08-linux基础命令(五)
Linux基础命令(五)

管道命令:
命令执行顺序控制
通常情况下,我们在终端只能执行一条命令,然后按下回车执行,那么如何执行多条命令呢?
顺序执行多条命令 :
command1;command2;command3;
简单的顺序指令可以通过 ;来实现
有条件的执行多条命令:
which command1 && command2 || command3
- && :
如果前一条命令执行成功则执行下一条命令,如果command1执行成功(返回0),则执行command2 - || :
与&&命令相反,执行不成功时执行这个命令. - $?:
存储上一次命令的返回结果.
grep
- grep :
分析一行信息,如果其中有我们需要的信息,就将该行拿出来. -
grep [-acinv] [–color=auto] ‘查找字符串’ filename
常用[参数]:
-a : 将binary文件以text文件的方式查找数据
-c : 计算找到 '查找字符串'的次数
-i : 忽略大小写的不同
-n : 输出行号
-v : 反向选择,显示没有查找内容的行
--color=auto : 将找到的关键字部分加上颜色显示
选项
-a 不要忽略二进制数据。
-A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
示例 :
[root@CentOS7 ~]# cat /etc/passwd |grep -n --color=auto 'root'
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin(被匹配到的root会被标红)
tr :
- tr
命令可以对来自标准输入的字符进行替换、压缩和删除。它可以将一组字符变成另一组字符,经常用来编写优美的单行命令,作用很强大。
主要参数 :
-
-c或——complerment:取代所有不属于第一字符集的字符;
-
-d或——delete:删除所有属于第一字符集的字符;
-
-s或–squeeze-repeats:把连续重复的字符以单独一个字符表示;
-
-t或–truncate-set1:先删除第一字符集较第二字符集多出的字符。
示例 :
- 将输入字符由大写转换为小写:
echo “HELLO WORLD” | tr ‘A-Z’ ‘a-z’
hello world
- 用tr压缩字符,可以压缩输入中重复的字符 :
echo “thissss is a text linnnnnnne.” | tr -s ’ sn’
this is a text line.
tr可以使用的字符类 :
[:alnum:]:字母和数字
[:alpha:]:字母
[:cntrl:]:控制(非打印)字符
[:digit:]:数字
[:graph:]:图形字符
[:lower:]:小写字母
[:print:]:可打印字符
[:punct:]:标点符号
[:space:]:空白字符
[:upper:]:大写字母
[:xdigit:]:十六进制字符
使用方式 :
- tr ‘[:lower:]’ ‘[:upper:]’
使用tr打印1加至100 :
[root@CentOS8 data]# echo {1..100} > filethree.txt
[root@CentOS8 data]# cat filethree.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
[root@CentOS8 data]# tr ' ' '+' < filethree.txt > filefour.txt
[root@CentOS8 data]# cat filefour.txt
1+2+3+4+5+6+7+8+9+10+11+12+13+14+15+16+17+18+19+20+21+22+23+24+25+26+27+28+29+30+31+32+33+34+35+36+37+38+39+40+41+42+43+44+45+46+47+48+49+50+51+52+53+54+55+56+57+58+59+60+61+62+63+64+65+66+67+68+69+70+71+72+73+74+75+76+77+78+79+80+81+82+83+84+85+86+87+88+89+90+91+92+93+94+95+96+97+98+99+100
打印1至100的奇偶数集 :
[root@CentOS8 data]# echo {0..100..2} (打印1到100的偶数集)
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 94 96 98 100
[root@CentOS8 data]# echo {1..100..2} (打印1到100的奇数集)
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51 53 55 57 59 61 63 65 67 69 71 73 75 77 79 81 83 85 87 89 91 93 95 97 99
将标准错误导入管道 :
[root@CentOS8 data]# xxx | tr 'a-z' 'A-Z' (这样输入是无法将其导入的!)
bash: xxx: command not found...
Failed to search for file: Cannot update read-only repo
正确做法:
[root@CentOS8 data]# xxx |& tr 'a-z' 'A-Z'
BASH: XXX: COMMAND NOT FOUND...
FAILED TO SEARCH FOR FILE: CANNOT UPDATE READ-ONLY REPO
使用tr将其替换成大写并输出至文件中:
[root@CentOS8 data]# xxx |& tr 'a-z' 'A-Z' > filefive.txt
[root@CentOS8 data]# cat filefive.txt
BASH: XXX: COMMAND NOT FOUND...
FAILED TO SEARCH FOR FILE: CANNOT UPDATE READ-ONLY REPO
split
- split :
顾名思义,讲一个大文件依据文件大小或行数切割成为小文件.
