本博客详细介绍Standalone模式下的Spark集群的部署。
1.软件硬件环境
主机操作系统:三台为实验室服务器(均为Centos 7.3)。
虚拟机运行环境:Java 1.8( 1.8.0_144-b01)、Hadoop 2.8.2、Scala 2.11.8、Spark 2.2.0(spark-2.2.0-bin-hadoop2.7)
Note: Starting version 2.0, Spark is built with Scala 2.11 by default. Scala 2.10 users should download the Spark source package and build with Scala 2.10 support.
2.集群网络环境
网络基本配置
在root 用户下打开/etc/sysconfig/network 对文件进行如下配置
NETWORKING=yes
HOSTNAME=master

然后是配置生效:
hostname master
在slave1与slave2节点上的root用户下重复相同的操作,分别将主机名改为slave1、salve2。
如果需要修改hostname,直接使用文本编辑器修改/etc/hostname配置文件(此种方法修改的是静态主机名)。
前者是IP地址,后者是主机名,分别复制放在/etc/hosts 文件中,然后三台虚拟机可以相互ping 的通。
59.68.29.103 slave1
59.68.29.105 master
59.68.29.108 slave2
注意:请将下面的
Static hostname的localhost名称分别改为master、slave1、slave2,不然之后在WebUI上无法显示节点信息内容。
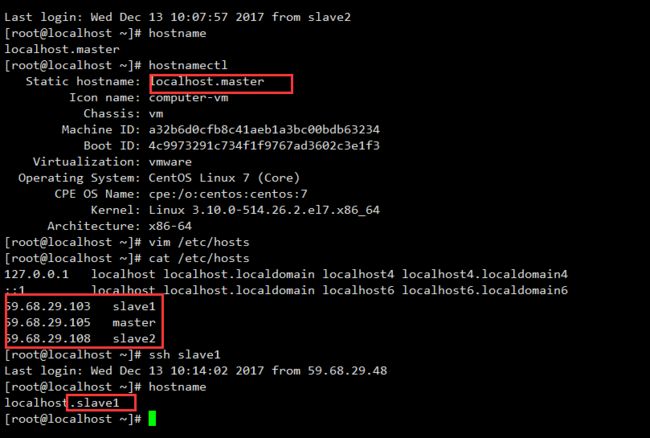
本集群共包含三个节点,所有节点均是Centos7.3 64位系统,防火墙均禁用,每个节点上创建一个zhoujian用户,用户的主目录是/home/zhoujian ,节点之间可以免密码SSH访问,节点的IP地址和主机名如下表:
| 序号 | IP地址 | 机器名 | 类型 | 用户名 |
|---|---|---|---|---|
| 1 | 59.68.29.105 | master | NameNode/Master | zhoujian |
| 2 | 59.68.29.103 | slave1 | DateNode/Worker | zhoujian |
| 3 | 59.68.29.108 | slave2 | DateNode/Worker | zhoujian |
其中NameNode表示Hadoop集群中的主节点,DateNode表示Hadoop集群中的从节点,Master表示Spark集群中的主节点,Worker表示Spark集群中的从节点。
每个节点都创建一个zhoujian 的用户:

3.软件的安装
1.配置服务器之间SSH无密码登录
原理:就是将三台虚拟机的
id_rsa.pub公钥都放在authorized_keys中,然后将authorized_keys放到/root/.ssh目录下并执行chmod 600 authorized_keys授予权限,即可将三台虚拟机互通。
第一步:使用下面命令生成密钥
ssh-keygen -t rsa
第二步:复制公钥文件
cat id_rsa_pub >> authorized_keys
第三步:修改authorized_keys文件的权限
chomd 600 authorized_keys
第四步:三台虚拟机的公钥都复制到authorized_keys文件中
scp /root/.ssh/authorized_keys slave1:/root/.ssh/
scp /root/.ssh/authorized_keys slave2:/root/.ssh/
分别在slave1、slave2重复第三步的操作
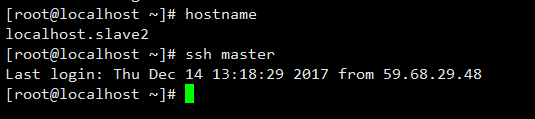
第五步:验证免密钥登录
2.安装JDK
这里就不讲了。
3.安装Hadoop
1.上传和解压
安装路径为:/usr/local/hadoop/
2.修改hadoop目录下的一系列配置文件
修改/usr/local/hadoop/hadoop-2.8.2/etc/hadoop中的配置文件,如下图
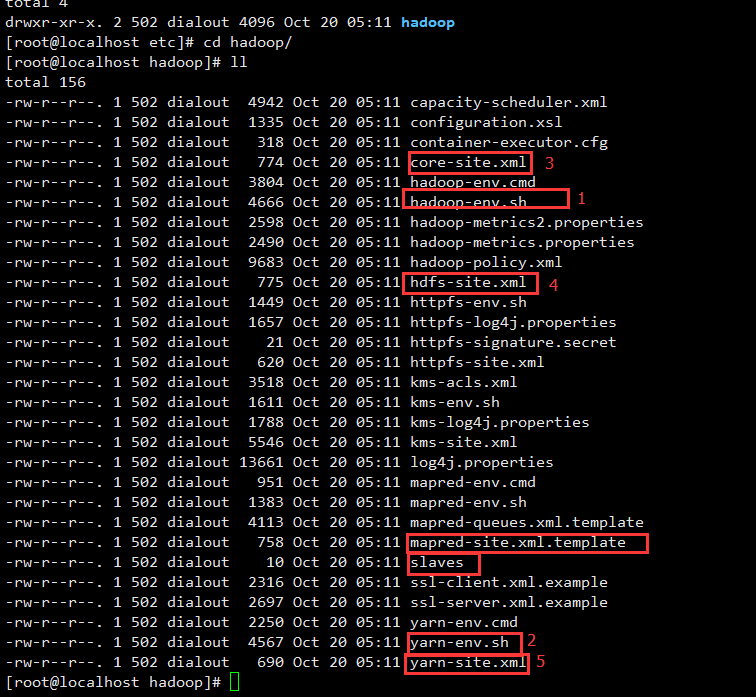
第一步:配置hadoop-env.sh
打开hadoop-env.sh ,配置JDK路径,在文件靠前的部分找到下面的一行代码,然后添加实际的Java安装路径。

