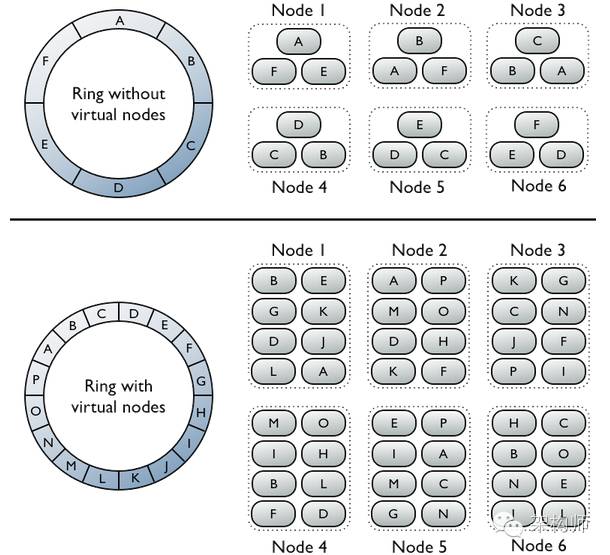
图解: 没有使用虚拟节点, Ring环的tokens数量=集群的机器数量. 比如上面一共有6个节点,所以token数=6.
因为副本因子=3,一条记录要在集群中的三个节点存在. 简单地方式是计算rowkey的hash值,落在环中的哪个token上,
第一份数据就在那个节点上, 剩余两个副本落在这个节点在token环上的后两个节点.
图中的A,B,C,D,E,F是key的范围,真实的值是hash环空间,比如0~2^32区间分成10份.每一段是2^32的1/10.
节点1包含A,F,E表示key范围在A,F,E的数据会存储到节点1上.以此类推.
若不使用虚拟节点则需手工为集群中每个节点计算和分配一个token。
每个token决定了节点在环中的位置以及节点应当承担的一段连续的数据hash值的范围。
如上图上半部分,每个节点分配了一个单独的token代表环中的一个位置,每个节点存储将row key映射为hash值之后
落在该节点应当承担的唯一的一段连续的hash值范围内的数据。每个节点也包含来自其他节点的row的副本。
而使用虚拟节点允许每个节点拥有多个较小的不连续的hash值范围。
如上图中下半部分,集群中的节点使用了虚拟节点,虚拟节点随机选择且不连续。
数据的存放位置也由row key映射而得的hash值确定,但是是落在更小的分区范围内
使用虚拟节点的好处
●无需为每个节点计算、分配token
●添加移除节点后无需重新平衡集群负载
●重建死掉的节点更快
●改善了在同一集群使用异种机器
数据复制
当前有两种可用的复制策略:
●SimpleStrategy:仅用于单数据中心,将第一个replica放在由partitioner确定的节点中,其余的replicas放在上述节点顺时针方向的后续节点中。
●NetworkTopologyStrategy:可用于较复杂的多数据中心。可以指定在每个数据中心分别存储多少份replicas。
复制策略在创建keyspace时指定,如
CREATE KEYSPACE Excelsior WITH REPLICATION = { 'class' : 'SimpleStrategy','replication_factor' : 3 };
CREATE KEYSPACE Excalibur WITH REPLICATION = {'class' :'NetworkTopologyStrategy', 'dc1' : 3, 'dc2' : 2};
其中dc1、dc2这些数据中心名称要与snitch中配置的名称一致.上面的拓扑策略表示在dc1配置3个副本,在dc2配置2个副本
Partitioners
在Cassandra中,table的每行由唯一的primarykey标识,partitioner实际上为一hash函数用以计算primary key的token。Cassandra依据这个token值在集群中放置对应的行
注意:若使用虚拟节点(vnodes)则无需手工计算tokens。若不使用虚拟节点则必须手工计算tokens将所得的值指派给cassandra.ymal主配置文件中的initial_token参数
客户端请求
client连接至节点并发出read/write请求时,该节点充当client端应用与包含请求数据的节点(或replica)之间的协调者,
它利用配置的partitioner和replicaplacement策略确定那个节点当获取请求。
写请求
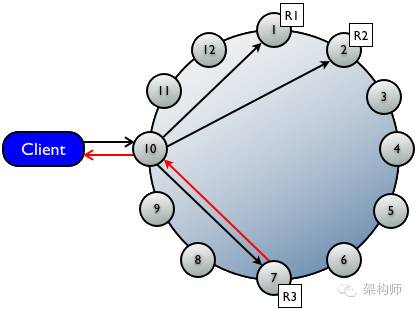
●协调者(coordinator)将write请求发送到拥有对应row的所有replica节点,只要节点可用便获取并执行写请求。
●写一致性级别(write consistency level)确定要有多少个replica节点必须返回成功的确认信息。成功意味着数据被正确写入了commit log和memtable。
●上例为单数据中心,11个节点(不是有12个吗?),复制因子为3,写一致性等级为ONE的写情况(红色的箭头表示只要一个节点成功写入,便可立即返回给客户端)
写请求是如何保证一致性的?