[参数] :
-b : 后面可接欲切割文件的大小,可加单位,例如b,k,m等
-l : 以行数来进行切割
-C:每一输出档中,单行的最大 byte 数。
-d:使用数字作为后缀。
PREFIX : 代表前导符,可作为切割文件的前导文字
- 示例 :生成一个大小为100KB的测试文件:
[root@localhost split]# dd if=/dev/zero bs=100k count=1 of=date.file
1+0 records in
1+0 records out
102400 bytes (102 kB) copied, 0.00043 seconds, 238 MB/s
- 使用split命令将上面创建的date.file文件分割成大小为10KB的小文件:
[root@localhost split]# split -b 10k date.file
[root@localhost split]# ls
date.file xaa xab xac xad xae xaf xag xah xai xaj
tail
-
tail
命令用于输入文件中的尾部内容。tail命令默认在屏幕上显示指定文件的末尾10行。 -
如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题。如果没有指定文件或者文件名为“-”,则读取标准输入。 -
注意 :
如果表示字节或行数的N值之前有一个”+”号,则从文件开头的第N项开始显示,而不是显示文件的最后N项。N值后面可以有后缀:b表示512,k表示1024,m表示1 048576(1M)。
选项 :
--retry:即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。使用此选项时需要与选项“——follow=name”连用;
-c或——bytes=:输出文件尾部的N(N为整数)个字节内容;
-f或;--follow:显示文件最新追加的内容。“name”表示以文件名的方式监视文件的变化。“-f”与“-fdescriptor”等效;
-F:与选项“-follow=name”和“--retry"连用时功能相同;
-n或——line=:输出文件的尾部N(N位数字)行内容。
--pid=<进程号>:与“-f”选项连用,当指定的进程号的进程终止后,自动退出tail命令;
-q或——quiet或——silent:当有多个文件参数时,不输出各个文件名;
-s<秒数>或——sleep-interal=<秒数>:与“-f”选项连用,指定监视文件变化时间隔的秒数;
-v或——verbose:当有多个文件参数时,总是输出各个文件名;
示例 :
-
tail file (显示文件file的最后10行)
-
tail +20 file (显示文件file的内容,从第20行至文件末尾)
-
tail -c 10 file (显示文件file的最后10个字符)
I/O重定向
- 将输出和错误重新定向到文件。
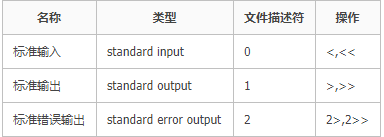
- STDOUT和STDERR可以被重定向到文件
支持的操作符号包括:
- 1> 把STDOUT重新定向到文件
- 2> 把STDERR重新定向到文件
- &> 把所有输出重新定向到文件
> 文件内容将会被覆盖
set -C 禁止将内容覆盖已有文件,但可以追加
1> | file 强制覆盖
set +C 允许覆盖
>> 在原有内容基础上,追加内容
-
2> 覆盖重定向错误输出数据流
-
2>> 追加重定向错误输出数据流
-
标准输出和标准错误输出各自定向至不同位置:
COMMAND > /path/to/file.out 2> /path/to/error.out -
合并标准输出和错误输出为同一个数据流进行重定向
&> 覆盖重定向
&>> 追加重定向
COMMAND > /path/to/file.out 2>&1
(顺序很重要)
COMMAND >> /path/to/file.out 2>&1
-
合并多个程序的STDOUT
(cal 2007;cal 2008) > all.txt
命令执行过程视图:
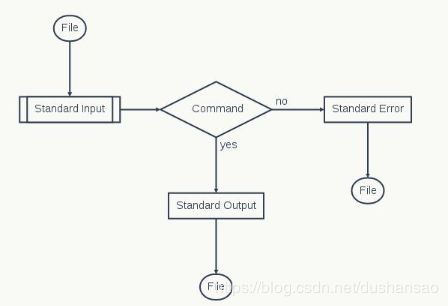
示例:
[root@Redhat7 data]# ls /home/ > file
[root@Redhat7 data]# cat file
td
[root@Redhat7 data]# ls /home/xsifuew 2> file
[root@Redhat7 data]# cat file
ls: cannot access /home/xsifuew: No such file or directory
[root@Redhat7 data]# ls /home/xsifuew 1> file 2>&1
[root@Redhat7 data]# cat file
ls: cannot access /home/xsifuew: No such file or directory
单行重定向:[root@CentOS8 data]# cat > ./file.txt
abc
def
xyz
多行重定向:[root@CentOS8 data]# cat > ./filetwo.txt <<开始符
> abc
> def
> 结束符
开始符与结束符为相同字符
