MySQL系列-优化之分页查询
1.分页查询之前先按索引排序
我们经常会上一些小说网站看小说,他们总是会把最近更新了的小说放在最前面,也就是第一页,而很久没更新的就放在后面了。那么这样网站是如何实现的呢?我的猜想有一张小说表,表里面一个last_update表示最后更新字段,并且对这个字段建立了索引,按last_update从大到小排序之后再按需求的页面大小进行分页。
那为什么分页查询总是要排序呢?
由上面的例子可以看出,这个是需求导致的,而且还有效率因素。下面举例说明:

表的描述如下:

只有id主键索引。
假设我们需要前三条数据,执行sql【explain select * from t1 limit 3;】

因为我们没有进行排序,mysql不知道要哪前三条,是id大呢,还name大呢?,mysql晕了,只能进行全表扫描来获取数据表的前三条数据了。所以范围类型为ALL。
当我们进行排序之后情况如何。执行sql【explain select * from t1 order by id desc limit 3;】

可以看到,查询类型为索引扫描,但是rows字段显示我们最多访问三条数据,所以sql效率挺高。当然,前提是我们的排序用上了相关的索引,否则的话偷鸡不成蚀把米,弄出一个using filesort。
2.千万别使用offset
为什么不能使用limit的offset?
其实offset是对我们偏移的数据进行遍历,我们偏移多少mysql就遍历多少,如果一个offset=1000000,那这条sql就至少要扫描1000000条数据了。
执行sql【explain select * from t1 order by id desc limit 3 offset 15;】

可以看到,访问类型依然是索引扫描,但是rows却变成了18,比之前的3可大多了。
所以千万别用offset,我们可以使用查询来筛选出需要的字段,比如:
可以把上面的sql转化为【select * from t1 where id<=5 and id>=3 order by id desc limit 3】

可以看出查出的数据完全一样,那么下面的sql效率如何呢?
执行sql【explain select * from t1 where id<=5 and id>=3 order by id desc limit 3;】

优化非常明显,访问类型变成了range,rows变成了3。
3.实现上一页和下一页
一般来说我们会弄一个javabean记录查询信息,比如说,当前页数,id最大值,id最小值,需要到的页数。
假设当前页面大小为3,页面id最大值为17,最小值为15。
除了上面第二节讲的让id在一个范围内查询的方法,我们也可以使用下面的方法。
那么下一页就是【select * from t1 where id<15 order by id desc limit 3;】

虽然rows为14,但并不会扫描这么多,得到3条就停,因为rows是一个最大估计值。
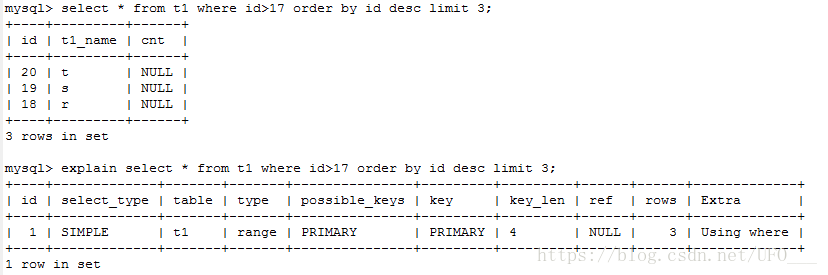
上一页就是【select * from t1 where id>17 order by id desc limit 3;】
4.如何实现跳页功能
有时需要进行手动输入页数,比如直接从第1页跳到666页,对于实现跳页功能这个就必须要获取整张表到底有多少数据行了。但是又不能 count(*) 的代价过大,因为mysql必须要全扫描来统计行数,那么 count(*) 如何优化呢?这里就不再重复讲解了,可以参考我的这篇文章【MySQL系列-优化之count()】。
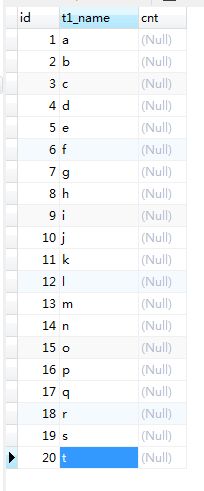
ok,假设你已经看了我的 count() 优化的文章,同时数据表变成了这样。

下面在继续分析。
因为我们是按id从大到小进行排序,所以为了实现跳页,我们必须知道用户当前在第几页,以及页面的大小。假设用户现在在第5页,页面大小为3,那么页面的最小值为20-3*5+1=6,页面最大值为6+3-1=8。如果现在用户想去第2页,第二页的页面最小值为20-2*3+1=15,页面最大值为15+3-1=17。那么sql就很容易可以写来。
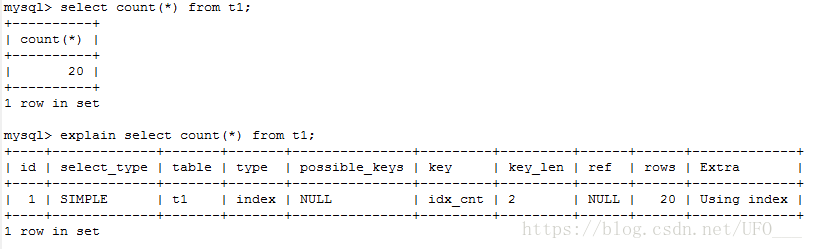
第一步获取总数【select count(*) from t1;】
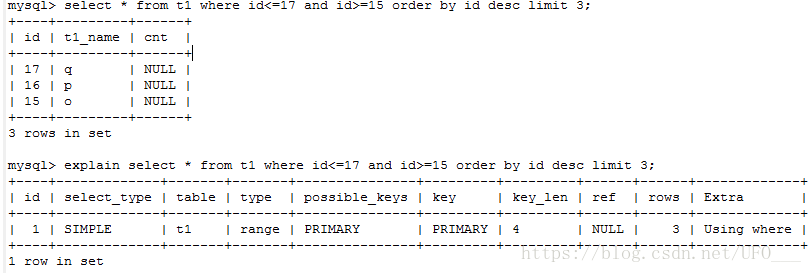
第二步执行需求页面的查询【select * from t1 where id<=17 and id>=15 order by id desc limit 3;】
当然也可以写成一个嵌套子查询。
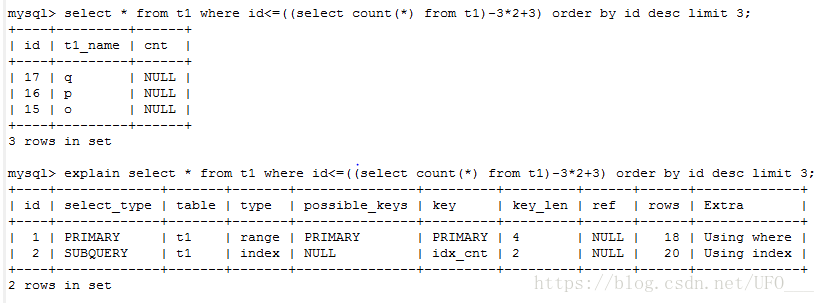
5.一些困惑
当用户在跳页查询的时候有数据插入咋办?直接进行锁表吗。
如果id不是连续而是中间有缺值呢?很多网站是没有提供跳页功能,但是应该有更高级的方法来实现,比如建立复杂的数据结构来维护之类的。