读请求
[1] 直接读请求(Direct Read)
[2] 后台读修复请求(RR:Read Repair)
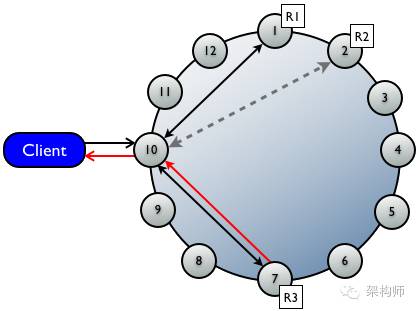
与直接读请求[1]联系的replica数目由一致性级别确定(上图中请求了R1和R3两个节点).
后台读修复请求[2]被发送到没有收到直接读请求的replica(R2),以确保请求的row在所有replica上一致.
●协调者首先与一致性级别确定的所有replica联系,被联系的节点返回请求的数据,
●若多个节点被联系,则来自各replica的row会在内存中作比较,若不一致,则协调者使用含最新数据的replica向client返回结果。
●协调者在后台联系和比较来自其余拥有对应row的replica的数据,若不一致,会向过时的replica发写请求用最新的数据进行更新:read repair。
●上例为单数据中心,11个节点,复制因子为3,一致性级别为QUORUM(3/2+1=2)的读情况(请求了两个节点,但最终返回给客户端的是最新的数据)
读请求是如何保证数据一致性的? 直接读请求将查询请求发送到了2个副本所在的节点(1,7). 因为有两个副本,所以会比较这两个副本哪个是最新的.
比较操作是在协调节点,还是在各个副本节点? 当然应该是在协调节点上,因为在各个副本节点上是没办法知道其他节点的副本的.
那么比较操作是不是把这两个副本的数据都传送到协调节点. 不是的,只需要传递时间撮就可以,因为要比较的只是哪个副本数据是最新的.
怎么判断两个副本的数据不一致? 实际上是使用md5判断值不一样,说明两个副本的数据是不一样的.
因为没有必要在比较的时候就把两个副本的全部查询结果都传送给协调节点,所以在确定哪个是最新的后,那个副本需要把查询结果传送给协调节点
再由协调节点将数据返回给客户端. 即图中红色的部分为结果数据的流程. 而黑色的往返箭头只是传递时间撮用来比较哪个是最新数据.
协调节点
问题:客户端连接的那个节点是怎么指定的? 是addContactPoint指定的节点吗? 但是ContactPoint一般设置为种子节点中的一个.
如果是CQL客户端连接C集群,则CQL连接的那个节点就是协调节点.
但是如果使用Driver API. 指定的ContactPoint并不是协调节点!
