Elasticsearch 常见问题汇总及解决姿势(后续会持续更新)
1、集群存储资源高水位 异常
Caused by: org.elasticsearch.ElasticsearchStatusException: Elasticsearch exception [type=cluster_block_exception, reason=blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];]
at org.elasticsearch.rest.BytesRestResponse.errorFromXContent(BytesRestResponse.java:177)
at org.elasticsearch.client.RestHighLevelClient.parseEntity(RestHighLevelClient.java:653)
at org.elasticsearch.client.RestHighLevelClient.parseResponseException(RestHighLevelClient.java:628)
at org.elasticsearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:535)
at org.elasticsearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:508)
at org.elasticsearch.client.RestHighLevelClient.index(RestHighLevelClient.java:348)
at com.cy.es.connection.ClientProxy.index(ClientProxy.java:118)
at com.cy.es.connection.CyESClient.index(CyESClient.java:91)
at 当Elasticsearch集群中有节点挂掉,我们可以去查看集群的日志信息查找错误,不过在查找错误日志之前,我们可以通过elasticsearch的cat api简单判断下各个节点的状态,包括磁盘,heap,ram的使用情况,先做初步判断。
查看集群资源使用情况
get /_cat/nodes?v&h=http,version,jdk,disk.total,disk.used,disk.avail,disk.used_percent,heap.current,heap.percent,heap.max,ram.current,ram.percent,ram.max,master eg:
localhost:9200/_cat/nodes?v&h=http,version,jdk,disk.total,disk.used,disk.avail,disk.used_percent,heap.current,heap.percent,heap.max,ram.current,ram.percent,ram.max,master 返回:
http version jdk disk.total disk.used disk.avail disk.used_percent heap.current heap.percent heap.max ram.current ram.percent ram.max master
10.0.0.4:9200 6.3.1 1.8.0_181 29gb 3.3gb 25.6gb 11.72 254mb 7 3.3gb 6.2gb 92 6.8gb -
10.0.0.5:9200 6.3.1 1.8.0_181 29gb 3.3gb 25.6gb 11.71 195.5mb 5 3.3gb 6.2gb 91 6.8gb -
10.0.0.6:9200 6.3.1 1.8.0_181 29gb 3.4gb 25.6gb 11.74 293.6mb 8 3.3gb 6.2gb 92 6.8gb *此处的disk占用,heap使用量等都是监测集群状态的关键参数,更多参数可以官网cat node api参考此处。
需要手动扩容或者删除没必要数据;集群正常后,需要对指定索引执行如下命令
PUT /index/_settings
{
"index.blocks.read_only_allow_delete": null
}全部索引:
PUT /*/_settings
{
"index.blocks.read_only_allow_delete": null
}
全部索引:
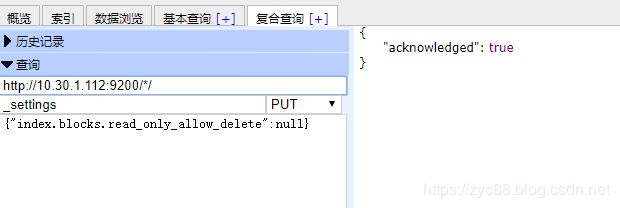
指定索引:

2、系统资源配置问题
问题:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
1. 修改配置sysctl.conf
sudo vi /etc/sysctl.conf
添加如下配置:
vm.max_map_count=655360
执行命令:
sudo sysctl -p
重新启动elasticsearch,即可启动成功。
=====================================================
问题:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] 原因:普通用户执行问题
解决:切换到root用户,编辑
/etc/security/limits.conf 添加,重启永久生效
# (elasticsearch 是用户名)
elasticsearch hard nofile 65536
elasticsearch soft nofile 65536
=====================================================
问题:
max number of threads [1024] for user [elk] is too low, increase to at least [2048]原因:普通用户执行操作数低
解决:切换到root用户,进入limits.d目录下修改配置文件。
vi /etc/security/limits.d/90-nproc.conf修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 2048或者
切换到root用户,编辑limits.conf 添加类似如下内容
vi /etc/security/limits.conf添加如下内容:(针对所有用户生效)
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096要重新登录生效