第二步:配置yarn-env.sh
打开yarn-env.sh,配置JDK的路径。
在文件靠前的部分找到下面的一行代码:

将这行代码修改为一下形式:

第三步:配置core-site.xml
分别在master、slave1、slave2上切换至zhoujian 用户,然后在主目录下创建目录hadoopdata
mkdir /home/zhoujian/hadoopdata
用以下代码覆盖core-site.xml文件中的内容
fs.defaultFS
hdfs://master:9000 >
hadoop.tmp.dir
/home/zhoujian/hadoopdata >
第四步:配置hdfs-site.xml
用以下代码替换hdfs-site.xml中的内容
dfs.replication
1
第五步:配置yarn-site.xml
用以下代码覆盖yarn-site.xml中的内容
yarn.nodemanager.aux-service
mapreudce_shuffle
yarn.resourcemanager.address
master:18040
yarn.resourcemanager.shceduler.address
master:18030
yarn.resourcemanager.resource-tracker.address
master:18025
yarn.resourcemanager.admin.address
master:18141
yarn.resourcemanager.webapp.address
master:18088
第六步:配置 mapred-site.xml
复制/usr/local/hadoop/hadoop-2.8.2/etc/hadoop 目录下的mapred-site.xml.template 文件,另存为该目录下的mapred-site.xml
cp /usr/local/hadoop/hadoop-2.8.2/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.8.2/etc/hadoop/mapred-site.xml
用下面的代码覆盖mapred-site.xml中的内容
mapreduce.framework.name
yarn
第七步:配置slaves文件
用以下的代码替换slaves中的内容
slave1
slave2
需要注意:此处既可以给出两个节点的IP地址,也可以给出机器名,但是要求每一个IP地址或机器独占一行。
3.配置从节点
将master节点的安装目录/usr/local/hadoop/hadoop-2.8.2的hadoop-2.8.2 文件夹分别复制至每个节点的/usr/local/hadoop 目录下。
#远程拷贝:将hadoop-2.8.2目录文件复制到slave1的hadoop文件夹下
scp -r /usr/local/hadoop/hadoop-2.8.2/ slave1:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.8.2 slave2:/usr/local/hadoop/
4.配置系统文件
分别在master、slave1、slave2上以zhoujian用户执行以下步骤。
第一步:配置系统文件(centos 7 是修改/etc/profile 文件)
vim /etc/profile
第二步:在打开的.bash_profile文件中配置以下环境变量
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.8.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
第三步:使其配置生效
source /etc/profile
5.启动Hadoop集群
第一步:格式化文件系统
在master节点上执行下面的格式化命令
hdfs namenode -format
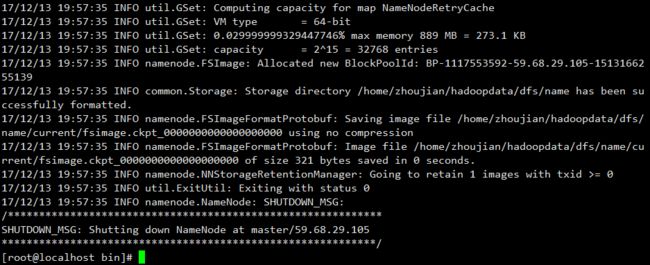
格式化成功之后,可以看到/home/zhoujian/hadoopdata/dfs/name/current 目录中有一系列的文件:

第二步:启动Hadoop
进入hadoop-2.8.2文件夹
cd /usr/local/hadoop/hadoop-2.8.2
执行启动命令
sbin/start-all.sh