读写流程
写流程
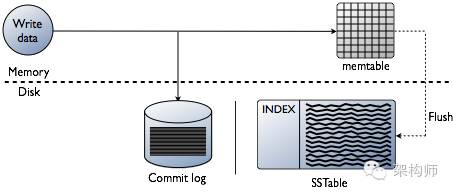
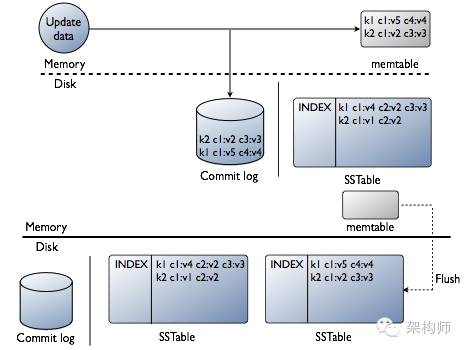
图解: 上图表示写请求分别到MemTable和CommitLog, 并且MemTable的数据会刷写到磁盘上. 除了写数据,还有索引也会保存到磁盘上.
先将数据写进内存中的数据结构memtable,同时追加到磁盘中的commitlog中。
memtable内容超出指定容量后会被放进将被刷入磁盘的队列(memtable_flush_queue_size配置队列长度)。
若将被刷入磁盘的数据超出了队列长度,C会锁定写,并将内存数据刷进磁盘中的SSTable,之后commit log被清空。
读流程

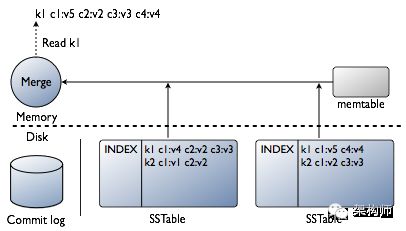
首先检查BloomFilter①,每个SSTable都有一个Bloomfilter,用以在任何磁盘IO前检查请求PK对应的数据在SSTable中是否存在
BF可能误判不会漏判:判断存在,但实际上可能不存在, 判断不存在,则一定不存在,则流程不会访问这个SSTable(红色).
若数据很可能存在②,则检查PartitionKey cache(索引的缓存),之后根据索引条目是否在cache中找到而执行不同步骤:
在索引缓存中找到
●③从compression offset map中查找拥有对应数据的压缩快。
●④从磁盘取出压缩的数据,返回结果集。
没有在索引缓存中
●⑤搜索Partition summary(partition index的样本集)确定index条目在磁盘中的近似位置。
●⑥从磁盘中SSTable内取出index条目。
●⑦从compression offset map中查找拥有对应数据的压缩快。
从磁盘取出压缩的数据,返回结果集。
示例
第一个SSTable文件是insert(左), 第二个SSTable是update的数据(右).
由insert/update过程可知,read请求到达某一节点后,必须结合所有包含请求的row中的column的SSTable以及memtable来产生请求的数据
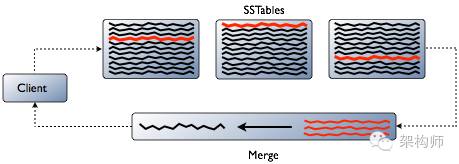
例如,要更新包含用户数据的某个row中的email 列,cassandra并不重写整个row到新的数据文件,
而仅仅将新的email写进新的数据文件,username等仍处于旧的数据文件中。
上图中红线表示Cassandra需要整合的row的片段用以产生用户请求的结果。
为节省CPU和磁盘I/O,Cassandra会缓存合并后的结果,且可直接在该cache中更新row而不用重新合并
参考文档
一致性哈希算法及其在分布式系统中的应用:http://blog.codinglabs.org/articles/consistent-hashing.html
Riak Clusters:http://docs.basho.com/riak/latest/theory/concepts/Clusters/
http://docs.datastax.com/en/cassandra/2.0/cassandra/architecture/architectureTOC.html
http://yikebocai.com/2014/06/cassandra-principle/
Cassandra研究报告:http://blog.csdn.net/zyz511919766/article/details/38683219
Cassandra 分布式数据库详解,第 1 部分:配置、启动与集群https://www.ibm.com/developerworks/cn/opensource/os-cn-cassandraxu1/
Cassandra 分布式数据库详解,第 2 部分:数据结构与数据读写https://www.ibm.com/developerworks/cn/opensource/os-cn-cassandraxu2/
来源:zqhxuyuan.github.io
原文:http://zqhxuyuan.github.io/2015/08/25/2015-08-25-Cassandra-Architecture/#