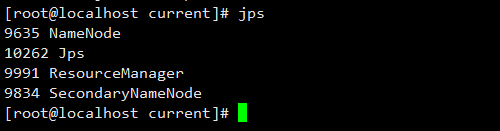
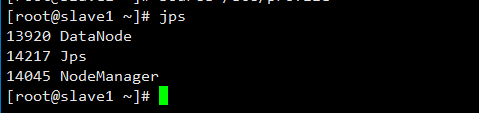
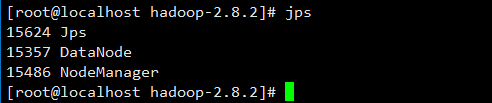
第三步:验证
master的终端执行jps指令后出现4个进程,在slave1、slave2的终端执行jps指令后会出现3个进程。
master节点:
slave1节点:
slave2节点:
备注:NameNode的端口号是50070,resourcemanager端口号是18088
4.安装Scala
第一步:上传至/usr/local/scala并解压scala-2.11.8.tgz
tar -zvxf scala-2.11.8.tgz
第二步:配置环境变量
vim /etc/profile
在/etc/profile 文件中添加以下环境变量
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
第三步:使环境变量生效
source /etc/profile
第四步:将scala-2.11.8发送至slave1、slave2
scp -r /usr/local/scala/scala-2.11.8 slave1:/usr/local/scala
scp -r /usr/local/scala/scala-2.11.8 slave2:/usr/local/scala
分别在slave1、salve2上重复第2步
第五步:验证
分别在master、salve1、salve2中执行scala -version ,如果安装成功则显示下面的

5.安装Spark
1.下载并解压spark安装包
在master节点上传压缩包并解压,上传位置为/usr/local/spark
tar -zvxf spark-2.2.0-bin-hadoop2.7.tgz
2.配置Spark-env.sh
第一步: /usr/local/spark/spark-2.2.0-bin-hadoop2.7/conf目录下文件如下所示:

复制其中的spark-env.sh.template 并另存为该目录下的spark-env.sh
cp spark-env.sh.template spark-env.sh
第二步:打开spark-env.sh ,将一下代码添加至spark-env.sh 中
#用户根据实际安装情况进行配置
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.8.2/
export JAVA_HOME=/usr/local/java/jdk1.8.0_144/
export SCALA_HOME=/usr/local/scala/scala-2.11.8
#绑定一个外部IP给master,master节点所在的机器的ip
export SPARK_MASTER_IP=59.68.29.105
#master启动的端口号
export SPARK_MASTER_PORT=7077
#master的webUI端口号
export SPARK_MASTER_WEBUI_PORT=8080
#worker的启动端口号
export SPARK_WORKER_PORT=7078
#worker的webUI端口号
export SPARK_WORKER_WEBUI_PORT=8081
#作业可用的CPU内核数量(默认:所有可用)
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
#作业可使用的内存容量
export SPARK_WORKER_MEMORY=2g
3.配置spark-defaults.conf.template
第一步:进入/usr/local/spark/spark-2.2.0-bin-hadoop2.7/conf ,复制spark-defaults.conf.template 并另存为该目录下的spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
第二步:打开spark-defaults.conf,并添加以下代码
#该参数需要根据用户master节点的实际ip地址进行配置
spark.master=spark://59.68.29.105:7077
4.配置slaves
第一步:进入/usr/local/spark/spark-2.2.0-bin-hadoop2.7/conf ,复制slaves.template 并另存为该目录下的slaves
cp slaves.template slaves
第二步:在salves中添加子节点机器名或IP地址
#需要注意slaves文件时每个机器名或ip地址独占一行
59.68.29.103
59.68.29.108
5.配置环境变量
第一步:配置环境变量
vim /etc/profile
在/etc/profile 文件中添加以下环境变量
export SPARK_HOME=/usr/local/spark/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
第二步:使环境变量生效
source /etc/profile
第三步:将scala-2.11.8发送至slave1、slave2
scp -r /usr/local/spark/spark-2.2.0-bin-hadoop2.7 slave1:/usr/local/spark
scp -r /usr/local/spark/spark-2.2.0-bin-hadoop2.7 slave2:/usr/local/spark
分别在slave1、slave2上重复第1步
6.启动Spark
第一步:启动Hadoop
第二步:进入spark-2.2.0-bin-hadoop2.7启动集群
#开启
sbin/start-master.sh
sbin/start-slaves.sh
#停止
sbin/stop-master.sh
sbin/stop-slaves.sh
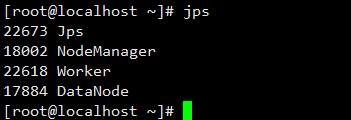
第三步:验证集群时候搭建成功,分别在master、slave1、slave2上通过jps命令查看进程


4.参考资料
Spark大数据分析实战
https://my.oschina.net/xingkongxia/blog/610397
http://www.powerxing.com/install-hadoop-in-centos/
http://www.xuetuwuyou.com/course/149
http://docs.scala-lang.org/?_ga=2.265178895.1288223642.1513144087-1990176989.1511426647